🤗 Hugging Face | 📑 Paper
| Models | TimeLlama-7b | ChatTimeLlama-7b | TimeLlama-13b | ChatTimeLlama-13b |
|---|---|---|---|---|
| Huggingface Repo | 🤗 | 🤗 | 🤗 | 🤗 |
- 2023.9.30 🔥 The TimeLlama series models are available on huggingface.
This repository contains the code and dataset for our work on explainable temporal reasoning. Temporal reasoning involves predicting future events based on understanding the temporal relationships between events described in the text. Explainability is critical for building trust in AI systems that make temporal predictions.
In this work, we introduce the first multi-source dataset for explainable temporal reasoning, called ExpTime. The dataset contains 26k examples derived from temporal knowledge graph datasets. Each example includes a context with multiple events, a future event to predict, and an explanation for the prediction in the form of temporal reasoning over the events.
To generate the dataset, we propose a novel knowledge-graph-instructed-generation strategy. The dataset supports the comprehensive evaluation of large language models on complex temporal reasoning, future event prediction, and explainability.
Based on ExpTime, we develop TimeLlaMA, a series of LLM models fine-tuned for explainable temporal reasoning. TimeLlaMA builds on the foundation LLM LLaMA-2 and utilizes instruction tuning to follow prompts for making explanations.
The code in this repo allows training TimeLlaMA models on ExpTime and evaluating their temporal reasoning and explanation abilities. We open-source the code, dataset, and models to provide a basis for future work on explainable AI.
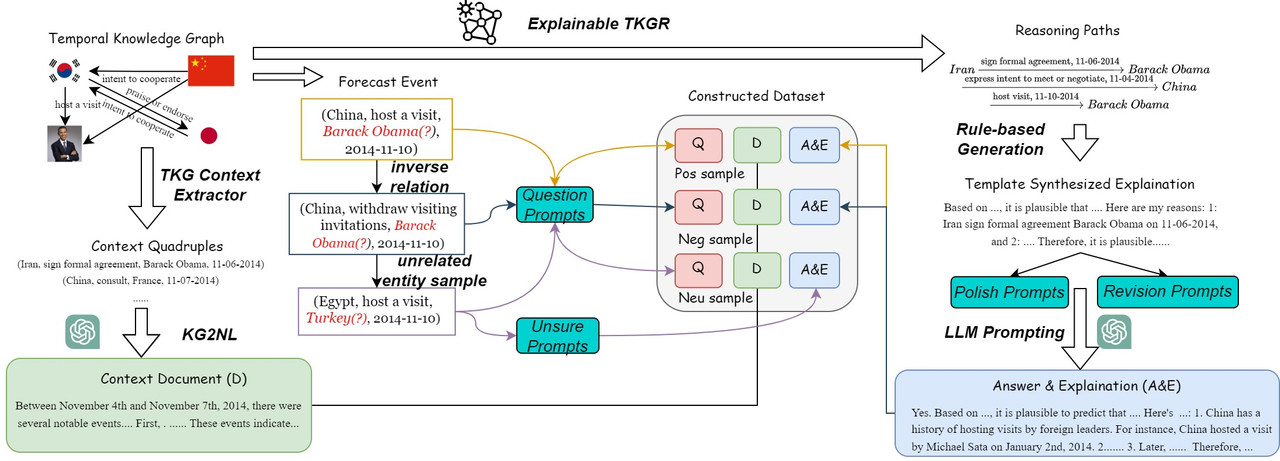
Recent work has shown promise in using large language models (LLMs) like ChatGPT to automatically generate datasets by prompting the model to produce answers. However, directly prompting LLMs to generate temporal reasoning explanations results in low-quality and incoherent outputs.
To address this challenge, we propose a novel framework called Temporal Knowledge Graph-instructed Generation (GIG) to produce more accurate and coherent reasoning explanations. The key idea is to leverage temporal knowledge graphs (TKGs), which have been effectively utilized for explainable event forecasting. Our approach first applies explainable TKG reasoning models to generate reasoning paths for a given query about a future event. We then convert these paths into natural language explanations using a two-level prompting technique. Next, we identify relevant context from the TKG and reasoning paths to construct a coherent context document. Finally, we convert the original query into a question to produce a complete training instance.
In this way, our GIG framework overcomes the limitations of directly prompting LLMs by leveraging structured knowledge in TKGs to generate higher-quality temporal reasoning explanations. We believe this approach could enable more effective use of LLMs guided by knowledge graphs for automated dataset creation.
Stay tuned for the code release of our GIG framework
We release the first-of-its-kind Explainable Temporal Event Forecasting (ExpTime) dataset, which aims to assess and enhance the complex temporal reasoning capabilities of large language models (LLMs). The dataset has the following format:
[
{
"instruction": "Given the following document, is there a potential that......",
"input": "In the context of Egypt, on April 19, 2014......",
"output": "Yes. Based on the information provided by the document......",
"label": "pos"
}
]In each sample of the ExpTime dataset, the instruction provides the query if an event will happen in the future. The input provides a context document about past events information, and the output is the prediction along with explanations. The label "pos", "neg", and "unsure" denotes if the answer should be "yes", "no", or "unsure", respectively. The dataset can be found in the dataset folder, where "train_dataset.json" is the training set and "eval_dataset.json" is the human-annotated golden testing set.
To use the TimeLlama series for the inference, all you need to do is write the following codes.
from transformers import LlamaConfig, LlamaTokenizer, LlamaForCausalLM
# Model names: "chrisyuan45/TimeLlama-7b-chat", "chrisyuan45/TimeLlama-13b-chat"
model = LlamaForCausalLM.from_pretrained(
model_name,
return_dict=True,
load_in_8bit=quantization,
device_map="auto",
low_cpu_mem_usage=True)
tokenizer = LlamaTokenizer.from_pretrained(model_name)However, if you prefer no coding, we also prepare a chat script for you (of course!). All you need to do is:
python ChatwithModel.py --model_name chrisyuan45/TimeLlama-7b-chatWe provide our finetuning code in "train.py". To run the finetuning code, you need to have access to meta-llama models. Click here to submit the request form Llama2 Access. Then, please generate your own access token on huggingface and replace line 23 in train.py accordingly.
To run the finetuning code on multi-GPUs, please consider adopting the following script:
#!/bin/bash
torchrun --nproc_per_node 8 --master_port 14545 train.py\
--data_path dataset/train_dataset.json \
--output_dir model13chat \
--num_train_epochs 70 \
--per_device_train_batch_size 1 \
--per_device_eval_batch_size 1 \
--tf32 True \
--bf16 True \
--gradient_accumulation_steps 4 \
--weight_decay 0.01 \
--warmup_ratio 0.05 \
--lr_scheduler_type "cosine" \
--logging_steps 1 \
--gradient_checkpointing True \
--disable_tqdm False \
--learning_rate 5e-5 \
--fsdp "full_shard offload auto_wrap" \
--fsdp_transformer_layer_cls_to_wrap 'LlamaDecoderLayer' \
We evaluate the most popular LLMs on our golden human-annotated ExpTime evaluation dataset besides the TimeLlama series. The prediction is evaluated by the F1 score and explanation correctness is evaluated via BLEU, ROURGE, and BertScore. We also included human evaluation results in our paper. The brief evaluation results are shown here:
| Models | Pos F1 | Neg F1 | Neu F1 | Overall F1 | BLEU | ROUGE | BertScore |
|---|---|---|---|---|---|---|---|
| Flan T5 | 39.9 | 40.5 | 31.5 | 38.0 | 15.2 | 26.0 | 76.9 |
| BART | 34.9 | 16.2 | 19.8 | 25.3 | 8.9 | 19.7 | 74.9 |
| MPT-7B | 55.4 | 37.5 | 18.7 | 40.3 | 10.7 | 27.2 | 80.1 |
| Falcon-7B | 51.7 | 27.8 | 21.5 | 36.5 | 19.8 | 29.3 | 79.9 |
| Vicuna-7B | 60.4 | 28.1 | 22.6 | 40.4 | 23.5 | 37.2 | 83.3 |
| ChatGPT | 54.7 | 30.5 | 39.8 | 43.5 | 31.1 | 37.1 | 83.7 |
| Llama2-7B-chat | 62.7 | 19.8 | 22.0 | 39.1 | 26.8 | 38.4 | 83.8 |
| Llama2-13B-chat | 52.5 | 31.5 | 31.8 | 40.7 | 25.5 | 36.6 | 83.4 |
| TimeLlama2-7B | 93.7 | 75.3 | 70.5 | 81.5 | 59.9 | 56.5 | 90.2 |
| TimeLlama2-13B | 97.2 | 81.7 | 77.5 | 87.3 | 44.6 | 54.9 | 89.4 |
| TimeLlama2-7B-chat | 95.2 | 76.1 | 71.2 | 83.1 | 61.9 | 57.7 | 90.4 |
| TimeLlama2-13B-chat | 97.9 | 83.4 | 78.5 | 88.4 | 46.3 | 56.3 | 89.7 |
Consider citing our paper if you find the repo useful ;)
@article{yuan2023back,
title={Back to the Future: Towards Explainable Temporal Reasoning with Large Language Models},
author={Yuan, Chenhan and Xie, Qianqian and Huang, Jimin and Ananiadou, Sophia},
journal={arXiv preprint arXiv:2310.01074},
year={2023}
}