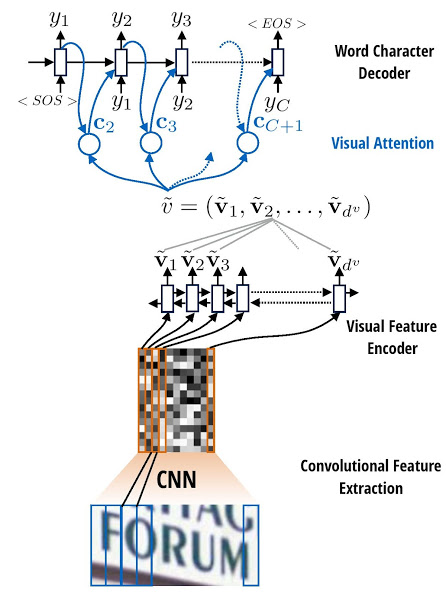
Bidirectional LSTM encoder and attention-enhanced GRU decoder stacked on a multilayer CNN (WYGIWYS) for image-to-transcription.
pip3 install distance
Note: We assume that the working directory is Attention-OCR.
Follow steps for IAM data preparation. IAM consists of ~10k images of handwritten text lines and their transcriptions. The code in the linked repo binarizes the images in a manner that preserves the original grayscale information, converts to JPEG, and scales to 64 pixel height. The code creates a folder for preprocessed images imgs_proc and transcriptions htr/lang/word.


Create a file lines_train.txt from the transcription tr.txt that replaces whitespace with underscore and contains the path of images and the corresponding characters, e.g.:
./imgs_proc/a01-000u-00.jpg A_MOVE_to_stop_Mr._Gaitskell_from
./imgs_proc/a01-000u-01.jpg nominating_any_more_Labour_life_Peers
./imgs_proc/a01-000u-02.jpg is_to_be_made_at_a_meeting_of_Labour
Also create file lines_val.txt from htr/lang/word/va.txt following the same format as above.
python3 src/launcher.py \
--phase=train \
--data-path=lines_train.txt \
--data-base-dir=iamdb \
--gpu-id=0 \
--target-vocab-size=93 \
--use-gru \
--no-load-model
You will see something like the following output in log.txt:
...
2017-05-04 19:15:44,919 root INFO Created model with fresh parameters.
2017-05-04 19:17:22,927 root INFO Generating first batch
2017-05-04 19:17:41,591 root INFO step 0.000000 - time: 14.091797, loss: 4.537364, perplexity: 93.444157, precision: 0.000000, batch_len: 438.000000
2017-05-04 19:17:43,527 root INFO step 1.000000 - time: 1.669232, loss: 4.370135, perplexity: 79.054328, precision: 0.000000, batch_len: 416.000000
2017-05-04 19:17:45,266 root INFO step 2.000000 - time: 1.706899, loss: 4.140279, perplexity: 62.820334, precision: 0.000000, batch_len: 404.000000
2017-05-04 19:17:46,947 root INFO step 3.000000 - time: 1.609537, loss: 3.799597, perplexity: 44.683175, precision: 0.000000, batch_len: 395.000000
2017-05-04 19:17:48,831 root INFO step 4.000000 - time: 1.846071, loss: 3.457146, perplexity: 31.726298, precision: 0.000000, batch_len: 478.000000
2017-05-04 19:17:50,711 root INFO step 5.000000 - time: 1.644378, loss: 3.301664, perplexity: 27.157789, precision: 0.000000, batch_len: 463.000000
2017-05-04 19:17:52,411 root INFO step 6.000000 - time: 1.674972, loss: 3.396979, perplexity: 29.873725, precision: 0.000000, batch_len: 458.000000
2017-05-04 19:17:54,271 root INFO step 7.000000 - time: 1.675854, loss: 3.489168, perplexity: 32.758671, precision: 0.000000, batch_len: 432.000000
2017-05-04 19:17:55,950 root INFO step 8.000000 - time: 1.601847, loss: 3.292296, perplexity: 26.904564, precision: 0.000000, batch_len: 441.000000
2017-05-04 19:17:57,776 root INFO step 9.000000 - time: 1.704575, loss: 3.170712, perplexity: 23.824447, precision: 0.000000, batch_len: 429.000000
2017-05-04 19:17:59,280 root INFO step 10.000000 - time: 0.817045, loss: 3.181931, perplexity: 24.093222, precision: 0.000000, batch_len: 419.000000
Model checkpoints saved in model (the output directory is set via parameter model-dir and the default is model).
We provide a trained model on IAM:
wget https://www.dropbox.com/s/ujxeahr1voo0sl8/model_iamdb_softmax.tar.gz
tar -xvzf model_iamdb_softmax.tar.gz
python3 src/launcher.py \
--phase=test \
--data-path=lines_val.txt \
--data-base-dir=iamdb \
--model-dir=model_iamdb_softmax \
--gpu-id=0 \
--target-vocab-size=93 \
--use-gru \
--load-model
You will see something like the following output in log.txt:
2017-05-04 20:06:32,116 root INFO Reading model parameters from model_iamdb_softmax/translate.ckpt-731000
2017-05-04 20:09:54,266 root INFO Compare word based on edit distance.
2017-05-04 20:09:57,299 root INFO step_time: 2.684323, loss: 12.952633, step perplexity: 421946.118697
2017-05-04 20:10:10,894 root INFO 0.489362 out of 1 correct
2017-05-04 20:10:11,710 root INFO step_time: 0.779765, loss: 16.425102, step perplexity: 13593499.165457
2017-05-04 20:10:22,828 root INFO 0.771970 out of 2 correct
2017-05-04 20:10:23,627 root INFO step_time: 0.776458, loss: 20.803520, step perplexity: 1083562653.786069
2017-05-04 20:10:47,098 root INFO 1.423133 out of 3 correct
2017-05-04 20:10:48,040 root INFO step_time: 0.918638, loss: 11.657264, step perplexity: 115527.486132
2017-05-04 20:11:04,398 root INFO 2.246663 out of 4 correct
2017-05-04 20:11:07,883 root INFO step_time: 3.448558, loss: 10.126567, step perplexity: 24998.394628
2017-05-04 20:11:25,554 root INFO 2.483505 out of 5 correct
2017-05-04 20:11:26,439 root INFO step_time: 0.846741, loss: 19.127279, step perplexity: 202708446.724307
2017-05-04 20:11:54,204 root INFO 3.203505 out of 6 correct
2017-05-04 20:11:55,547 root INFO step_time: 1.328614, loss: 14.361533, step perplexity: 1726372.881045
2017-05-04 20:12:16,062 root INFO 3.586483 out of 7 correct
2017-05-04 20:12:16,933 root INFO step_time: 0.846231, loss: 13.471820, step perplexity: 709148.247623
2017-05-04 20:12:53,892 root INFO 4.261483 out of 8 correct
2017-05-04 20:12:55,135 root INFO step_time: 1.206629, loss: 8.952523, step perplexity: 7727.365214
2017-05-04 20:13:24,057 root INFO 5.025120 out of 9 correct
2017-05-04 20:13:24,860 root INFO step_time: 0.770344, loss: 17.900974, step perplexity: 59469508.304005
Output images in results (the output directory is set via parameter output-dir and the default is results). This example visualizes attention on an image:

This example plots the attention alignment over an image:

Default parameters set in the file src/exp_config.py.
-
Control
GPU-ID: ID number of the GPU.phase: Determine whether to train or test.visualize: Valid ifphaseis set to test. Output the attention maps on the original image.load-model: Load model frommodel-diror not.
-
Input and output
data-base-dir: The base directory of the image path indata-path. If the image path indata-pathis absolute path, set it to/.data-path: The path containing data file names and labels. Format per line:image_path characters.model-dir: The directory for saving and loading model parameters (structure is not stored).log-path: The path to put log.output-dir: The path to put visualization results ifvisualizeis set to True.steps-per-checkpoint: Checkpointing (print perplexity, save model) per how many steps
-
Optimization
num-epoch: The number of whole data passes.batch-size: Batch size. Only valid ifphaseis set to train.initial-learning-rate: Initial learning rate, note the we use AdaDelta, so the initial value doe not matter much.
-
Network
reg-val: Lambda for L2 regularization losses.clip-gradients: Whether to perform gradient clipping.max-gradient-norm: Clip gradients to this norm.target-embedding-size: Embedding dimension for each target.opt-attn: Which attention mechanism to use:softmax(default);sigmoid;no_attn.attn-use-lstm: Whether or not use LSTM attention decoder cell.attn-num-hidden: Number of hidden units in attention decoder cell.attn-num-layers: Number of layers in attention decoder cell. (Encoder number of hidden units will beattn-num-hidden*attn-num-layers).target-vocab-size: Target vocabulary size. Default is = 26+10+3 # 0: PADDING, 1: GO, 2: EOS, >2: 0-9, a-z
This repo is forked from Attention-OCR by Qi Guo and Yuntian Deng. The model is described in their paper What You Get Is What You See: A Visual Markup Decompiler.
IAM image and transcription preprocessing from Laia.