


It's a useful utils to simplify Linux network troubleshooting and performance tuning, developed in order to help Carbon Reductor techsupport and automate the whole linux performance tuning process out of box (ok, except the best RSS layout detection with multiple network devices). These utils may be useful for datacenters and internet service providers with heavy network workload (you probably wouldn't see an effect at your desktop computer). It's now in production usage with 2000+ deployment and save us a lot of time with hardware and software settings debugging. Inspired by packagecloud's blog post.
You'll need pip.
pip install netutils-linuxCheck this guide about usage.
All these top-like utils don't require root priveledges or sudo usage. So you can install and use them as non-priveledged user if you care about security.
pip install --user netutils-linuxBrief explanation about highlighting colors for CPU and device groups: green and red are for NUMA-nodes, blue and yellow for CPU sockets. Screenshots are taken from different hosts with different hardware.
Most useful util in this repo that includes almost all linux network stack performance metrics and allow to monitor interrupts, soft interrupts, network processing statistic for devices and CPUs. Based on following files:
- /proc/interrupts (vectors with small amount of irqs/second are hidden by default)
- /proc/net/softnet_stat - packet distribution and errors/squeeze rate between CPUs.
- /proc/softirqs (only NET_RX and NET_TX values).
- /sys/class/net/<NET_DEVICE>/statistic/<METRIC> files (you can specify units, mbits are default)

There are also separate utils if you want to look at only specific metrics: irqtop, softirq-top, softnet-stat-top, link-rate.
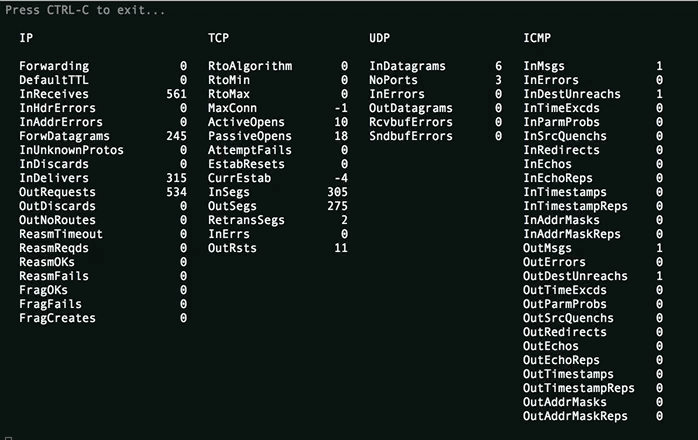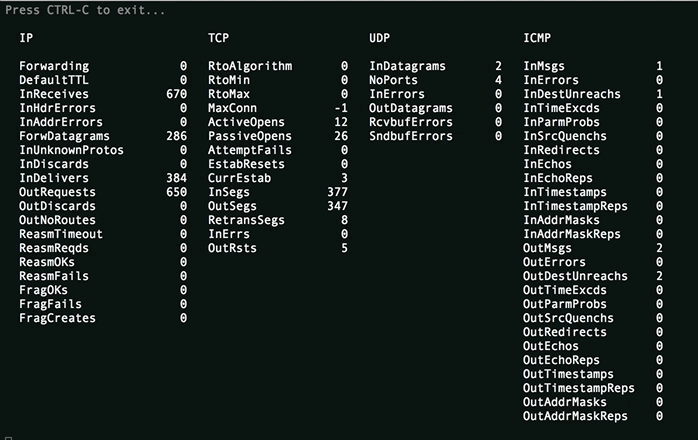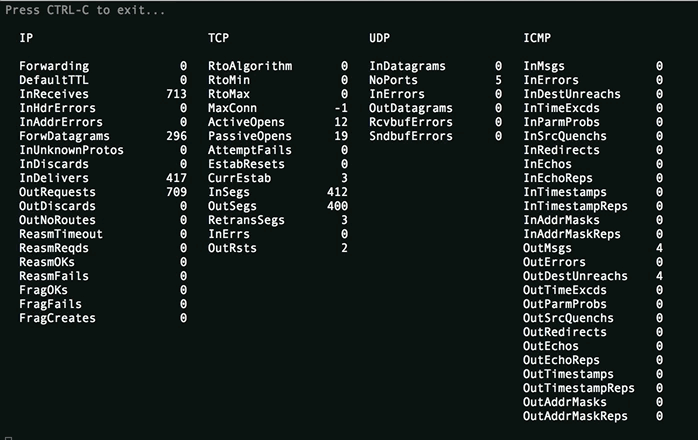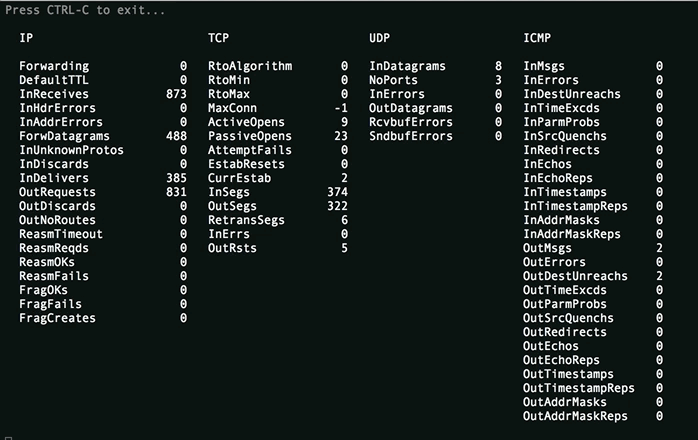
Basic /proc/net/smmp file watcher.
Automatically set smp_affinity_list for IRQ of NIC rx/tx queues that usually work on CPU0 out of the box).
Based on lscpu's output.
It also supports double/quad ladder in case of multiprocessor systems (but you better explicitly specify queue count == core per socket as NIC's driver's param). Example output:
# rss-ladder eth1 0 - distributing interrupts of eth1 (-TxRx-) on socket 0 - eth1: irq 67 eth1-TxRx-0 -> 0 - eth1: irq 68 eth1-TxRx-1 -> 1 - eth1: irq 69 eth1-TxRx-2 -> 2 - eth1: irq 70 eth1-TxRx-3 -> 3 - eth1: irq 71 eth1-TxRx-4 -> 8 - eth1: irq 72 eth1-TxRx-5 -> 9 - eth1: irq 73 eth1-TxRx-6 -> 10 - eth1: irq 74 eth1-TxRx-7 -> 11
Enables RPS on all available CPUs of NUMA node local for the NIC for all NIC's rx queues. It may be good for small servers with cheap network cards. You also can explicitely pass --cpus or --cpu-mask. Example output:
# autorps eth0 Using mask 'fc0' for eth0-rx-0.
Sets every CPU scaling governor mode to performance and set max scaling value for min scaling value. So you will be able to use all power of your processor (useful for latency sensible systems).
rx-buffers-increase utils, that finds and sets compromise-value between avoiding dropped/missing pkts and keeping a latency low.
Example output:
# ethtool -g eth1 Ring parameters for eth1: Pre-set maximums: RX: 4096 ... Current hardware settings: RX: 256 # rx-buffers-increase eth1 run: ethtool -G eth1 rx 2048 # rx-buffers-increase eth1 eth1's rx ring buffer already has fine size. # ethtool -g eth1 Ring parameters for eth1: Pre-set maximums: RX: 4096 ... Current hardware settings: RX: 2048
Much alike lshw but designed for network processing role of server.
➜ vscale-vm git:(folding) ✗ server-info --show
cpu:
info:
Architecture: x86_64
BogoMIPS: 4399
Byte Order: Little Endian
CPU MHz: 2199
CPU family: 6
CPU op-mode(s): 32-bit, 64-bit
CPU(s): 1
Core(s) per socket: 1
Flags: fpu vme de pse tsc msr pae mce cx8 apic sep mtrr pge mca cmov pat pse36
clflush mmx fxsr sse sse2 ss syscall nx pdpe1gb rdtscp lm constant_tsc arch_perfmon
rep_good nopl eagerfpu pni pclmulqdq vmx ssse3 fma cx16 pcid sse4_1 sse4_2 x2apic
movbe popcnt tsc_deadline_timer aes xsave avx f16c rdrand hypervisor lahf_lm
abm 3dnowprefetch tpr_shadow vnmi flexpriority ept vpid fsgsbase tsc_adjust
bmi1 hle avx2 smep bmi2 erms invpcid rtm rdseed adx smap xsaveopt arat
Hypervisor vendor: KVM
L1d cache: 32K
L1i cache: 32K
L2 cache: 256K
L3 cache: 25600K
Model: 79
Model name: Intel(R) Xeon(R) CPU E5-2630 v4 @ 2.20GHz
NUMA node(s): 1
NUMA node0 CPU(s): 0
On-line CPU(s) list: 0
Socket(s): 1
Stepping: 1
Thread(s) per core: 1
Vendor ID: GenuineIntel
Virtualization: VT-x
Virtualization type: full
layout:
'0': '0'
disk:
vda:
model: null
size: 21474836480
type: HDD
memory:
devices:
'0x1100':
size: '512'
speed: 0
type: RAM
size:
MemFree: 78272
MemTotal: 500196
SwapFree: 0
SwapTotal: 0
net:
eth0:
buffers:
cur: 256
max: 256
conf:
ip: ''
vlan: false
driver:
driver: virtio_net
version: 1.0.0
queues:
own: []
rx: []
rxtx: []
shared: []
tx: []
unknown: []➜ vscale-vm git:(folding) ✗ server-info --rate --server
server: 1.7666666666666664➜ vscale-vm git:(folding) ✗ server-info --rate --subsystem
cpu: 4.5
disk: 1.0
memory: 1.0
net: 1.3333333333333333
system: 1.0➜ vscale-vm git:(folding) ✗ server-info --rate --device
cpu:
BogoMIPS: 2
CPU MHz: 2
CPU(s): 1
Core(s) per socket: 1
L3 cache: 9
Socket(s): 1
Thread(s) per core: 10
Vendor ID: 10
disk:
vda: 1.0
memory:
devices:
'0x1100': 1.0
size: 1.0
net:
eth0: 1.3333333333333333
system:
Hypervisor vendor: 1
Virtualization type: 1➜ vscale-vm git:(folding) ✗ server-info --rate
cpu:
BogoMIPS: 2
CPU MHz: 2
CPU(s): 1
Core(s) per socket: 1
L3 cache: 9
Socket(s): 1
Thread(s) per core: 10
Vendor ID: 10
disk:
vda:
size: 1
type: 1
memory:
devices:
'0x1100':
size: 1
speed: 1
type: 1
size:
MemTotal: 1
SwapTotal: 1
net:
eth0:
buffers:
cur: 1
max: 1
driver: 2
queues: 1
system:
Hypervisor vendor: 1
Virtualization type: 1Q: I see that workload is distributed fine, but there is a lot of workload. How to go deeper, how to understand what my system doing right now?
A: Try
perf topAny help is welcome. Just comment an issue with "I want to help, how can I solve this issue?" to start.