[2024-05-25] TempCompass Leaderboard is available on HuggingFace Space 🤗.
[2024-05-16] 🎊🎊🎊 TempCompass is accepted at ACL 2024 Findings!
[2024-04-14] Evaluation result of Gemini-1.5-pro, the current SOTA Video LLM, is add.
[2024-03-23] The answer prompt is improved to better guide Video LLMs to follow the desired answer formats. The evaluation code now provides an option to disable the use of ChatGPT.
[2024-03-12] 🔥🔥🔥 The evaluation code is released now! Feel free to evaluate your own Video LLMs.
- TempCompass encompasses a diverse set of temporal aspects (left) and task formats (right) to comprehensively evaluate the temporal perception capability of Video LLMs.
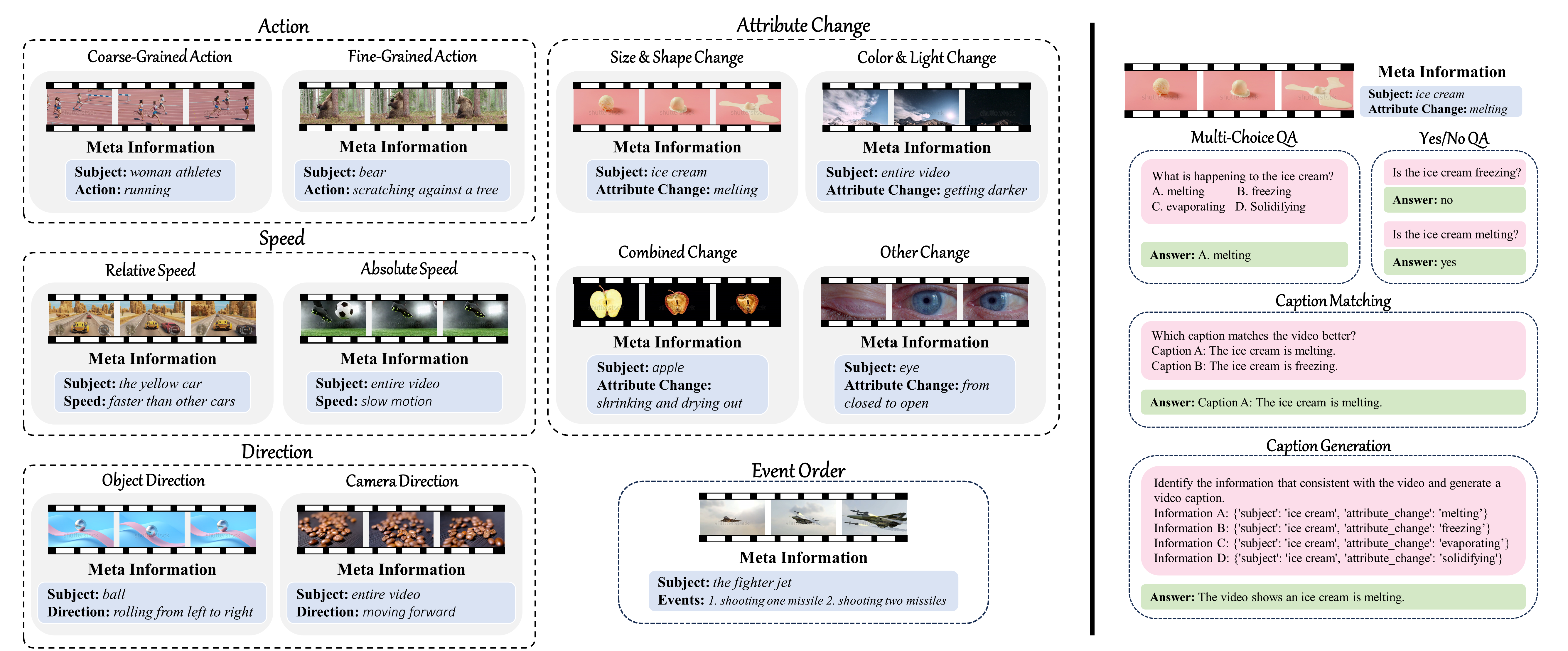

-
We construct conflicting videos to prevent the models from taking advantage of single-frame bias and language priors.
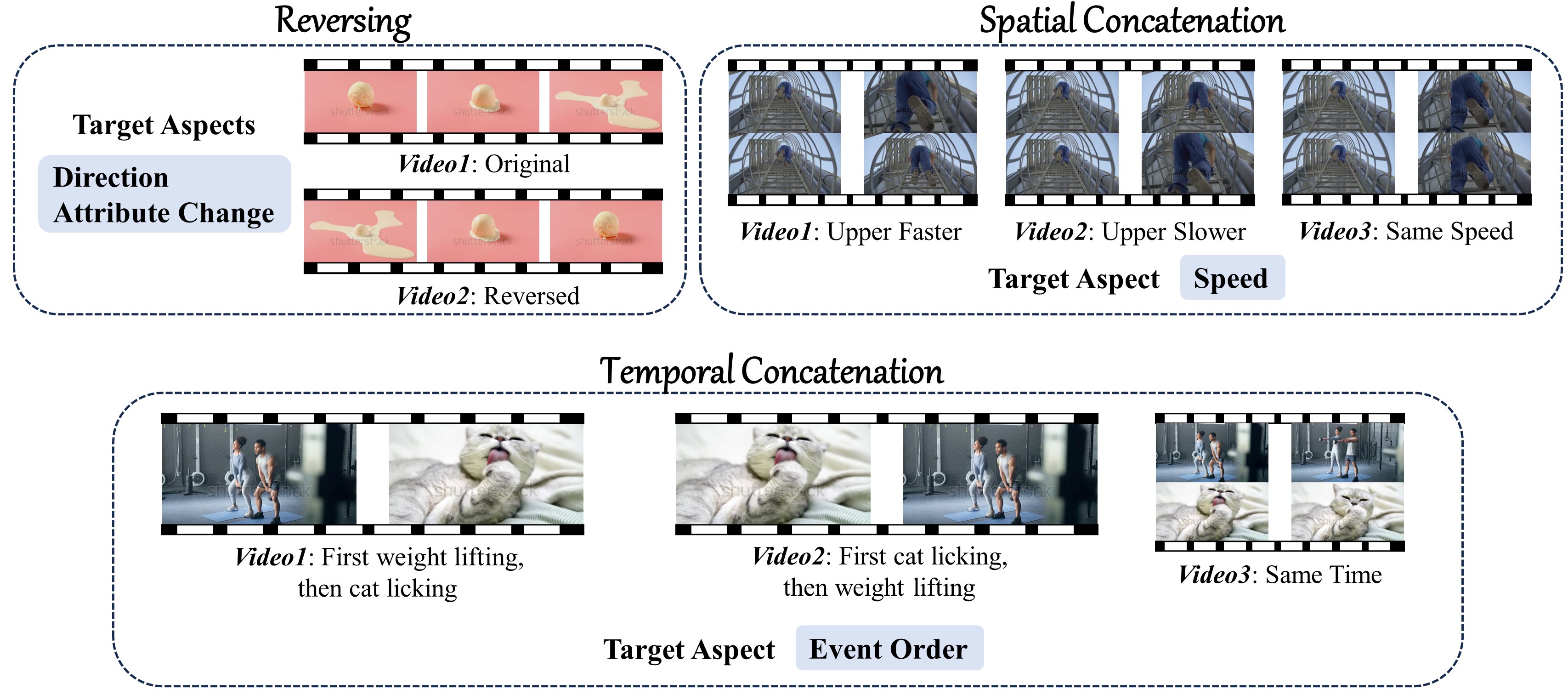
-
🤔 Can your Video LLM correctly answer the following question for both two videos?


What is happening in the video?
A. A person drops down the pineapple
B. A person pushes forward the pineapple
C. A person rotates the pineapple
D. A person picks up the pineapple



To begin with, clone this repository and install some packages:
git clone https://github.com/llyx97/TempCompass.git
cd TempCompass
pip install -r requirements.txt1. Task Instructions
The task instructions can be found in questions/.
Task Instruction Generation Procedure
-
Generate Multi-Choice QA instructions (
question_gen.py). -
Manually validate quality and rectify.
-
Generate task instructions for Yes/No QA (
question_gen_yes_no.py), Caption Matching (question_gen_caption_match.py) and Caption Generation (question_gen_captioning.py), based on manually rectified Multi-Choice QA instructions. -
Manually validate quality and rectify.
2. Videos
Run the following commands. The videos will be saved to videos/.
cd utils
python download_video.py # Download raw videos
python process_videos.py # Construct conflicting videosWe use Video-LLaVA and Gemini as examples to illustrate how to conduct MLLM inference on our benchmark.
1. Video-LLaVA
Enter run_video_llava and install the environment as instructed.
Then run the following commands. The prediction results will be saved to predictions/video-llava/<task_type>.
# select <task_type> from multi-choice, yes_no, caption_matching, captioning
python inference_dataset.py --task_type <task_type>2. Gemini
The inference script for gemini-1.5-pro is run_gemini.ipynb. It is recommended to run the script in Google Colab.
After obtaining the MLLM predictions, run the following commands to conduct automatic evaluation. Remember to set your own $OPENAI_API_KEY in utils/eval_utils.py.
-
Multi-Choice QA
python eval_multi_choice.py --video_llm video-llava -
Yes/No QA
python eval_yes_no.py --video_llm video-llava -
Caption Matching
python eval_caption_matching.py --video_llm video-llava -
Caption Generation
python eval_captioning.py --video_llm video-llava
Tip👉: Except for Caption Generation, you can set --disable_llm when running the scripts, which will disable chatgpt-based evaluation (i.e., entirely rely on rule-based evaluation). This is useful when you do not want to use ChatGPT API and your MLLM is good at following the instruction to generate answers of specific format.
The results of each data point will be saved to auto_eval_results/video-llava/<task_type>.json and the overall results on each temporal aspect will be printed out as follows:
{'action': 76.0, 'direction': 35.2, 'speed': 35.6, 'order': 37.7, 'attribute_change': 41.0, 'avg': 45.6}
{'fine-grained action': 58.8, 'coarse-grained action': 90.3, 'object motion': 36.2, 'camera motion': 32.6, 'absolute speed': 47.6, 'relative speed': 28.0, 'order': 37.7, 'color & light change': 43.6, 'size & shape change': 39.4, 'combined change': 41.7, 'other change': 38.9}
Match Success Rate=100.0

The following figures present results of Video-LLaVA, VideoChat2, SPHINX-v2, Gemini-1.5-pro and the random baseline. Results of more Video LLMs and Image LLMs can be found in our paper.




We update the answer prompt for Multi-Choice QA and Caption Matching, from "Best Option:" to "Please directly give the best option:", which can better encourage MLLMs to directly select an option. As such, we can reduce the reliance on ChatGPT API, if an MLLM is good at following the instruction.
The success rate of rule-based matching is as follows:
Multi-Choice QA
| V-LLaVA | SPHINX-v2 | LLaMA-VID | Qwen-VL-Chat | PandaGPT | Valley | |
|---|---|---|---|---|---|---|
| old prompt | 37.9 | 99.6 | 62.9 | 46.8 | 6.4 | 3.5 |
| new prompt | 100 | 100 | 97.0 | 98.5 | 3.9 | 0.4 |
Caption Matching
| V-LLaVA | SPHINX-v2 | LLaMA-VID | Qwen-VL-Chat | PandaGPT | Valley | |
|---|---|---|---|---|---|---|
| old prompt | 76.6 | 89.3 | 44.5 | 91.6 | 30.7 | 11.2 |
| new prompt | 99.5 | 99.5 | 68.3 | 96.0 | 22.5 | 3.7 |
- Upload scripts to collect and process videos.
- Upload the code for automatic evaluation.
- Upload the code for task instruction generation.
@article{liu2024tempcompass,
title = {TempCompass: Do Video LLMs Really Understand Videos?},
author = {Yuanxin Liu and Shicheng Li and Yi Liu and Yuxiang Wang and Shuhuai Ren and Lei Li and Sishuo Chen and Xu Sun and Lu Hou},
year = {2024},
journal = {arXiv preprint arXiv: 2403.00476}
}