This is an implementation of a neighbor-based matrix decomposition recommendations engine using Yelp's mrjob package to run the program on Amazon's Elastic MapReduce.
Install Python packages Yelp's mrjob package and NumPy.
build_matrix.py will read in a directory, build the initial ratings matrix, and create predicted ratings that can be output to the terminal.
mr_job_recommendations.py will load:
dictionary of movie ratings - (Key: (movie_id, user_id), Value: rating)
dictionary of movies and users who have rated each movie, used to build neighborhoods - (Key: movie_id, Value: list of users who have rated that movie)
The map function places movies into neighborhoods and the reduce function produced predicted ratings through matrix decomposition. Yelp's mrjob package has great documentation and can be configured to Hadoop and Amazon EMR jobs.
Within the Python files, you can also set the following inputs to affect the accuracy of the algorithm, and the impact of these parameters are discussed in more detail below:
K : the number of latent features
iterations : the maximum number of iterations toward optimization
alpha : the learning rate (rate at which vectors in P and Q are incremented toward existing ratings)
beta : the regularization parameter (prevents overfitting)
build_matrix.py - functions that read in data files, produce neighborhoods, performs matrix decomposition, and creates predictive ratings matrix.
mr_job_recommendations.py - program that runs the matrix decomposition as a MapReduce job using Yelp's MRjob package
build_test_data.py - program that builds files in the same format as the Netflix data to produce practice datasets
netflix_local_data - Reduced datasets in the same format as the data provided by Netflix. The first line of every file is the movie_id, and each line thereafter is in the format "user_id,rating,date"
movie_ratings_dictionary_NLD, movies_and_users_who_rated_NLD - Dictionaries from the local data that cna be loaded in the mr_job_recommendations.py file to run the MapReduce job locally
In 2006, Netflix announced an open competition for the best collaborative filtering algorithm to predict user ratings for films based solely on previous ratings. Netflix provided a dataset of 480,189 users, 17,770 movies, and 100,480,507 ratings.
How does one calculate predicted ratings for each (movie, user) pair from a very sparse seed dataset?
Neighbor-based Matrix Decomposition
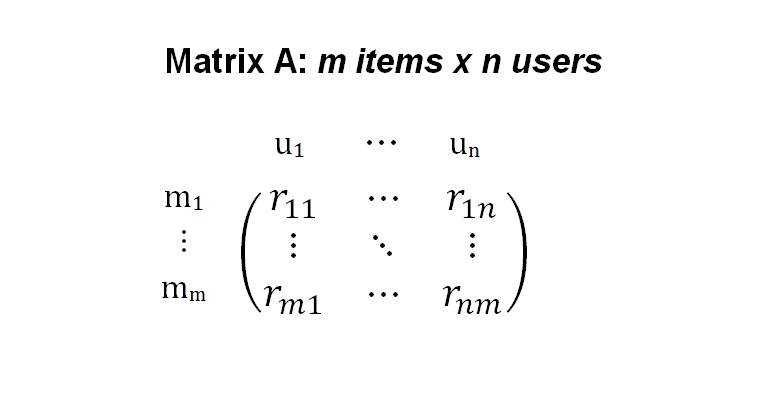

Two factor matrices are generated and the dot-product of the vectors from the factor matrices are checked against the existing ratings and tweaked until the error between the dot-products is very small. More information the Incremental Matrix Factorization technique can be found here
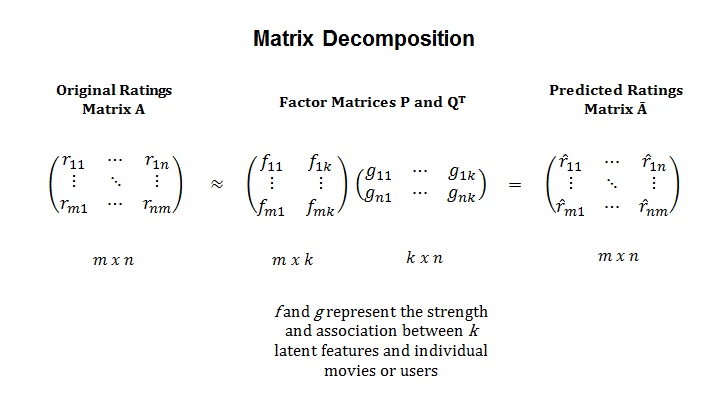
Once the factor matrices are built, the product results in the predicted ratings matrix.
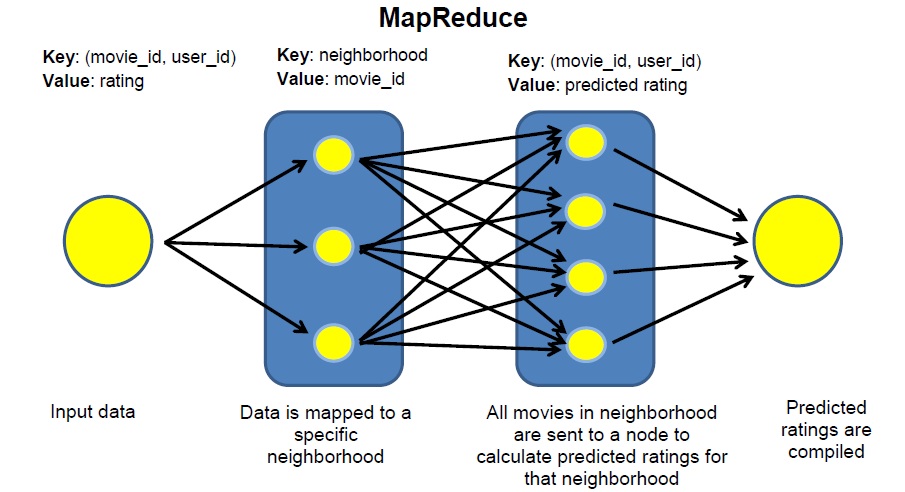
Because of the size of the dataset, one can distribute computing on a Hadoop cluster. I divided the dataset into neighborhoods and used Yelp's mrjob package and Amazon's Elastic MapReduce.

Movies were divided into neighborhoods by the number of common users who had rated those movies in the mapping step. The reducing step performs the matrix decomposition on the neighborhood.
Sources
Matrix Factorization Techniques for Recommender Systems
PyCon 2011: mrjob: Distributed Computing for Everyone
Matrix Factorization: A Simple Tutorial and Implementation in Python
Using Linear Algebra for Intelligent Information Retrieval
Incremental Matrix Factorization for Collaborative Filtering
[Large-scale Parallel Collaborative Filtering for the Netflix Prize] (http://www.hpl.hp.com/personal/Robert_Schreiber/papers/2008%20AAIM%20Netflix/netflix_aaim08(submitted).pdf)
Incremental Singular Value Decomposition Algorithms for Highly Scaleable Recommender Systems
Instructors and Mentors
[Dr. J] (http://www.amazon.com/Probing-supersymmetry-cosmogenic-neutrinos-Uscinski/dp/1244944467)
Anusha Rajan
Daniel Malmer
Gowri Grewal