####Table of Contents
- Overview - What is the scenario node terminus?
- Hiera Primer - Understanding the model
- Data Descriptions - What are the data types?
- Installation - The basics of getting started
- Command Line Debugging Tools
- Getting Required User Configuration
- Implementation - An under-the-hood peek at what the module is doing
This module allow users to specify a data layer that lives on top of Puppet and allows an additional level of flexibility to deployments.
Is was designed to compose a set of core Puppet modules into multiple deployment permutations (or reference architectures) called scenarios while requiring as little duplicate code as possible.
Although it was originally designed with the Openstack modules in mind, it has a great potential to be leveraged outside of that project.
Understanding hiera as well the Puppet's data binding system available in 3.x are crucial for understanding this model.
This model borrows heavily from both hiera concepts as well as its internal APIs.
To summarize
Hiera + data bindings - Provides a data lookup system for class parameters that is decoupled from how those classes are added to Puppet.
For example, if I define the following class:
class foo($var) {
...
}
It could be included anywhere as:
include foo
Puppet's data bindings provide hooks that are called when the catalog is compiled that call an individual method to look up the value of each class parameter. For the example above, this would result in a lookup of foo::var.
Hiera provides the capability to use hierarchical overrides in order to determine what the value of each piece of data is.
Hiera uses a set of known global variables, referred to as a scope, to determine the value of each class parameter. For the typical hiera use case, the scope consists of the facts retrieved for a machine.
The way in which those variables effect the final value of an individual piece of data is driven by the hierarchy specified in Hiera's configuration file.
Given the following hierarchy from hiera.yaml:
---
:hierarchy:
- "hostname/%{hostname}"
- user
- "osfamily/%{osfamily}"
- "db/%{db_type}"
- "scenario/%{scenario}"
- common
Hiera searches a set of files for data values that match a specific key. The data files that it searches are determined by interpolating each of these specified hierarchies using the current scope (or set of global variables).
Assume the following:
-
data will be searched from : /etc/puppet/data/hiera_data
-
hiera.yaml defines the following hierarchy:
--- :hierarchy: - "hostname/%{hostname}" - user - "osfamily/%{osfamily}" - "db/%{db_type}" - "scenario/%{scenario}" - common -
The following global variables are passed to hiera as its scope:
osfamily: redhat scenario: all_in_one hostname: my_host.domain.name
When hiera searches for a specified key, it will do the following:
- Use the hierarchy from hiera.yaml together with its scope to build out the list of files to search for the desired key.
- /etc/puppet/data/hiera_data/hostname/my_host.domain.name.yaml
- /etc/puppet/data/hiera_data/user.yaml
- /etc/puppet/data/hiera_data/osfamily/redhat.yaml
- /etc/puppet/data/hiera_data/scenario/all_in_one.yaml
- /etc/puppet/data/hiera_data/common.yaml
NOTE: In this example, the db_type hierarchy omitted from the hierarchy because there is no global variable set for db_type.
- Search those files in the same order as they are provided in hiera.yaml. This order also implies their lookup precedence. The first value that hiera finds in the hierarchy is returned as the value for that variable.
For example, the value from my_host.domain.name.yaml will always be used if available.
Any values from user.yaml are used if the host specific file does not exist.
Sometimes the value returned form a hiera value lookup is not a static string, or array, but a variable that should be interpolated from the current set of global variables.
Using the same globals set in the previous section, if the value for variable2 is derived as "%{scenario}"
The value for that key would be all_in_one
The data model uses Hiera style hierarchical overrides to look up a user's deployment data.
These overrides are used to determine more than just values for class parameters. The following types of data are resolved via hierarchical lookups.
- what global data should be used to process data values
- what roles exist as a part of the current deployment model
- what classes should be applied as a part of a role
- what value should be provided for a given class parameter
In fact, the data model is composed of the following parts that are processed in this order:
- global hiera data
- scenario
- data mappings
- hiera data
The following image shows both the processing order of each data type and the global variables used to determine how its hierarchy is processed.
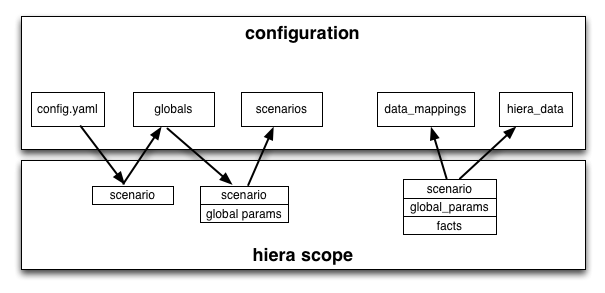
Here is the upstream documentation for hiera and data bindings
This model provides a data layer that sits above your Puppet manifests.
This data layer can be used instead of composition manifests and roles/profiles.
The data layer is processed into a list of classes as well as data_bindings that should be used to configure a node's class parameters.
Config.yaml is used to store the deployment scenario currently in use.
It contains a single configuration:
scenario: scenario_name
- scenario is used to select the specific references architecture that you wish to deploy. Its value is used to select the roles for that specific deployment model from the file: scenarios/.yaml. If you are using this project for CD, scenario is also used to select the set of nodes that will be provisioned for your deployment. Scenario is also passed to Puppet as a global variable and used to drive both interpolation as well as category selection in hiera.
NOTE: config.yaml also currently contains some data that is used by a separate provisioning system. It is likely that scenario will be defined in it's own configuration file.
The following command returns the current scenario:
puppet scenario get_scenario
The global_hiera_params directory is used to specify the global variables that can be used to effect the hierarchical overrides that will be used to determine both the classes contained in a scenario roles as well as the hiera overrides for both data mappings and the regular yaml hierarchy.
To get a better understanding of what global are and how they interact with hiera, check out the following sections from this README:
The selection of the global_hiera_params is driven by hiera using whatever hierarchy is configured in your hiera.yaml file.
At least the following hierarchy is recommended for overrides of your globals:
- user
- "scenario/%{scenario}"
- common
The scope used for this lookup only contains the scenario key.
Given the above hierarchy, the following files would be used to resolve your globals.
- global_hiera_params/user.yaml - users can provide their own global overrides in this file.
- global_hiera_params/scenario/%{scenario}.yaml - Default values specific to a scenario are loaded from here (they override values from common.yaml)
- global_hiera_params/common.yaml - Default values for globals are located here.
These variables are used by hiera to determine both what classes are included as a part of the role lookup, and are also used to drive the hierarchical lookups of data both by effecting the configuration files that are consulted (like the scenario specific config file from above)).
The following diagram show how the global configuration effects other hierarchical overrides:
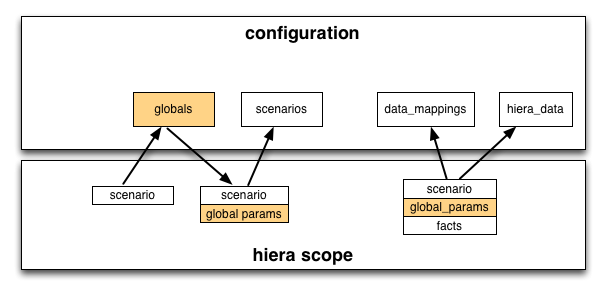
Globals are required by almost every subcommand of the puppet scenario
command. To see how globals are compiled, and what the current values are,
run commands that require globals with --debug.
Scenarios are used to describe the roles that should be deployed as a part of a reference architecture as well as the classes that are used to configure those roles.
The following config snippet shows how a scenario specifies multiple roles and assigns them classes:
scenarios:
roles:
role1:
classes:
- class_one
role2:
classes
- class_two
Scenarios are constructed by compiling hierarchies in your scenarios data directory.
Each of the roles for a specific scenario is specified in its scenario files:
- scenarios/user.yaml - users can provide their own global overrides in this file.
- scenarios/%{scenario_name}.yaml - Default values for a specific scenario are loaded from here.
- scenarios/common.yaml - Default roles that can be applied to all scenarios can be found here.
You can also insert custom hierarchies based on hiera_global_params to customize the way that roles can be overridden.
NOTE: Currently, this operation expects "scenarios/%{scenario}" to exist in your hierarchy, but automatically modifies it to lookup scenarios/scenario_name.yaml instead of scenarios/scenarios/scenario_name.yaml.
The following subcommands are useful for debugging scenarios:
- Show the list of all classes for a given role
- Show a list of all available roles
- Compile all classes and data for a role
Class groups are a set of classes that can be referenced by a single identifier. Class groups are used to store combinations of classes for reuse.
For example, if several classes are required to build out a role called nova compute, then its class group might look like this:
data/class_groups/nova_compute.yaml
classes:
- nova
- nova::compute
- "nova::compute::%{compute_type}"
- "nova::network::%{network_service}"
- "nova::compute::%{network_service}"
- "%{network_service}"
- "%{network_service}::agents::%{network_plugin}"
class_groups:
- base
Three things to note here:
- The nova_compute class group contains a list of classes that comprise nova_compute
- Some of the classes use the hiera syntax for variable interpolation to set the names of classes used to the values provided from the hiera_global_params.
- Class groups can themselves can contain class groups.
The puppet scenario get_class_group command can be used to debug class groups.
role_mappings are used to map a Puppet certificate name to a specific roles from your selected scenario.
The following example shows how to map a certname of controller-server to a role of controller:
controller-server: controller
The certificate name in Puppet defaults to a systems hostname, but can be overridden from the command line using the --certname option. The following command could be used to convert a node into a controller.
puppet agent --certname controller-server
It the provided certificate, contains a domain name, it will try to match it's role against the shortened version of that name.
For example:
foo.bar.com
would try to match
- foo.bar.com
- foo.bar
- foo
TODO: the role mappings do not currently support regex, but probably needs to
The data model uses two sets of data in order to resolve the value for class parameters, data mappings and hiera data.
Data mappings are used to express the way in which global variables from hiera can map to one or many class parameters.
Previously, this could be done with parameter forwarding in parameterized classes, or by making explicit hiera calls.
The example below, shows how parameterized class forwarding could be used to indicate that a single value called verbose should be used to set the verbose setting of multiple classes.
class openstack::controller(
$verbose = false
) {
class { 'nova': verbose => $verbose }
class { 'glance': verbose => $verbose }
class { 'keystone': verbose => $verbose }
class { 'cinder': verbose => $verbose }
class { 'quantum': verbose => $verbose }
}
This is pretty concise way to express how a single data value assigns multiple class parameters. The problem is, that it uses the parameterized class declaration syntax to forward this data, meaning that it is hard to reuse this code if you want to provider different settings. Any attempt to specify any of these composed classes will result in a class duplication error in Puppet.
The same configuration above can be expressed with the data_mappings as follows:
verbose:
- nova::verbose
- glance::verbose
- keystone::verbose
- cinder::verbose
- quantum::verbose
For each of those variables, the data-binding will call out to hiera when the classes are processed (if they are included)
NOTE: another goal of the data mappings is to allow users to specify all data that should be configured by an end user. This is more of an experimental feature. More information on utilizing this can be found here.
Hiera data is used to express what values are going to be used to configure the roles of your scenarios.
Hiera data is used to either express global keys (that were mapped to class parameters in the data mappings), or fully qualified class parameter namespaces.
NOTE: Class parameters explicitly specified using hiera_data override its setting through data bindings. In our previous example, explicitly setting
nova::verbose: truewould override whatever verbose is set to.
- install this module
- If you plan to use this from a puppet master, you must synchronize it's plug-ins
- configure puppet.conf
/etc/puppet/puppet.conf
[master]
node_terminus=scenario
- configure your hiera backend
/etc/puppet/hiera.yaml
---
:backends:
- data_mapper
:hierarchy:
- "hostname/%{hostname}"
- "client/%{clientcert}"
- user
- user.%{scenario}
- user.common
- global/${global_hiera_param}
- common
This module also comes with a collection of tools that can be used for debugging:
All of these utilities are implemented as a Puppet Face. To see the available commands, run:
puppet help scenario
or to learn about an individual command:
puppet help scenario get_classes
The data model exists outside of Puppet and is forwarded to Puppet using a node terminus interface.
It currently supports several commands that can be used to pre-generate parts of the data model for debugging purposes:
Returns the currently configured scenario:
puppet scenario get_scenario
Returns the list of roles for the current scenario along with their classes.
puppet scenario get_roles
To retrieve the list of classes that are associated with a role:
puppet scenario get_classes <ROLE_NAME> --render-as yaml
To retrieve the list of classes together with their specified data:
puppet scenario compile_role <ROLE_NAME> --render-as yaml
This command is very similar to how Puppet interacts with the scenario based data model.
Retrieves the set of classes currently included in a class group.
puppet scenario get_class_group <class_group_name>
Another use case of the data model is to generate data that can be compiled to a list of configuration options available to an end user.
In this model, the data_mappings are used to not only express the way that a single key can populate multiple class parameters, it also is used to signify all of the keys that should be exposed to an end user as a part of the basic configuraiton.
The following command can be used to provide a list of all data that a user may want to configure in their hiera_data/user.yaml
puppet scenario get_user_inputs
This command takes the current scenario and global settings into account and produces a list of the configuration settings a user may want to adjust along with their default values.
It also accepts --role, if you only want to get the settings that are applicable to a specific role.
puppet scenario get_user_inputs --role=build-server
NOTE: this is still a prototype and is not fully functional
The following command can be used to supply user configuration data to build out an example model:
puppet scenario setup_scenario_data
It will prompt users for tons of questions related to how to configure their specified deployment scenario.
This folder contains data that is used to express openstack deployment as data.
Technically, it is implemented as a custom hiera backend, and an external node classifier (more specfically, as a custom node terminus, but for our purposes here, they can be considered as the same thing)
It is critical to understand the following in order to understand this model: