I’m used to working in projects where the system receives tons of data (readings) from various environment sensors and then decide to act, depending on what it is receiving.
Since I have never worked with gRPC, I decided to create this project. The idea is simple: Use gRPC and create a basic system that could digest lots of environment sensor data at once (and scale out if necessary). The messages can be received, read and processed directly using a gRPC client or via the Flask API (which, in turn, use the gRPC client).
Some aspects of this project (like validation and what to do with the readings received) are quite generic, since the system is not grounded in any real world case. I plan on setting up a couple of sensors with an Arduino (or a Raspberry Pi) and make it send the readings to the API.
My programming language of choice. Easy to learn, fast to code and help is just a DuckDuckGo (or Google) search away.
In my opinion, Flask is way more flexible, easy to learn and lightweight than Django. Taking that in consideration, along with the scope of this project, it makes more sense to choose Flask over Django.
I've heard some great things about gRPC, but never tried it. As far as I researched it's a great option for a low latency, high scalability (language agnostic) solution. It adds a couple layers of complexity to the application (when we compare to not using any type of RPC at all), but I'm believing it is worth it, specially considering load balancing and application evolution.
Initially, I chose ZODB, so I could use an embedded, fast database. However, I started to notice some erratic behaviours
when doing bigger benchmark tests.
So I decided to give up on the embedded requirement from storage and went on to MongoDb, which is also fast, easy to
implement and scalable.
- Clients, services, private apis and other clients can access the gRPC endpoints.
- Meanwhile, a public API can be used (by a frontend or other third party applications), to make use of gRPC`s endpoint.
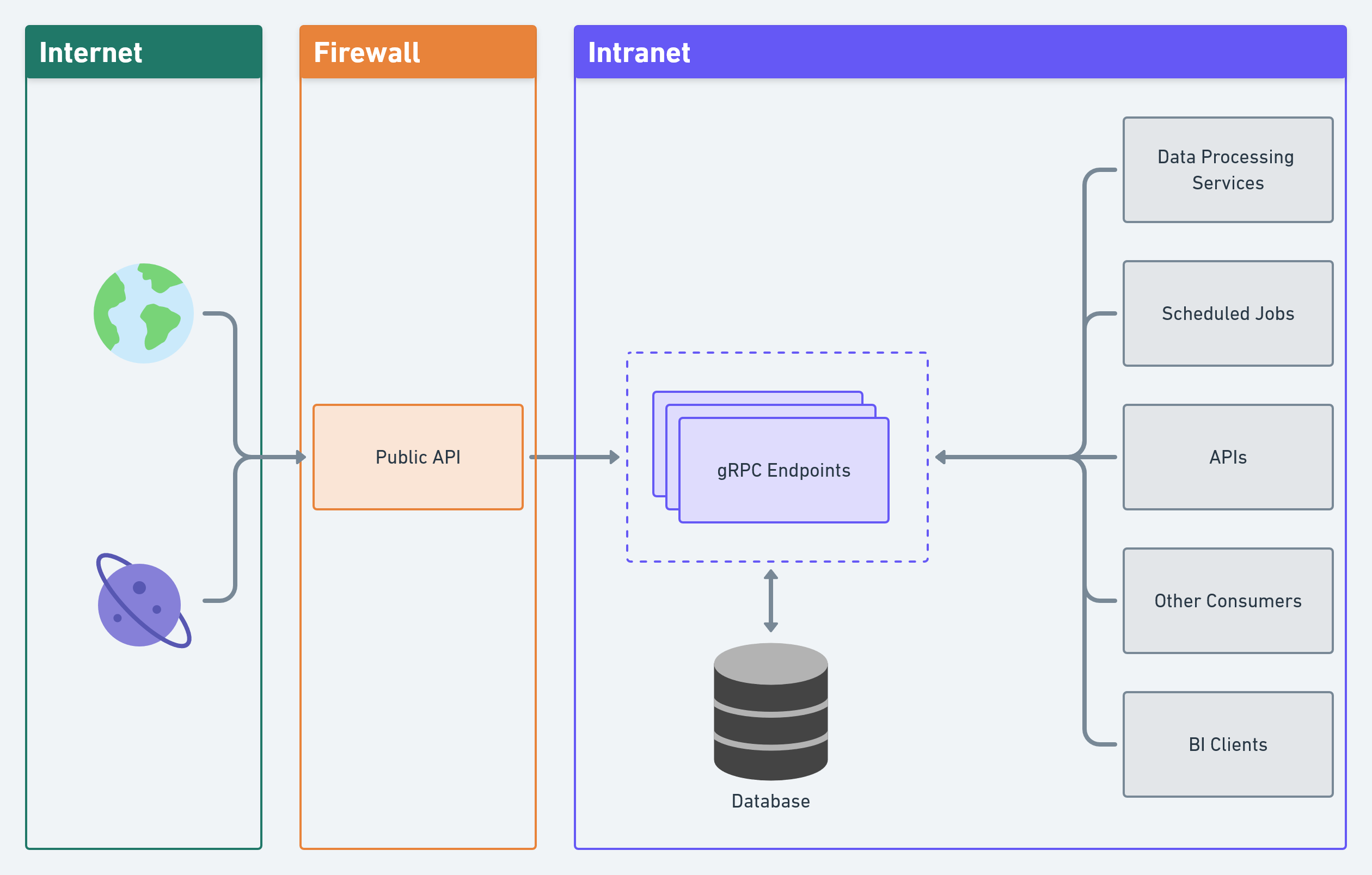

In its current state, this project has 3 entities:
- Location: Not all that useful. Not used for anything, really. Included because it makes sense, even in a basic setting for this type of thing.
- Sensor: Represents the physical sensor that's (hypothetically) sending environment readings.
- Sensor Reading: The actual reading from the sensor. Contains a lot of data.
The current version of Sensor Reading contains both the id of its sensor and the id of its location. Normally, the
reading would not have both, but I decided to include it, so I could make a few more validations on each reading.
Also, all entities have read-only properties and validation on setters, to make sure everything is has it should be.
Since this would really depend on the implementation of the API and since running Flask locally is not the best way to test simultaneous/parallel requests, I'll just focus the tests on direct calls to the server.
| Workers | Requests per Client | Total Requests | Elapsed Time | Cap: Req/Seconds | Cap: Req/Day |
|---|---|---|---|---|---|
| 1 | 10 | 10 | 0:00:00.636513 | 15 | 1.296.000 |
| 10 | 10 | 100 | 0:00:00.794216 | 125 | 10.800.000 |
| 10 | 100 | 1000 | 0:00:02.770565 | 360 | 31.104.000 |
| 50 | 200 | 10000 | 0:00:23.811725 | 420 | 36.288.000 |
| 100 | 100 | 10000 | 0:00:22.055141 | 453 | 39.139.200 |
| 200 | 50 | 10000 | 0:00:22.355107 | 447 | 38.620.800 |
| 1 | 10000 | 10000 | 0:00:51.448303 | 194 | 16.761.600 |
| 10000 | 1 | 10000 | 0:00:27.520348 | 363 | 31.363.200 |
Columns:
Workers: number of active workers making requests simultaneously.Requests per Client: number of requests each worker made.Total Requests: total number of requests processed.Elapsed Time: total elapsed time for the test.Cap: Req/Seconds: in the current workload, how many messages were processed each second.Cap: Req/Day: given this ratio of messages per client, how many messages could be processed each day.
| Workers | Requests per Client | Limit Results to | Total Fetched | Elapsed Time | Rows fetched/sec |
|---|---|---|---|---|---|
| 1 | 10 | 10000 | 100,000 | 0:00:11.031695 | 9090 |
| 10 | 10 | 10000 | 1,000,000 | 0:00:52.143278 | 19,230 |
| 10 | 100 | 10000 | 10,000,000 | 0:08:50.079260 | 18,867 |
| 10 | 100 | first | 1,000 | 0:00:01.490819 | 1,000 |
| 10 | 100 | last | 1,000 | 0:00:01.527391 | 1,000 |
| 10 | 100 | 100 newest | 100,000 | 0:00:07.041533 | 14,285 |
| 10 | 100 | 100 oldest | 1,000,000 | 0:00:07.155739 | 14,285 |
| 100 | 100 | 100 newest | 1,000,000 | 0:01:05.692690 | 15,384 |
| 100 | 100 | 100 oldest | 1,000,000 | 0:01:06.817975 | 15,151 |
| 100 | 1000 | first | 100,000 | 0:01:36.958435 | 1,041 |
| 100 | 1000 | last | 100,000 | 0:01:35.372245 | 1,052 |
| 100 | 1000 | single row, by id | 100,000 | 0:01:38.419700 | 1,020 |
| 1000 | 100 | single row, by id | 100,000 | 0:01:46.748245 | 943 |
| 10000 | 10 | single row, by id | 100,000 | 0:01:46.222926 | 943 |
Columns:
Workers: number of active workers making requests simultaneously.Requests per Client: number of requests each worker made.Limit Results to: if any, which limiter was applied to the fetch request.Total Fetched: considering all workers and all requests, the amount of rows that were fetched.Elapsed Time: total elapsed time for the test.Rows fetched/sec: considering the total fetched and elapsed time values, how many rows were fetched each second.
You use the current scripts:
run_server.py: starts the gRPC server. You should run this first.run_api.py: starts the flask API. You should run this afterrun_server.py, so it can connect to the server.run_client.py: sends random readings to the server and then fetches (and prints) all readingsrun_send_api_request.py: sends a post request to the API (good to make simple tests)run_print_sensors_and_locations.py: prints all sensors and locations available.run_playground.py: testing area. don't need to run it for anything.run_client_benchmark.py: runs a benchmark test. may need to configure the scenario.
- Lots of refactoring...
- Create flask interface (in progress)
- Standardize fetch base result to include item count and is_empty property
- Add swagger to flask interface
- Convert single use scripts to a commandline interface
- Add unit tests
- Add stress tests
After finishing TODO items 1, 2 and 3, I'll probably go look for a raspberry pi zero w and a couple of sensors, so I can start "Audrey II" project.