Introduction to Big Data
What launched the Big Data era?
- Data Science #1 catalyst for economical growth
- Big Data is a stream of data
- Cloud Computing = Computing on demand = dyanmic and scalable data analysis
Applications: What makes big data valuable
- Big Data -> Better Models -> Higher Precision
- Big Data has enabled personalized marketing
- Big Data has enabled personalized healthcare
Where Does Big Data Come From?
- Machines
- People
- Organizations
- Interactive visualization: http://lod-cloud.net/versions/2017-08-22/lod.svg
Machine-Generated Data: It's Everywhere and There's a Lot!
- Largest source of data
- Internet of Things
- Real time problem detection
- Customer Relations
- Fraud Detection
- System monitoring / control
- SCADA (Supervisory Control and Data Acquisition)
Big Data Generated By People: The Unstructured Challenge
- Unstructured data
- Huge growth in data
| Company | Data Processed Daily |
|---|---|
| eBay | 100PB |
| 100PB | |
| 30PB | |
| 100TB | |
| Spotify | 64TB |
Hadoop
- Handle big batches of distributed information
Spark / Apache Storm
- Real time processing
- Integrate with any database or store technology
Data Warehouse
- Datasource integration to one place
- Data gets extracted from different datasources and transformed and loaded in central database. This is called ETL
- Used for structured data
- Doesn't fit well with today's dynamic data world

Big Data pipeline

Organization-Generated Data: Structured but often siloed
-
Highly structured data
-
Data Silos (no 1 silo has access to all information)
-
Commercial Transaction
- Detect correlated products
- Estimate demand
- Capture Fraudulent Activity
-
Banking / Stock records
-
Credit Cards
-
E-Commerce
-
Medical Records
Commercial Transaction + Open Data + Analytics = Better predictions
Walmart
- Twitter data
- local events
- local weather
- in-store purchases
- online clicks
The Key: Integrating Diverse Data
Strucuted Data + Unstructured data + Price Optimization = Increased Revenue
Books about Price Optimization:
Data integration = Reduce data complexity + Increate Data availability + Unify your data system
Supply Chain Engineering: Useful Methods and Techniques
V's for Big Data

Volume
- Vasts amount of data
- Not just storage, we also need to be able to manage the data in a timely fashion. For processing, for instance.
- Exponential growth
Variety
- Structural variety
Formats and models
- Media variety
Medium in which data get delivered
- Semantic variety
How to interpret and operate on data
- Availability Variations
Real time / Intermittent
Velocity
-
Speed of generation and pace from A to B
-
Real time over Batch processing
Veracity
- Truthfullness and trustworthniness of data
- Quality
Valence
- How much the data is connected among it self
- The valence increases over time (social network)
Value
- How will Big Data benefit business
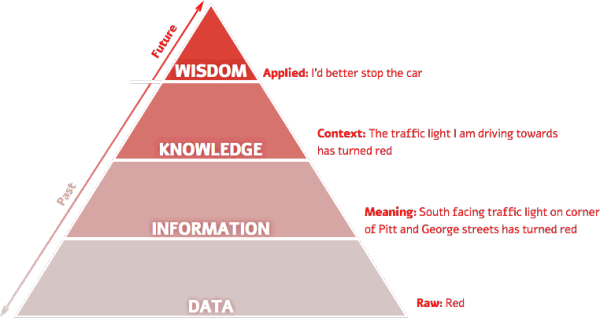
Data Science: Getting Value out of Big Data
- Induce information from observations
- Big Data + Analysis + Question = Insight
- Data Science is not static, models are constantly getting better and new questions arise with new insights and data



What Data Science is made of



Building a Big Data Strategy
- Aim
- High level goals
- What data to collect
- Maybe start with objectives and derive which data to get to reach them
- Must have support from company and stakeholders
- Policy
- Privacy and lifetime
- Curation and quality
- Interoperability and regulation
-
Plan
-
Action
P's of Data Science
- People
- Data Science team and project stakeholders
- Purpose
- Focus on the question, not the technology
- Process
- Process to iterate on, people can communicate and work together.
- Acquire -> Prepare -> Analyse -> Report -> Act
- Platforms
- Hadoop or other
- Programmability
- Reusable / Reproducable / Middleware
https://words.sdsc.edu/words-data-science/data-science
Asking the Right Questions
- Define the problem
- e.g. How can data be used to detect machine failure
- e.g. How can understand customer better to targeted marketing
-
Access the Situation and context
-
Define goal / success criteria
Steps in the Data Science Process
- Acquire data
- Finding data
- Retrieve data
- Query data
- Prepare
- Explore data
- Pre process
- Explore data
- Look the data
- Understand nature of data
- Preliminary analysis
- Pre-process
- Clean
- Integrate
- Package into format
- Analyse Data
- Choose analytical approach
- Build models
- Communicate Results
- Reports
- Results
- Apply results
All of the above is iterative and may be repeated
Step 1: Acquiring Data
- Leave no stone unturned to find data
- Make use of all data
- Data comes from all places, local and remote
- Data comes in different velocities
- Data can come from databases (SQL and NoSQL)
- Data can come from Text files
- Data can come from websites and REST APIs
Step 2-A: Exploring Data
- Specific characteristics of data
- Correlation
- Outliers
- Without this step, can't use data effectively
- Correlation graphs
- General trends (e.g. Sales prices increases every year)
- Mean, Median, Standard Deviation
- Visualization (heatmap, histograms, boxplots, scatter (correlation))
Data Exploration -> Data Understanding -> Informed Analysis

Step 2-B: Pre-Processing Data
- Clean + Transform to make it of quality
- Inconsistent values
- Duplicate records (constumer with same cpf)
- Missing values
- Invalid data (invalid CEP)
- Outliers
- Normalization of values
- Feature selection
- Remove feature (correlated features can be removed)
- Combine features
- Add Feature (cyclic features (sin/cos))
-
Dimensionality Reduction (PCA)
-
Remove data records with missing values
-
Merge duplicate records (conflicting values)
-
Invalid values -> Best estimate (missing employee age, guess from how long work)
-
Remove outliers, if not important for context or specific task
All of the above needs domain knowledge to be done correctly
Step 3: Analyzing Data
- Classification
- Regression
- Clustering
- Graph Analytics
- Use graph structure to find connections between entities
- Association Analysis
- Set of rules to come up with association with items or events. e.g. when they occur together
- Market basket analysis (customer behavior)
Step 4: Communicating Results
- What are the main results
- What added value to these results provide / what can the model add to the application
- Results vs Success criteria at the beggining of the project
- Aggregate facts to back the above
- Results could be puzzling or divergent from expectation
- Visualizations as previous steps
- Tables with results from more in depth analysis
Step 5: Turning Insights into Action
- Something in the business process should change to remove bottleneck?
- Data should be added to application to make it more accurate?
- Should segment population into more groups for more effective targeted marketing?
- Favorable Results? Revist data? Further Opportunities? Real time action?
Basic Scalable Computing Concepts
- Parallel Computer - Several nodes with specifialized capabilities
- Commodity Cluster - Several nodes less specialized than parallel computers
- Data Parallelism - Jobs that share nothing can word on different parts of the dataset
Programming Models for Big Data
- Split large volumes of data
- Access to data should be fast
- Distribute computations to nodes
- Replicate data partitions
- Enable adding new resources
- Optimized for specific data types
- Document
- Table
- Key-value
- Graph
- Multimedia
- Stream
Hadoop
- Scalability
- Fault Tolerance
- Optimized for different data types
- Facilitate a shared environment

Map Reduce
- Map = apply()
- Reduce = Summarize()
Pig
- Dataflow scripting
Hive
- SQL-like queries
Giraph
- Process graphs
Storm, Spark, Flink
- In memory, realtime processing
Key-vakues / Sparse tables
- HBase
- Cassandra
- MongoDB
Zookeeper
- Configuration and management
When to Use Hadoop
- Future anticipated data growth
- Long term availability of data
When not to use Hadoop
- Small dataset
- Advanced Algorithms
- Not a replacement for database
- Random Data Access
- Task Level Parallelism
Cloud

Big Data Modeling and Management Systems
Data Management
-
How do we ingest the data?
-
Where and how do we store it?
-
How can we ensure data quality?
-
What operations do we perform on the data?
-
How can these operations be efficient?
-
How do we scale up data volume, variety, velocity and acess?
-
How do we keep the data secure