现在我们使用迅雷等工具下载资源的时候,基本上都只需要一个叫做磁力链接的东西就可以了,非常方便。

磁力定义
磁力链接是对等网络中进行信息检索和下载文档的电脑程序。和基于“位置”连接的统一资源定位符不同,磁力链接是基于元数据文件内容,属于统一资源名称。也就是说,磁力链接不基于文档的 IP 地址或定位符,而是在分布式数据库中,通过散列函数值来识别、搜索来下载文档。因为不依赖一个处于启动状态的主机来下载文档,所以特别适用没有中心服务器的对等网络。
磁力链接格式类似于 magnet:?xt=urn:btih:E7FC73D9E20697C6C440203F5884EF52F9E4BD28
分解一下这个链接
- magnet:协议名。
- xt:exact topic 的缩写,表示资源定位点。BTIH(BitTorrent Info Hash)表示哈希方法名,这里还可以使用 SHA1 和 MD5。这个值是文件的标识符,是不可缺少的。
一般来讲,一个磁力链接只需要上面两个参数即可找到唯一对应的资源。也有其他的可选参数提供更加详细的信息。
- dn:display name 的缩写,表示向用户显示的文件名。
- tr:tracker 的缩写,表示 tracker 服务器的地址。
- kt: 关键字,更笼统的搜索,指定搜索关键字而不是特定文件。
- mt:文件列表,链接到一个包含磁力链接的元文件 (MAGMA - MAGnet MAnifest)。
这里可以阅读阮一峰的 BT 下载的未来,我很喜欢他文章的最后一句话。
当互联网上每一台机器都在自动交换信息的时候,谎言和封锁又能持续多久呢?
通过磁力就可以获取种子文件从而进行下载,这跟直接使用种子下载时一个道理的,只是少了从磁力到种子文件的一个过程而已。

种子定义
BitTorrent 协议的种子文件可以保存一组文件的元数据。这种格式的文件被 BitTorrent 协议所定义。扩展名一般为“.torrent”。
种子结构
.torrent 种子文件本质上是文本文件,包含 Tracker 信息和文件信息两部分。Tracker 信息主要是 BT 下载中需要用到的 Tracker 服务器的地址和针对 Tracker 服务器的设置,文件信息是根据对目标文件的计算生成的,计算结果根据 BitTorrent 协议内的 Bencode 规则进行编码。它的主要原理是需要把提供下载的文件虚拟分成大小相等的块,块大小必须为2k的整数次方(由于是虚拟分块,硬盘上并不产生各个块文件),并把每个块的索引信息和 Hash 验证码写入种子文件中;所以,种子文件就是被下载文件的“索引”。
种子-磁力联系
磁力链接的唯一标识符就是 40 个 16 进制字符码,也就是 magnet:?xt=urn:btih:E7FC73D9E20697C6C440203F5884EF52F9E4BD28 中的 E7FC73D9E20697C6C440203F5884EF52F9E4BD28。这个同时也是种子文件的 info_hash,是每个种子的唯一标识码。根据它就能将磁力链接于种子联系起来,得到资源的详细信息,进而下载资源。
DHT
BitTorrent 使用”分布式哈希表”(DHT)来为无 tracker 的种子(torrents)存储 peer 之间的联系信息。这样每个 peer 都成了 tracker。这个协议基于 Kademila 网络并且在 UDP 上实现。DHT 由节点组成,它存储了 peer 的位置。BitTorrent 客户端包含一个 DHT 节点,这个节点用来联系 DHT 中其他节点,从而得到 peer 的位置,进而通过 BitTorrent 协议下载。
- peer: 一个 TCP 端口上监听的客户端/服务器,它实现了 BitTorrent 协议。
- 节点: 一个 UDP 端口上监听的客户端/服务器,它实现了 DHT(分布式哈希表) 协议。
如果对 DHT 协议感兴趣的话一定要看下 DHT 协议 的具体内容,这里有 中文翻译版本。(想要彻底读懂项目的话一定要先了解该协议,代码都是基于该协议实现的,我也是反复的阅读了好几遍。)
一般来讲到 Python 爬取,大家的第一印象可能就是 requests/aiohttp,或者是 scrapy/pyspider 等爬虫框架。基本上都是从指定的 HTML 页面爬取信息。我有一个项目 torrent-cli 就是一个从资源网站上爬取磁力信息的工具。

然而我

想自给自足获取磁力种子,Google 了一番,发现大家基本上的代码都是从 simDHT 这个项目来的,首先这个项目很棒,但是些问题如代码不规范、实现细节基本没有一行注释、不兼容 Python3。然而很多网上同类的代码基本上也是对这个完全照搬....

所以我知道我要开始干活了

经过一波 happy coding 之后。

当然最后还是给码出来了啦

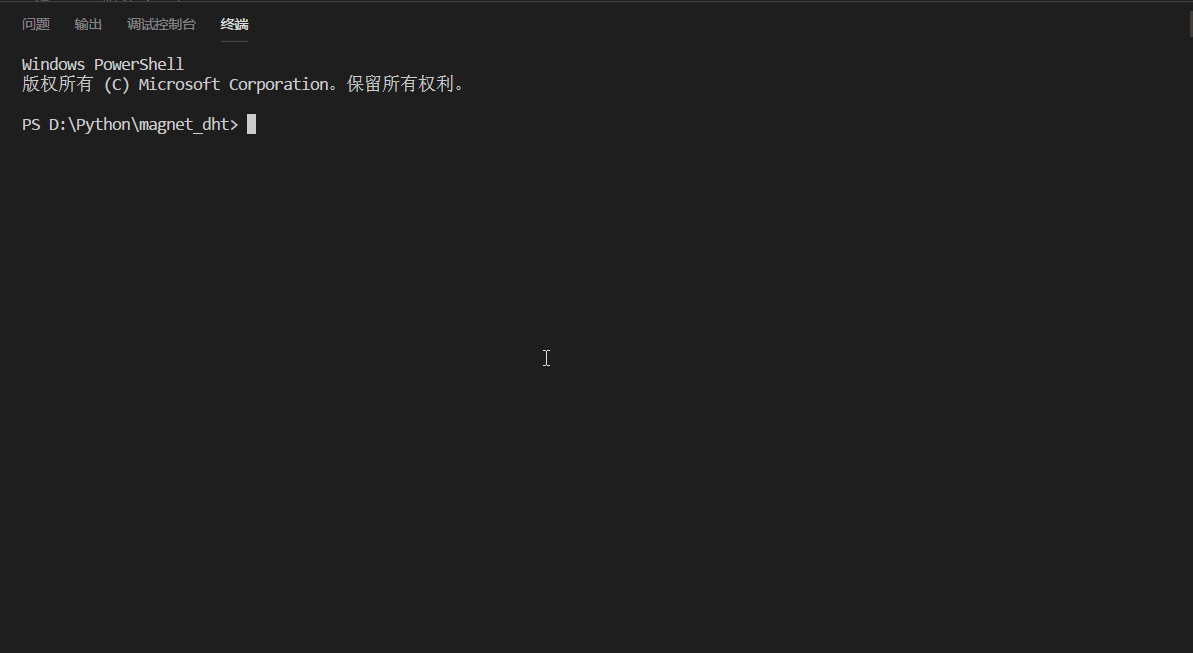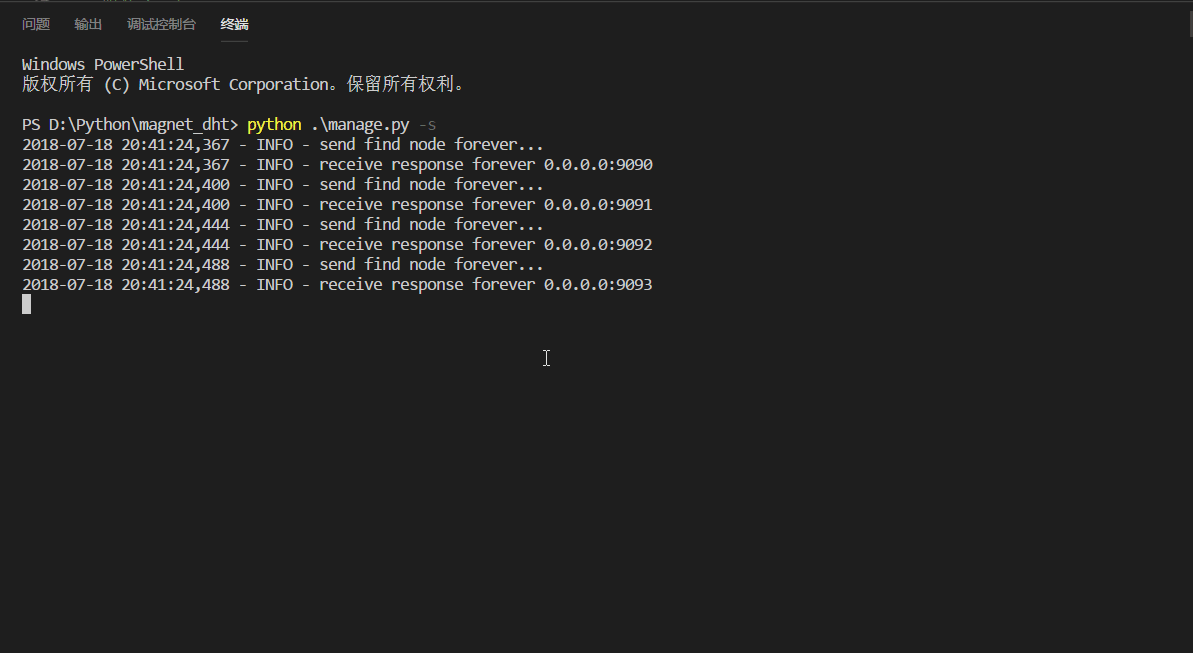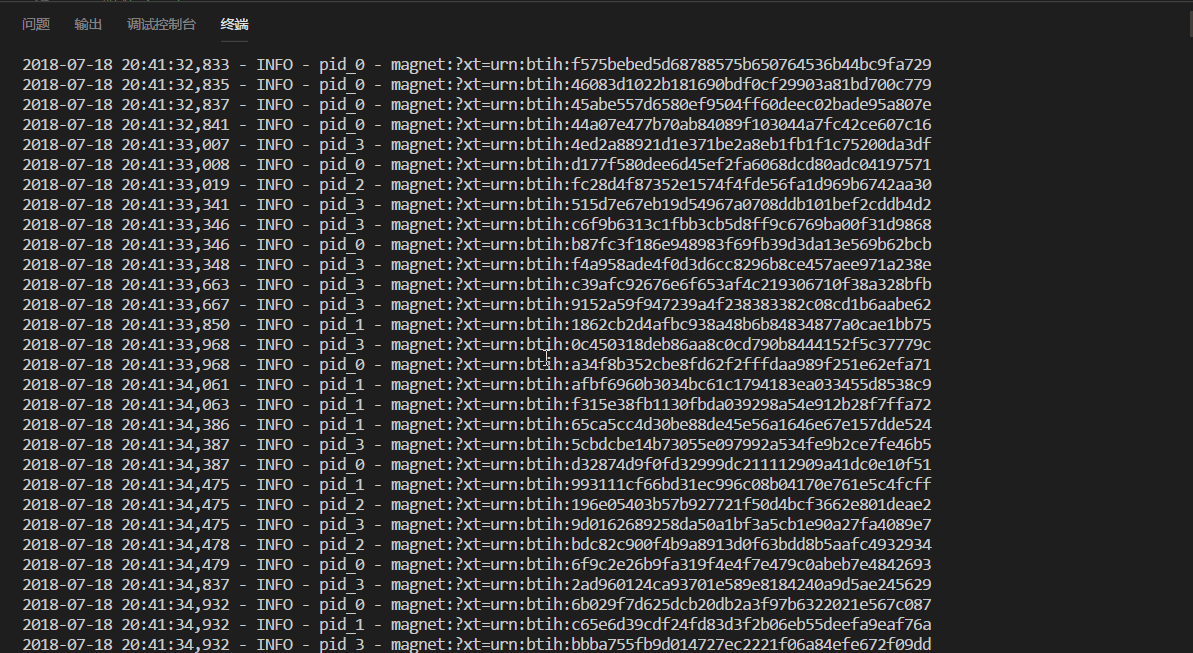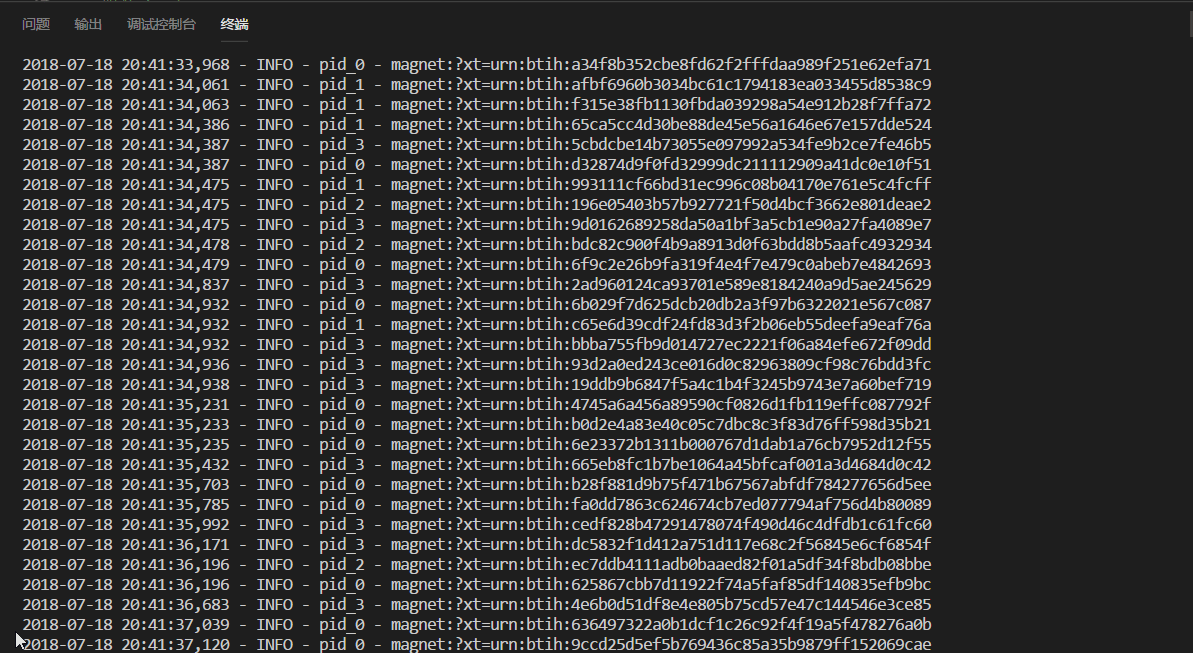
从 DHT 网络中获取磁力链接。主要是利用一些大型的服务器 tracker,冒充 DHT 节点,使用 UDP 协议加入到 DHT 网络中搜索一波以及和其他节点搞好关系,让他们也分享我点资源。

磁力数据存放在了 redis,利用 redis 的集合特性来去重。使用了多线程/多进程,用于提高爬取效率。在我的本地机器(i7-7700HQ/16G 内存/8M 网速)跑了一下,效果还不错。
运行效果
查看 redis 磁链数量
$ redis-cli
127.0.0.1:6379> scard magnets
(integer) 1151256然后代码推送到我那台 性能强悍 1 核/2G 内存/1M 网速 阿里云服务器跑一下,哎....

利用 aria2 将磁力链接转换为种子文件。尝试了一些其他的方式将磁力转换为种子,但效果好像都不怎么理想。使用过 libtorrent 的 Python 版本,不知道是我打开方式不对还是它本来效率就不高,反正愣是一个种子都没有转换成功。

最后兜兜转转用到了 aria2 发现效率还可以。但是要先把 aria2 安装到你的 PATH 中,具体参考官网介绍。使用其 RPC 特性,节省线程开销。

解析种子文件内容,同样也是利用了 Bencode 进行解码。有了种子我们当然要看看到底是些什么资源了啦。你说世界就是这么小,在我解析出来的几百个种子文件中,居然有几个都是一个社区的,那个以 1024 为标志的社区。

有图有真相

不过我还是希望大家铭记下面这 24 字箴言

- database.py:封装了关于 redis 的数据操作,主要是利用其集合数据结构。
- utils.py:一些工具函数
获取源码及安装依赖环境
确保已经安装好 redis,redis 的具体配置可以在 database.py 里面修改
$ git clone https://github.com/chenjiandongx/magnet-dht.git
$ cd magnet-dht
$ pip install -r requirements.txt运行项目
进程数量可以在 crawler.py 进行调整
$ python manage.py -h
usage: manage.py [-h] [-s] [-m] [-p]
start manage.py with flag.
optional arguments:
-h, --help show this help message and exit
-s run start_server func.
-m run magnet2torrent func
-p run parse_torrent funcNote: 在运行 python manage.py -m 的时候,要先开个终端窗口启动 aria2c 服务。
$ aria2c --enable-rpc=true --bt-metadata-only=true --bt-save-metadata=true自我接触编程以来,我一直都是属于兴趣驱动的,对某种技术感兴趣的话就会花时间去研究去尝试。想成为一个有趣的人,去做一些有趣的事。

真心觉得能把脑海里的想法转变为代码实现是件很棒的事,即使可能这件事在别人看来并没有什么了不起。技术发展变化总是那么快,不紧跟着可能不小心就掉队了。所以希望每个真心热爱编程的人都能不忘初心,永远保持对新技术的热情,永远能从编码中找到乐趣。

MIT ©chenjiandongx