Clearly explained guide for running quantized open-source LLM applications on CPUs using LLama 2, C Transformers, GGML, and LangChain
Step-by-step guide on TowardsDataScience: https://towardsdatascience.com/running-llama-2-on-cpu-inference-for-document-q-a-3d636037a3d8
- Third-party commercial large language model (LLM) providers like OpenAI's GPT4 have democratized LLM use via simple API calls.
- However, there are instances where teams would require self-managed or private model deployment for reasons like data privacy and residency rules.
- The proliferation of open-source LLMs has opened up a vast range of options for us, thus reducing our reliance on these third-party providers.
- When we host open-source LLMs locally on-premise or in the cloud, the dedicated compute capacity becomes a key issue. While GPU instances may seem the obvious choice, the costs can easily skyrocket beyond budget.
- In this project, we will discover how to run quantized versions of open-source LLMs on local CPU inference for document question-and-answer (Q&A).
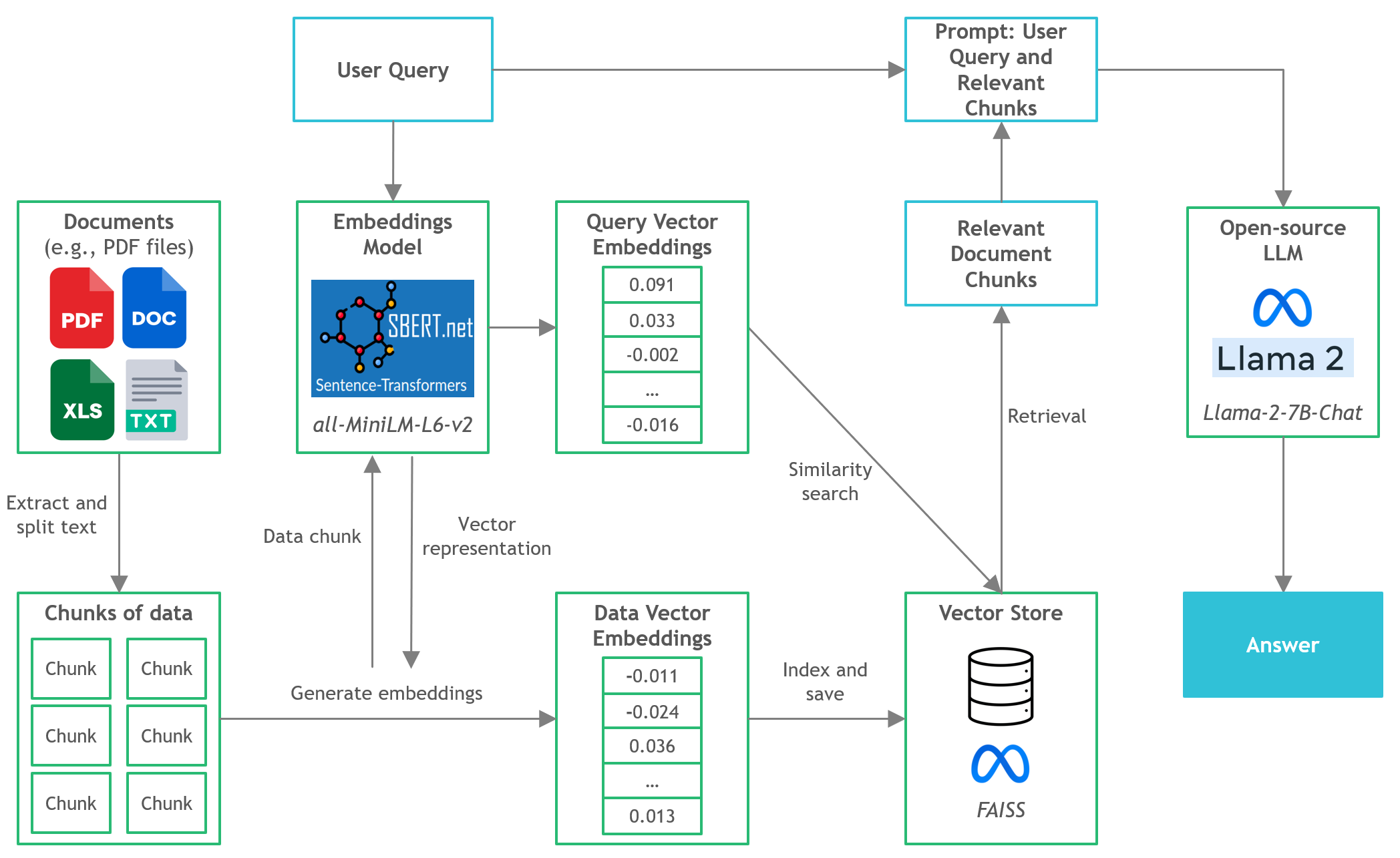

- Ensure you have downloaded the GGML binary file from https://huggingface.co/TheBloke/Llama-2-7B-Chat-GGML and placed it into the
models/folder - To start parsing user queries into the application, launch the terminal from the project directory and run the following command:
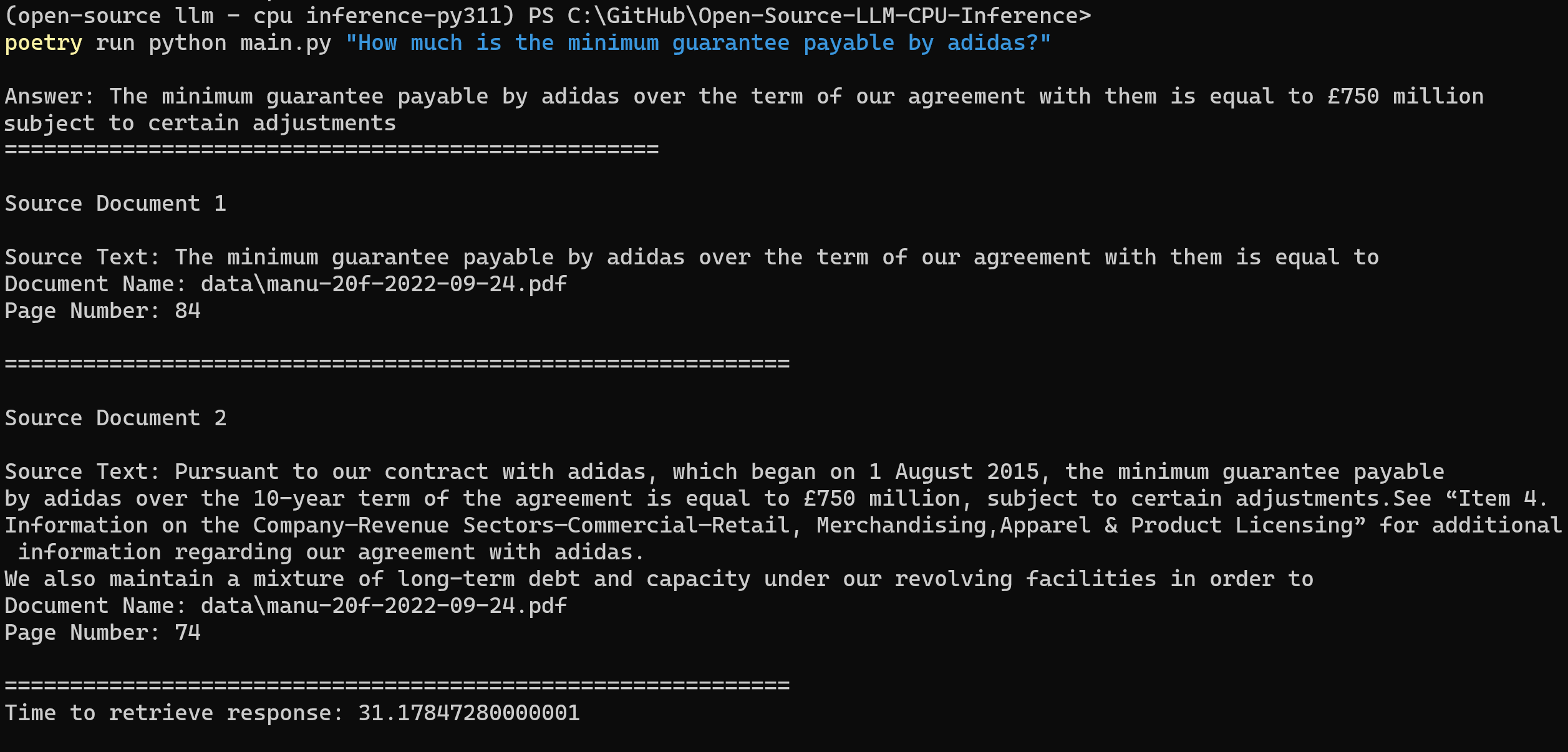
poetry run python main.py "<user query>" - For example,
poetry run python main.py "What is the minimum guarantee payable by Adidas?" - Note: Omit the prepended
poetry runif you are NOT using Poetry

- LangChain: Framework for developing applications powered by language models
- C Transformers: Python bindings for the Transformer models implemented in C/C++ using GGML library
- FAISS: Open-source library for efficient similarity search and clustering of dense vectors.
- Sentence-Transformers (all-MiniLM-L6-v2): Open-source pre-trained transformer model for embedding text to a 384-dimensional dense vector space for tasks like clustering or semantic search.
- Llama-2-7B-Chat: Open-source fine-tuned Llama 2 model designed for chat dialogue. Leverages publicly available instruction datasets and over 1 million human annotations.
- Poetry: Tool for dependency management and Python packaging
/assets: Images relevant to the project/config: Configuration files for LLM application/data: Dataset used for this project (i.e., Manchester United FC 2022 Annual Report - 177-page PDF document)/models: Binary file of GGML quantized LLM model (i.e., Llama-2-7B-Chat)/src: Python codes of key components of LLM application, namelyllm.py,utils.py, andprompts.py/vectorstore: FAISS vector store for documentsdb_build.py: Python script to ingest dataset and generate FAISS vector storemain.py: Main Python script to launch the application and to pass user query via command linepyproject.toml: TOML file to specify which versions of the dependencies used (Poetry)requirements.txt: List of Python dependencies (and version)
- https://github.com/marella/ctransformers
- https://huggingface.co/TheBloke
- https://huggingface.co/TheBloke/Llama-2-7B-Chat-GGML
- https://python.langchain.com/en/latest/integrations/ctransformers.html
- https://python.langchain.com/en/latest/modules/models/llms/integrations/ctransformers.html
- https://python.langchain.com/docs/ecosystem/integrations/ctransformers
- https://ggml.ai
- https://github.com/rustformers/llm/blob/main/crates/ggml/README.md
- https://www.mdpi.com/2189676