| Name | Role | |
|---|---|---|
| Karla Saur | Mentor | |
| Jesús Camacho Rodríguez | Mentor | |
| Anna Pavlenko | Mentor | |
| Brian Kroth | Mentor | |
| Yingzhe(Danny) Dong | Developer | yzdong99@bu.edu |
| Richard(Rui) Wei | Developer | rickwei@bu.edu |
| Haocheng Zhao | Developer | zhaohc@bu.edu |
| Jinquan Pan | Developer | vin3nt@bu.edu |
| Jingwei Zhang | Developer | jwz16@bu.edu |
- Presentation recording (password: h$7wCE!B)
- Demo recording
This project is intended to enable Kata Container on Spark + YARN and perform necessary performance benchmarks and security tests, eventually we will be able to deliver a solution for deploying a Spark + YARN cluster with the Kata Container enabled and provide insights based on the performance and security analysis. The main users will be those security-sensitive users such as enterprises, government departments etc.
Nowadays, Spark workloads can be managed by YARN and each Spark job can be run in a Containerized Spark Executor. However, using traditional container technologies can expose many security vulnerabilities since all containers share the same Linux kernel. Which means the kernel is the single point of failure, once the Linux kernel has any security vulnerabilities, attackers can easily perform attacks to all the Spark Executors.
In addition to 0-day vulnerabilities, normally there are lots of challenges to keep the Linux kernel security up-to-date, examples:
- Kernel security patches may take time.
- Users may not want to apply the newest security patches due to many reasons (e.g. they may be afraid of breaking the current workloads environment).
Kata Container provides a new way to create isolated containers with more security features. Each Kata Container is a lightweight VM with a traditional container included and workloads are all run in an isolated environment, even though one kernel . However there could be performance loss when using Kata Container since a lightweight VM is still a VM, the overhead is inevitable but may be mitigable.
Therefore, the goals of our project are:
- Deploy two Spark + YARN clusters with Kata and Docker Container enabled respectively.
- Write scripts to perform essential performance benchmarks and security tests against both Kata Container and Docker Container configurations. Deliver a detailed report.
- Explore solutions to mitigate performance impact that comes from VM. (virtio-fs)
We have encountered a challenge in this project: Spark Executor binding issue in Docker Bridge Network, Root Cause Analysis.
-
Background and Role: Robert works in the IT department of a government agency, ensuring the security and efficiency of data processing tasks. The agency deals with confidential information, making security paramount.
-
Needs and Goals: Robert needs a secure and efficient way to run Spark jobs using YARN. He is interested in exploring Kata Container solutions to enhance security and is open to mitigating any potential performance impacts.
-
Challenges: Government agencies can be slow to adopt new technologies. Robert must ensure that any solution is thoroughly vetted for security and performance.
-
Background and Role: Sarah is a systems administrator for a large enterprise, responsible for managing big data processing environments. Security is a top priority due to the sensitive nature of the data handled by the company.
-
Needs and Goals: Sarah is looking for a solution that will allow her to securely manage Spark workloads using YARN, without compromising performance. She needs insights into performance benchmarks and security features to make informed decisions.
-
Challenges: Balancing security and performance is challenging. Sarah is often cautious about applying new security patches for fear of affecting the workloads environment.
-
Background and Role: Ricky is a data scientist working in a security-sensitive field, such as healthcare or finance. He frequently runs large-scale data processing tasks using Spark.
-
Needs and Goals: Ricky requires a secure environment for running Spark workloads on YARN. He is interested in the project’s performance benchmarks and security analysis to assess the suitability of the Kata Container solution for his work.
-
Challenges: Ricky needs to ensure data integrity and confidentiality while maintaining optimal performance for data processing tasks.
Enable Spark+Yarn to seamlessly integrate with Kata Containers or an equivalent secure container runtime.Configure and test the integration to ensure compatibility and stability within the Spark ecosystem.
Enable secure multi-tenant Spark deployments, allowing multiple customers or users to share the same host while maintaining isolation and security.
Benchmark the performance of Spark workloads running in secure containers compared to a baseline scenario where Spark runs on containers within the same cluster. Investigate and mitigate any performance bottlenecks introduced by the security measures. Specifically, evaluate the impact of enabling virtio-fs and work on optimizing data movement in and out of containers.
Define a comprehensive threat model for multi-tenant Spark deployments and outline potential security risks. Implement robust security measures within Kata Containers to enhance the security of Spark workloads. Demonstrate how these security improvements mitigate common attack vectors and maintain data and code isolation between tenants.
If applicable, contribute the configurations, modifications, and best practices developed during the project back to the open-source community.
Create detailed documentation covering configurations, deployment procedures, security enhancements, and performance optimization steps.
- Infrastructure Layer:
- A cluster setup, possibly in a cloud environment or just VMs
- Nodes in this cluster should have the necessary components installed to support Kata containers (like hypervisors)
- Cluster Management Layer:
- YARN: Configured to manage cluster resources and to use Kata containers for task execution. YARN will be responsible for allocating resources, starting/stopping containers, and monitoring.
- Container Runtime Layer:
- Kata Containers: YARN will spin up Kata containers to run Spark tasks. Each Kata container is effectively a lightweight VM providing stronger isolation between concurrent tasks. (Optionally, integrate virtio-fs with Kata for better filesystem performance)
- Application Layer:
- Spark: Spark applications will submit tasks for execution. Instead of running directly on cluster nodes or inside traditional containers, these tasks run inside Kata containers managed by YARN.
- Monitoring & Performance Measurement Tools:
- Tools to monitor resource usage, task execution times, etc (not decided)., for both traditional and Kata containers.
- Benchmarking tools (maybe like TPC-H or TPC-C) to measure the performance of Spark when running inside Kata containers.
- Security Analysis Tools:
- Tools to demonstrate and assess potential vulnerabilities in a non-Kata setup and how they're addressed in a Kata setup.

- A Spark application is submitted for execution on the cluster
- Spark communicates with YARN to request resources for its tasks
- YARN spins up Kata containers for Spark tasks
- Spark tasks execute inside these Kata containers
- Results are returned to the Spark application once processing is complete
graph TD
subgraph Infrastructure Layer
A[Cluster] --> B[Nodes with Kata Support]
end
subgraph Cluster Management Layer
Y[YARN]
end
subgraph Container Layer
K[Kata Containers with optional virtio-fs]
end
subgraph Application Layer
S[Spark]
end
B -->|Supports| K
S -->|Submit tasks| Y
Y -->|Allocate Resources| A
Y -->|Manage| K
K -->|Execute| S
style A fill:#f9d,stroke:#333,stroke-width:2px
style Y fill:#afd,stroke:#333,stroke-width:2px
style K fill:#daf,stroke:#333,stroke-width:2px
style S fill:#ffa,stroke:#333,stroke-width:2px
Below is the diagram showing our final solution, the details will be explained in the following passages.

This diagram is showing the solution for the Spark cluster mode. For the client mode which the Spark Driver will be running at the client's side instead of inside the Application Master, we can directly use Kata container runtime and the bridge network for AM. For more information and differences between two modes, please refer to Submitting Applications - Spark 3.5.0 Documentation (apache.org)
To run Spark application on Hadoop YARN with Docker containers (RunC / Kata), we need to deploy the Hadoop cluster, use deploy_hadoop.sh can easily auto-deploy the required components. Usage of deploy_hadoop.sh
If you want manually set the cluster, please refer to the playbook

The easiest and most doable way to implement that is not to touch the yarn source code but try to run Kata using Docker. To make a easy explanation, you can have a look at the figure. So when the user, in our case is the linux container executor in the node, sends a request to create a container. Firstly the request will be parsed and processed by docker engine, then docker engine calls the containerd, which is a high-level container runtime and is used as the container manager in docker. After that, the containerd sets up the low level container runtime, which is RunC by default, through shim apis. And Kata is natively supported to do that. Well in short terms, we can simply use docker to run kata by replacing runc which we already did.
Another solution is launching applications directly in Kata. As our mentor mentioned, the ideal way to do that is to put Kata out of the box, which is much more complicated. This required us to implement some runtime classes under yarn like runc did (following the OCI standards), which will require us to look deeper at the interfaces of Linux Container Executor, and which we don't have enough time to do.
Spark application examples (run with Kata)
The Spark Pi test does not involve data shuffling. However, if you want to launch a more complex application which requires data transfer between different executors, the default shuffling service for spark won't work. The default Spark shuffling service will establish an RPC endpoint inside the containers and let them directly do shuffling read and write. This apparently can not be applied to containers in bridge network as containers on different nodes cannot directly talk to each other.
To solve this, we introduced an external shuffle service for spark which runs in the node manager process instead inside of the containers. For more information about this part, please refer to the Playbook.md.
In our solution for the cluster mode, the biggest concern is that the Application Master is still running on the host using the default RunC, while the executors are isolated in different Kata containers. For that part, there could be two potential solutions in the future.
- Overlay network (docker swarm)
- Application Master can run within the overlay network together with executors
- All containers are reachable from each other, which also solved the shuffling issue and the Spark's own shuffling can work

-
Hadoop YARN Service Registry
- Hadoop can do auto port-mapping for bridge network, it will randomly map those ports to the host
- The Service Registry have a manchanism like a routing table to record endpoints (which ports in containers correspond to which on the host)
- And when a request comes in, it can direct the request to the correct container
Sadly didn’t find any useful information proves that Spark supports this… (Apache Storm and some other frameworks already supported this) But this looks like the most reasonable native solution.
-
Choice of Kata Containers:
- Implication: Incorporating Kata Containers introduces an added layer of complexity in setup and operation compared to traditional containers. However, the trade-off is a significantly enhanced security posture.
- Reasoning: The goal to securely run multi-tenant Spark workloads demands a solution that offers stronger isolation than standard containers. Kata Containers strike a balance between the agility of containers and the isolation of VMs.
-
Performance Benchmarking:
Environment setup Bare metal machine cluster
Number of nodes: 4 OS: ubuntu 22.4
Socket(s): 2 Core(s) per socket: 10 Thread per core: 2
Memory: 251 Gi Swap: 8Gi
Turbo Boost: Running Frequency scaling: Disabled
-
Microbenchmarks(check docs/petf/micro_benchmark/README)
-
I/O
-
Storage
-
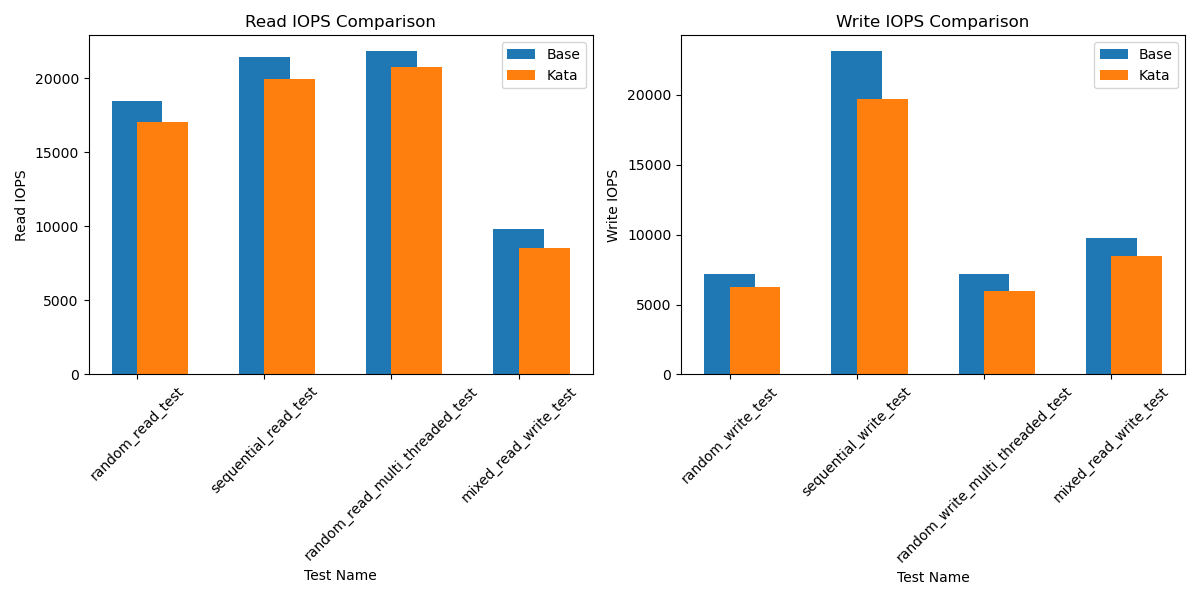
use
fiofor two types of tests:-
IOPS (e.g., 4K random read/writes)
-
BW (e.g., sequential read and sequential write of large files with large block size)
-
-
-
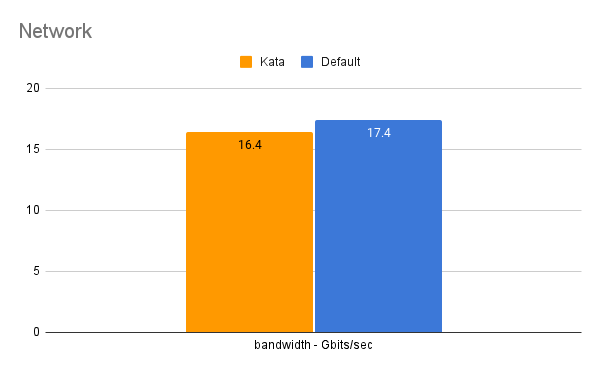
Networking
-
use
iperf3to measure-
TCP bandwidth
-
UDP latency (e.g., packets per second, tail latency like P95)
-
-
-
-
Memory bandwidth, memory allocation (stresses virtual memory subsystem), CPU performance
- Can use
stress-ngfor this, there are several tests available there (e.g., matrix multiple for CPU, memory bandwidth, vmem allocator, etc.)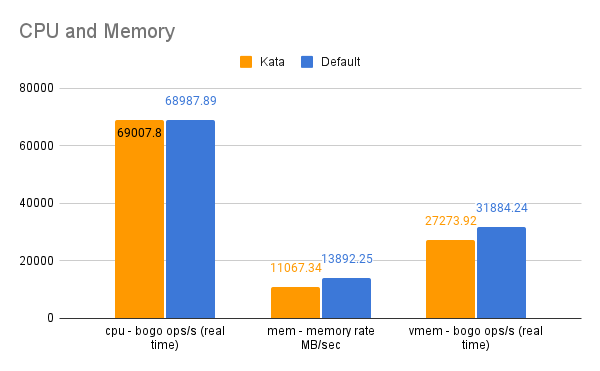
- Can use
-



Each test should compare:
- Docker container performance
- Kata container performance
| Success Criteria | Status | Related files | Notes |
|---|---|---|---|
| Stable Intergration | In progress | Script files will update later | No critical errors or crashes |
| Data Movement Efficiency | Not started | Script files will update later | Acgueve desired data transfer speed with virtio-fs |
| Performance Parity | In progress | Script files will update later | Compare with standard Spark on containers |
| Multi-tenant Resillience | Not started | Script files will update later | Support multiple users without issues |
| Security Valdation | Not started | Script files will update later | Kata fortified again vulnerabilities |
| Documentation and Contribution | In progress | Github repo & documentation | Ensure comprehensive documentation and open-source contributions |
| Postitive Feedback | Not started | Github repo & documentation | Gather feedback from mentors and participants |
| Learing Assessment | In progress | Github repo & documentation | Participants should understand key project areas. |
So after the discussion with our mentors, we set the current system structure of our MVP as the diagram shown below:

At the end we finished the first method we've mentioned before, which is keep Kata running in Docker by simply replacing the runtime of Docker from RunC to Kata. Additionally, we also enabled the cluster mode for Spark in our system and introduced an external shuffle service to transfer data across different bridge networks.

| Releasing Date (expected) | Releasing Content | Description |
|---|---|---|
| 09/22 | Design Document | This README.md doc |
| 10/01 | A Baseline system: Spark on Yarn running in clusters | |
| 10/15 | A simple microbenchmark for baseline | |
| 10/25 | A yarn configuration file and any other related files for deploy spark on yarn in Kata containers | Note that this may not be doable due to many reasons. We will try other secured container runtime if Kata does not work out. What we can do right now is just explore all methods that could possibly work with Kata. |
| 11/22 | Performance Benchmark Result | |
| 12/01 | Security Assessment Result |
Note: All releasing dates are approximately estimated as mentors said it is very possible that we could meet some issues in setup first cluster and connect the Kata containers. All delays should not exceed one week.