FEDOT
| package | |
|---|---|
| tests | |
| docs | |
| license |  |
| stats | |
| support |
This repository contains FEDOT - an open-source framework for automated modeling and machine learning (AutoML). It can build custom modeling pipelines for different real-world processes in an automated way using an evolutionary approach. FEDOT supports classification (binary and multiclass), regression, clustering, and time series prediction tasks.

The main feature of the framework is the complex management of interactions between various blocks of pipelines. First of all, this includes the stage of machine learning model design. FEDOT allows you to not just choose the best type of the model, but to create a complex (composite) model. It allows you to combine several models of different complexity, which helps you to achieve better modeling quality than when using any of these models separately. Within the framework, we describe composite models in the form of a graph defining the connections between data preprocessing blocks and model blocks.
The framework is not limited to specific AutoML tasks (such as pre-processing of input data, feature selection, or optimization of model hyperparameters), but allows you to solve a more general structural learning problem - for a given data set, a solution is built in the form of a graph (DAG), the nodes of which are represented by ML models, pre-processing procedures, and data transformation.
The project is maintained by the research team of the Natural Systems Simulation Lab, which is a part of the National Center for Cognitive Research of ITMO University.
The intro video about Fedot is available here:
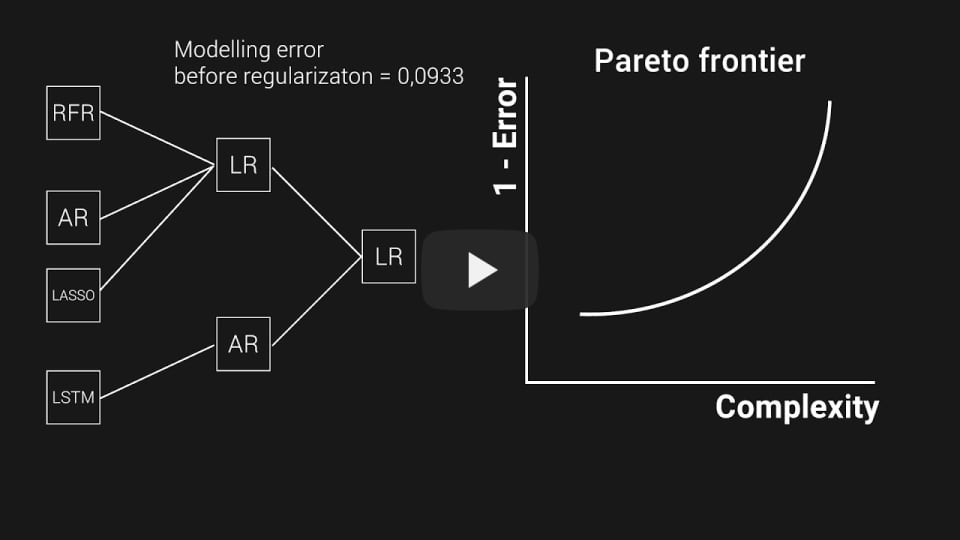
FEDOT features
The main features of the framework are as follows:
- The FEDOT architecture is highly flexible and therefore the framework can be used to automate the creation of mathematical models for various problems, types of data, and models;
- FEDOT already supports popular ML libraries (scikit-learn, keras, statsmodels, etc.), but you can also integrate custom tools into the framework if necessary;
- Pipeline optimization algorithms are not tied to specific data types or tasks, but you can use special templates for a specific task class or data type (time series forecasting, NLP, tabular data, etc.) to increase the efficiency;
- The framework is not limited only to machine learning, it is possible to embed models related to specific areas into pipelines (for example, models in ODE or PDE);
- Additional methods for hyperparameters tuning can be seamlessly integrated into FEDOT (in addition to those already supported);
- The resulting pipelines can be exported in a human-readable JSON format, which allows you to achieve reproducibility of the experiments.
Thus, compared to other frameworks, FEDOT:
- Is not limited to specific modeling tasks and claims versatility and expandability;
- Allows managing the complexity of models and thereby achieving better results.
- Allows building models using input data of various nature (texts, images, tables, etc.) and consisting of different types of models.
Installation
Common installation:
$ pip install fedot
In order to work with FEDOT source code:
$ git clone https://github.com/nccr-itmo/FEDOT.git $ cd FEDOT $ pip install -r requirements.txt $ pytest -s test
How to use
FEDOT provides a high-level API that allows you to use its capabilities in a simple way. At the moment, the API can be used for classification and regression tasks only. But the time series forecasting and clustering support will be implemented soon (you can still solve these tasks via advanced initialization, see below). Input data must be either in NumPy arrays or CSV files.
To use the API, follow these steps:
- Import Fedot class
from fedot.api.main import Fedot- Initialize the Fedot object and define the type of modeling problem. It provides a fit/predict interface:
- fedot.fit runs the optimization and returns the resulting composite model;
- fedot.predict returns the prediction for the given input data;
- fedot.get_metrics estimates the quality of predictions using selected metrics
Numpy arrays, pandas data frames, and file paths can be used as sources of input data.
model = Fedot(problem='classification')
model.fit(features=train_data.features, target=train_data.target)
prediction = model.predict(features=test_data.features)
metrics = model.get_metrics()For more advanced approaches, please use Examples & Tutorials section.
Examples & Tutorials
Jupyter notebooks with tutorials are located in the "notebooks" folder. There you can find the following guides:
- Intro to AutoML
- Intro to FEDOT functionality
- Intro to time series forecasting with FEDOT
- Advanced time series forecasting
- Gap-filling in time series and out-of-sample forecasting
Notebooks are issued with the corresponding release versions (the default version is 'latest'). In the "notebooks" folder, you can also find examples for previous releases' functionality.
Also, external examples are available:
Extended examples:
- Credit scoring problem, i.e. binary classification task
- Time series forecasting, i.e. random process regression
- Spam detection, i.e. natural language preprocessing
- Movie rating prediction with multi-modal data
Also, several video tutorials are available (in Russian).
Publications about FEDOT
We also published several posts and news devoted to the different aspects of the framework:
In English:
- How AutoML helps to create composite AI? - towardsdatascience.com
- AutoML for time series: definitely a good idea - towardsdatascience.com
- AutoML for time series: advanced approaches with FEDOT framework - towardsdatascience.com
- Experience of hackathon winning with FEDOT - itmo.news
In Russian:
- General concepts of evolutionary design for composite pipelines - habr.com
- Automated time series forecasting with FEDOT - habr.com
- Experience of hackathon winning with FEDOT - itmo.news
Project structure
The latest stable release of FEDOT is on the master branch.
The repository includes the following directories:
- Package core contains the main classes and scripts. It is the core of FEDOT framework
- Package examples includes several how-to-use-cases where you can start to discover how FEDOT works
- All unit and integration tests can be observed in the test directory
- The sources of the documentation are in the docs
Also, you can check benchmarking a repository that was developed to provide a comparison of FEDOT against some well-known AutoML frameworks.
Current R&D and future plans
Currently, we are working on new features and trying to improve the performance and the user experience of FEDOT. The major ongoing tasks and plans:
- Effective and ready-to-use pipeline templates for certain tasks and data types;
- Integration with GPU via Rapids framework;
- Alternative optimization methods of fixed-shaped pipelines;
- Integration with MLFlow for import and export of the pipelines;
- Improvement of high-level API.
Also, we are doing several research tasks related to AutoML time-series benchmarking and multi-modal modeling.
Any contribution is welcome. Our R&D team is open for cooperation with other scientific teams as well as with industrial partners.
Documentation
The general description is available in FEDOT.Docs repository.
Also, a detailed FEDOT API description is available in the Read the Docs.
Contribution Guide
- The contribution guide is available in the repository.
Acknowledgments
We acknowledge the contributors for their important impact and the participants of the numerous scientific conferences and workshops for their valuable advice and suggestions.
Contacts
- Telegram channel for solving problems and answering questions on FEDOT
- Natural System Simulation Team
- Anna Kalyuzhnaya, team leader (anna.kalyuzhnaya@itmo.ru)
- Newsfeed
- Youtube channel
Supported by
Citation
- @article{nikitin2021automated,
- title={Automated Evolutionary Approach for the Design of Composite Machine Learning Pipelines}, author={Nikitin, Nikolay O and Vychuzhanin, Pavel and Sarafanov, Mikhail and Polonskaia, Iana S and Revin, Ilia and Barabanova, Irina V and Maximov, Gleb and Kalyuzhnaya, Anna V and Boukhanovsky, Alexander}, journal={arXiv preprint arXiv:2106.15397}, year={2021}}
- @article{nikitin2020structural,
- title={Structural Evolutionary Learning for Composite Classification Models}, author={Nikitin, Nikolay O and Polonskaia, Iana S and Vychuzhanin, Pavel and Barabanova, Irina V and Kalyuzhnaya, Anna V}, journal={Procedia Computer Science}, volume={178}, pages={414--423}, year={2020}, publisher={Elsevier}}
- @inproceedings{kalyuzhnaya2020automatic,
- title={Automatic evolutionary learning of composite models with knowledge enrichment}, author={Kalyuzhnaya, Anna V and Nikitin, Nikolay O and Vychuzhanin, Pavel and Hvatov, Alexander and Boukhanovsky, Alexander}, booktitle={Proceedings of the 2020 Genetic and Evolutionary Computation Conference Companion}, pages={43--44}, year={2020}}
Other papers - in ResearchGate.