




这是一个轻松赚钱的项目。
短视频时代,谁掌握了流量谁就掌握了Money!
所以给大家分享这个经过精心打造的MoneyPrinter项目。
它可以:使用AI大模型技术,一键批量生成各类短视频。
它可以:一键混剪短视频,批量生成短视频不是梦。
它可以:自动把视频发布到抖音,快手,小红书,视频号上。
赚钱从来没有这么容易过!
觉得有用的朋友,请给个star!
MoneyPrinterPlus一键AI短视频生成工具开源啦
MoneyPrinterPlus AI批量短视频混剪工具使用说明
MoneyPrinterPlus小白使用教程来啦!一键万条短视频
MoneyPrinterPlus一键批量上传视频功能来啦,让收费见鬼去吧!
MoneyPrinterPlus全面支持本地chatTTS模型
MoneyPrinterPlus一键发布短视频到视频号,抖音,快手,小红书上线了
MoneyPrinterPlus全面支持本地Ollama大模型
在MoneyPrinterPlus中使用本地chatTTS语音模型
fasterWhisper和MoneyPrinterPlus无缝集成
再升级!MoneyPrinterPlus集成GPT_SoVITS
使用介绍: 重磅!免费一键批量混剪工具它来了,一天上万短视频不是梦
使用介绍: moneyPrinterPlus详细使用教程


MoneyPrinterPlus一键发布短视频到视频号,抖音,快手,小红书上线了
- 准备接入stable diffusion和comfyUI, OOOOO,太牛了!
- 已经支持GPTsoVITS本地语音模型啦,教程再升级!MoneyPrinterPlus集成GPT_SoVITS
- 已经支持本地语音识别模型fasterwhisper, 教程fasterWhisper和MoneyPrinterPlus无缝集成。 可关注我公众号获得最新进度。
- 已经支持本地语音模型ChatTTS了,教程 在MoneyPrinterPlus中使用本地chatTTS语音模型
- 支持本地大模型工具Ollama MoneyPrinterPlus全面支持本地Ollama大模型
- 视频自动发布功能已经上线了!!!! 使用教程MoneyPrinterPlus一键发布短视频到视频号,抖音,快手,小红书上线了
- 20240813 支持GPTsoVITS本地语音模型
- 20240807 存储了session值,这样在刷新的时候不需要重新输入信息了
- 20240722 支持本地语音识别模型fasterwhisper
- 20240713 支持本地语音模型ChatTTS
- 20240710 支持本地大模型:Ollama
- 20240708 逆天了!自动发布视频功能上线了。支持抖音,快手,小红书,视频号!!!
- 20240704 添加自动安装和自动启动脚本,方便小白使用。
- 20240628 重磅更新!支持批量视频混剪,批量生成大量不重复的短视频!!!!!!
- 20240620 优化视频合成效果,让视频结束更加自然。
- 20240619 语音识别和语音合成支持腾讯云。 需要开通腾讯云语音合成和语音识别这两个功能
- 20240615 语音识别和语音合成支持阿里云。 需要开通阿里云智能语音交互功能--必须开通语音合成和录音文件识别(极速版)这两个功能
- 20240614 资源库支持pixabay,支持语音试听功能,修复一些bug
- 支持本地语音模型chatTTS, fasterwhisper等
- 支持本地语音字幕识别模型
- 视频批量自动发布到各个视频平台,支持抖音,快手,小红书,视频号!!!
- 视频批量混剪,批量产出大量不重复的短视频
- 支持本地素材选择(支持各种素材mp4,jpg,png),支持各种分辨率。
- 云大模型接入OpenAI,Azure,Kimi,Qianfan,Baichuan,Tongyi Qwen, DeepSeek
- 本地大模型接入Ollama
- 支持Azure语音功能
- 支持阿里云语音功能
- 支持腾讯云语音功能
- 支持100+不同的语音种类
- 支持语音试听功能
- 支持30+种视频转场特效
- 支持不同分辨率,不同尺寸和比例的视频生成
- 支持语音选择和语速调节
- 支持背景音乐
- 支持背景音乐音量调节
- 支持自定义字幕
- 覆盖市面上主流的AI大模型工具
- [] 支持更多的视频资源获取方式
- [] 支持更多的视频转场特效
- [] 支持更多的字幕特效
- [] 接入stable diffusion,AI生图,合成视频
- [] 接入Sora等AI视频大模型工具,自动生成视频
| 竖屏 | 横屏 | 正方形 |
|---|---|---|
final-1718158522826.mp4 |
final-1718160166012.mp4 |
final-1718160533551.mp4 |
- Python 3.10+
- ffmpeg 6.0+
- LLM api key
- Azure语音服务(https://speech.microsoft.com/portal)
- 或者阿里云智能语音功能(https://nls-portal.console.aliyun.com/overview)
- 或者腾讯云语音技术功能(https://console.cloud.tencent.com/asr)
切记!!!!! 一定要安装好ffmpeg,并把ffmpeg路径添加到环境变量中。
- 确保你有Python 3.10+的运行环境。如果是windows, 请确保安装了python路径已经添加到了PATH中。
- 确保你有ffmpeg 6.0+的运行环境。如果是windows, 请确保安装了ffmpeg路径已经添加到了PATH中。没有安装ffmpeg的朋友,请通过 https://ffmpeg.org/ 来安装对应的版本。
如果python和ffmpeg环境都有了。那么就可以通过pip安装依赖包了。
pip install -r requirements.txt进入项目目录,windows下双击执行:
setup.batmac或者linux下执行:
bash setup.sh使用下面命令运行程序:
streamlit run gui.py如果你使用了自动安装脚本,那么可以执行下面的脚本来自动运行。
windows下,双击 start.bat
mac或者linux下执行:
bash start.sh在日志文件中可以看到程序运行的日志信息。
里面有浏览器的地址,可以通过浏览器打开这个地址来访问程序。
打开之后,你会看到下面的界面:
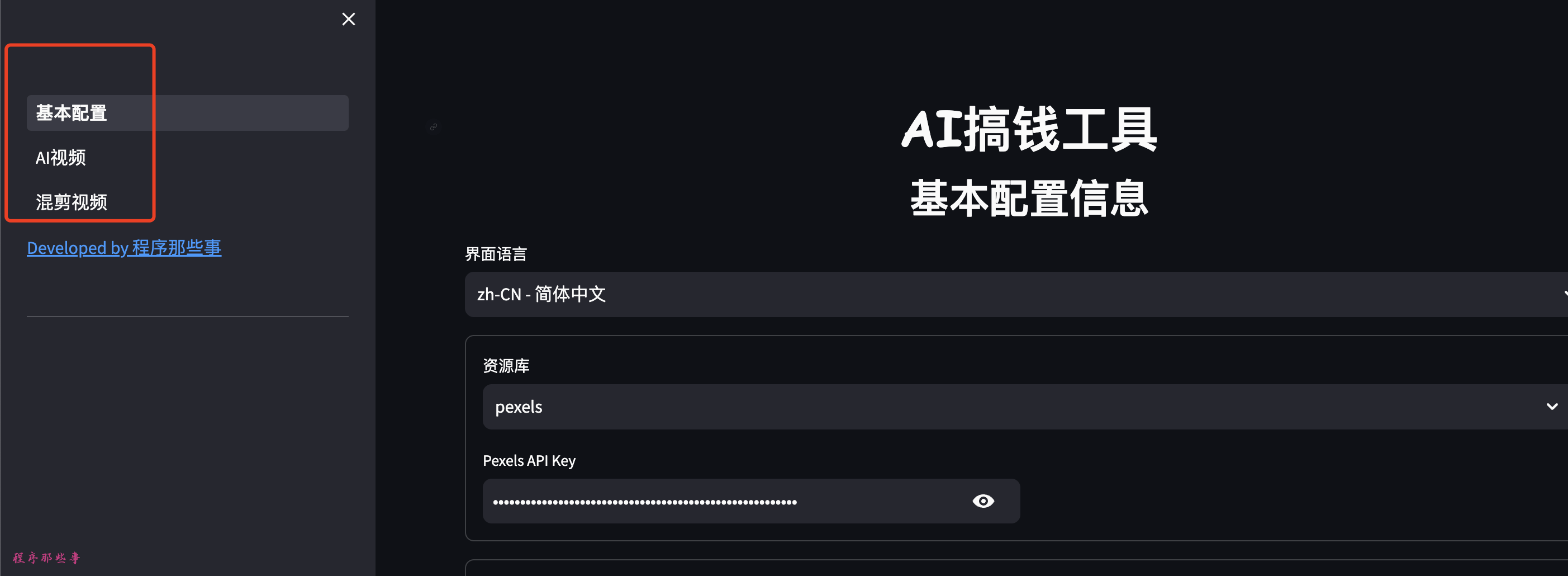
左侧目前有三项配置, 分别是基本配置,AI视频和混剪视频(开发中)。
目前资源支持:
- pexels: www.pexels.com Pexels 是世界上著名的免费图片,视频素材网站。
- pixabay: pixabay.com
大家需要到对应的网站上注册一个key来实现API调用。
后续会陆续添加其他资源库。如(videvo.net,videezy.com 等)
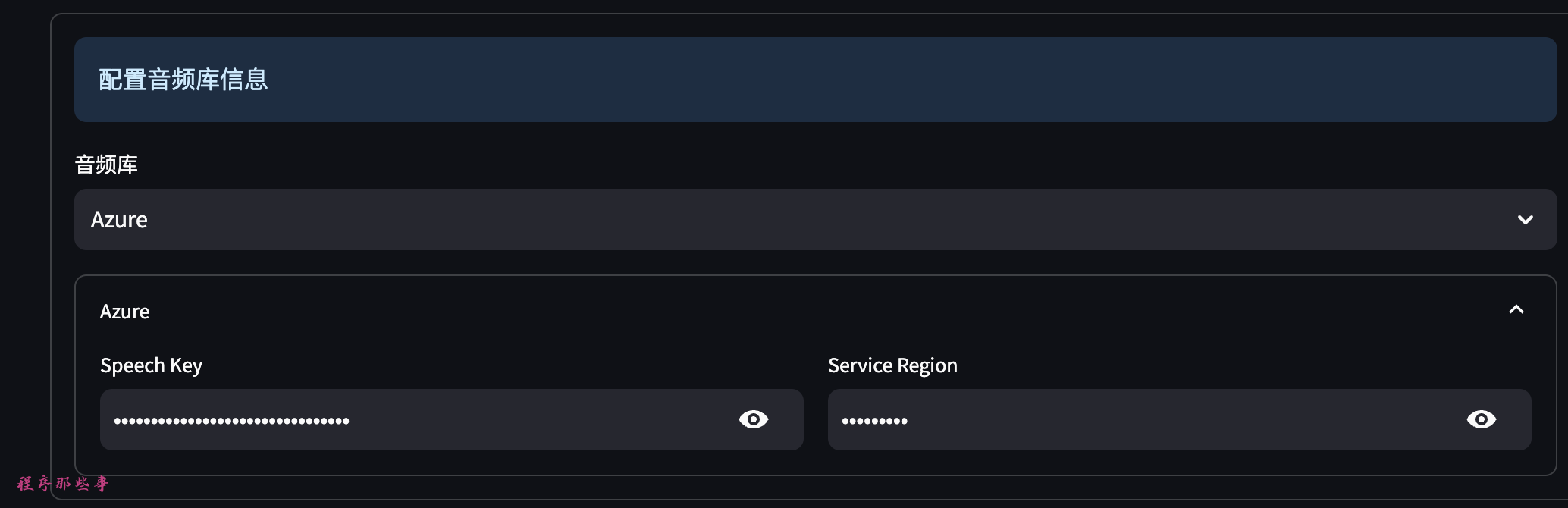
目前文字转语音和语音识别功能支持:
- Azure的cognitive-services服务。
- 阿里云的智能语音交互
- 腾讯云语音技术功能(https://console.cloud.tencent.com/asr)
- Azure:
大家需要到 https://speech.microsoft.com/portal 这里注册一个key。
Azure对新用户是1年免费的。费用也是比较便宜。
- 阿里云:
大家需要到 https://nls-portal.console.aliyun.com/overview 这里开通服务,并添加一个项目。
需要开通阿里云智能语音交互功能--必须开通语音合成和录音文件识别(极速版)这两个功能.
- 腾讯云:
腾讯云语音技术功能(https://console.cloud.tencent.com/asr) 开通语音识别和语音合成功能。
后续会添加本地语音识别大模型。但是文字转语音还是微软的服务最为优秀。
大模型区目前支持Moonshot,openAI,Azure openAI,Baidu Qianfan, Baichuan,Tongyi Qwen, DeepSeek这些。
推荐使用Moonshot。
会陆续添加市面上其他流行的大模型。
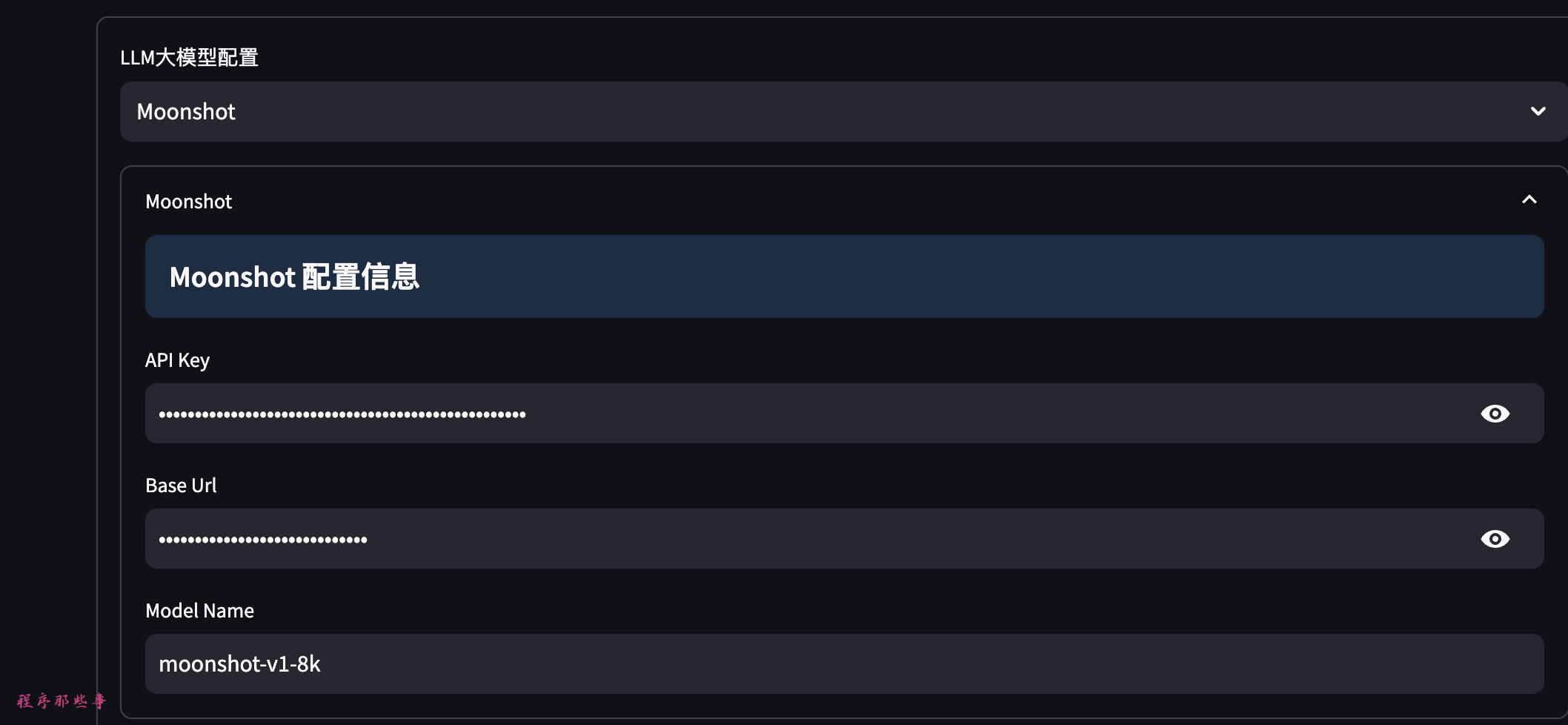
Moonshot API获取地址: https://platform.moonshot.cn/
baidu qianfan API获取地址:https://cloud.baidu.com/doc/WENXINWORKSHOP/s/yloieb01t
baichuan API获取地址: https://platform.baichuan-ai.com/
阿里tongyi qwen API获取地址: https://help.aliyun.com/document_detail/611472.html?spm=a2c4g.2399481.0.0
DeepSeek API获取地址: https://www.deepseek.com/
基本配置设置完毕之后。就可以进入到AI视频了。
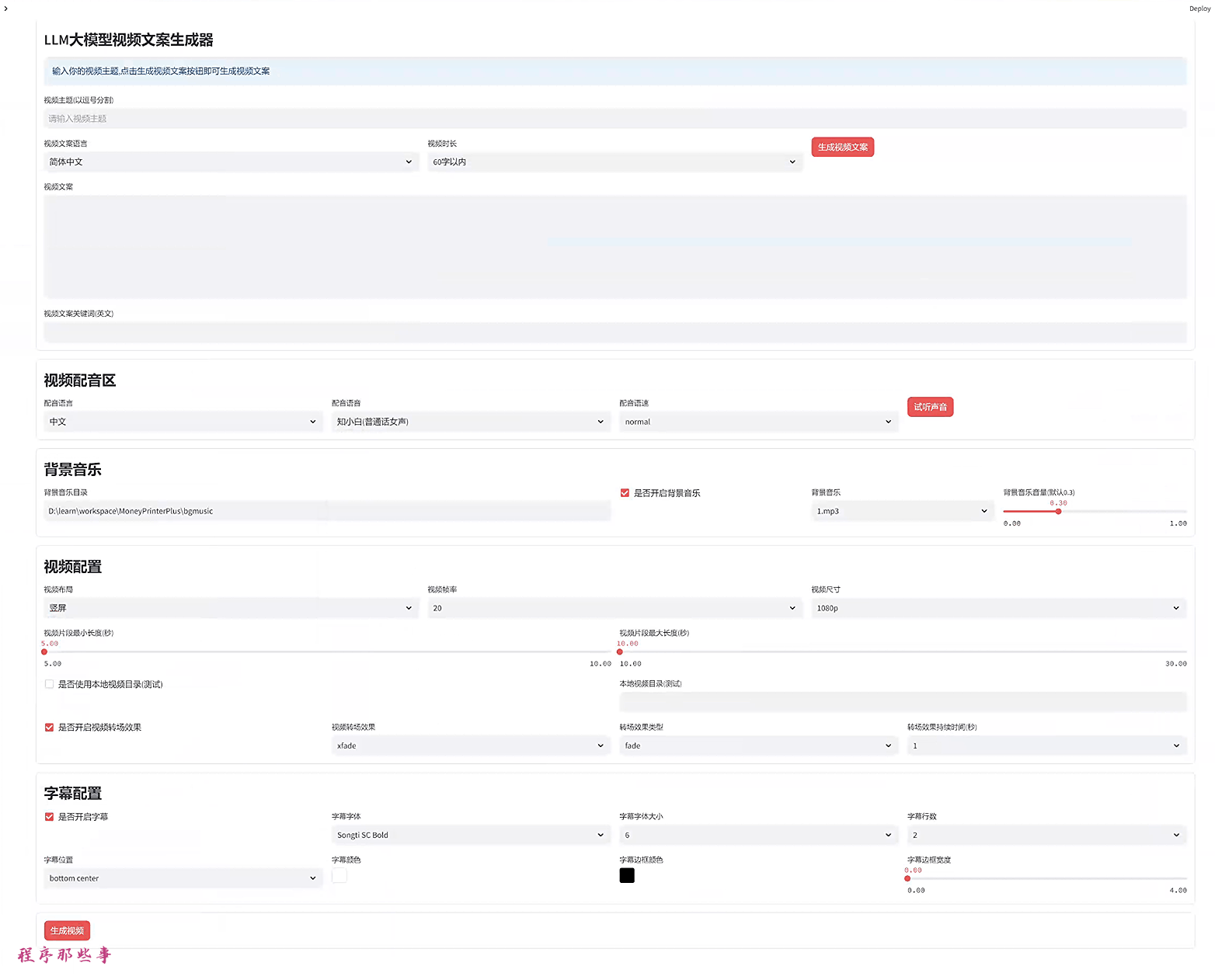
首先,我们给一个关键词,然后用大模型生成视频文案:
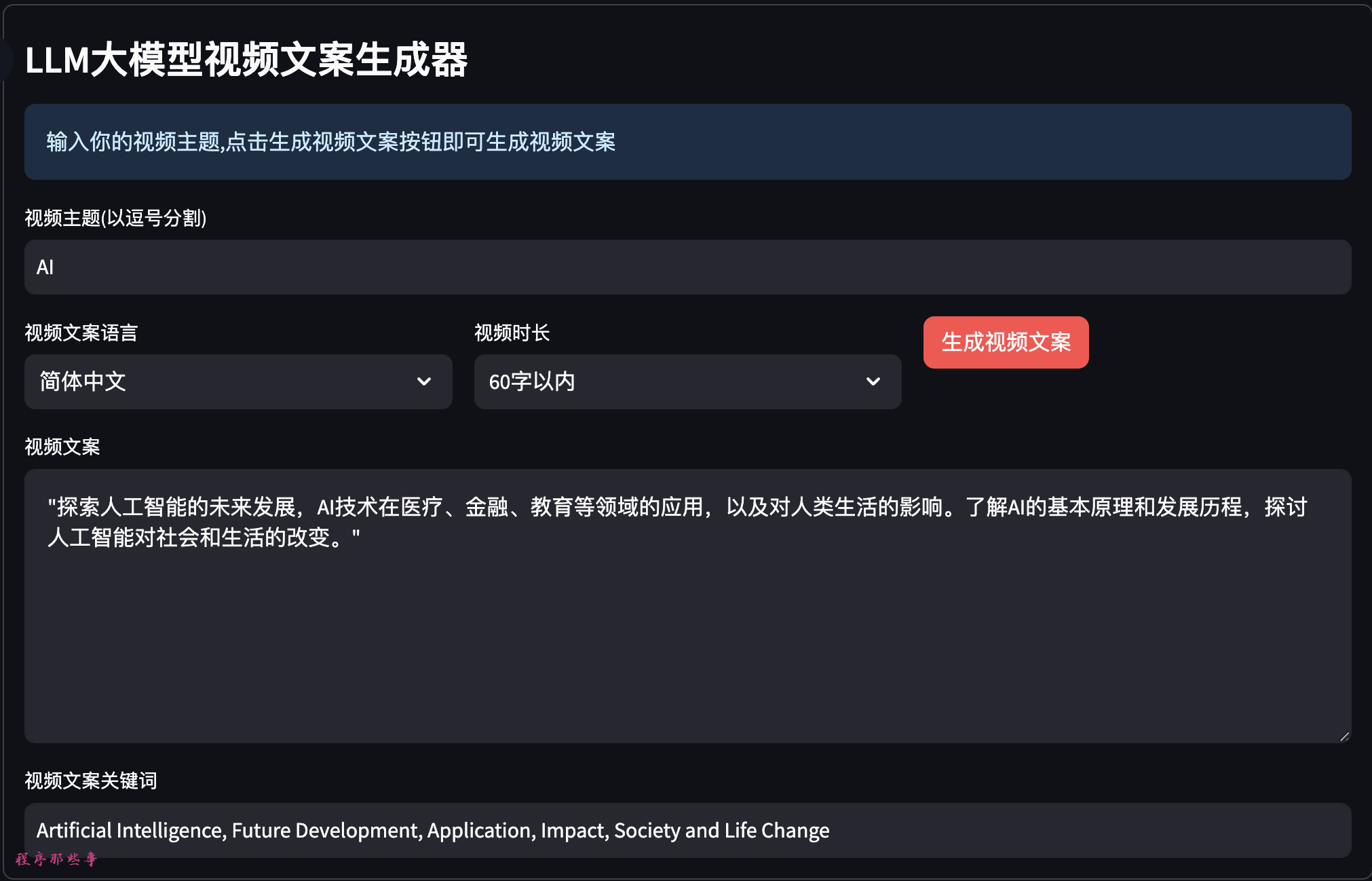
可以选择视频的文案语言,视频时长。
如果大家对视频文案和关键词不满意的话,可以手动修改。
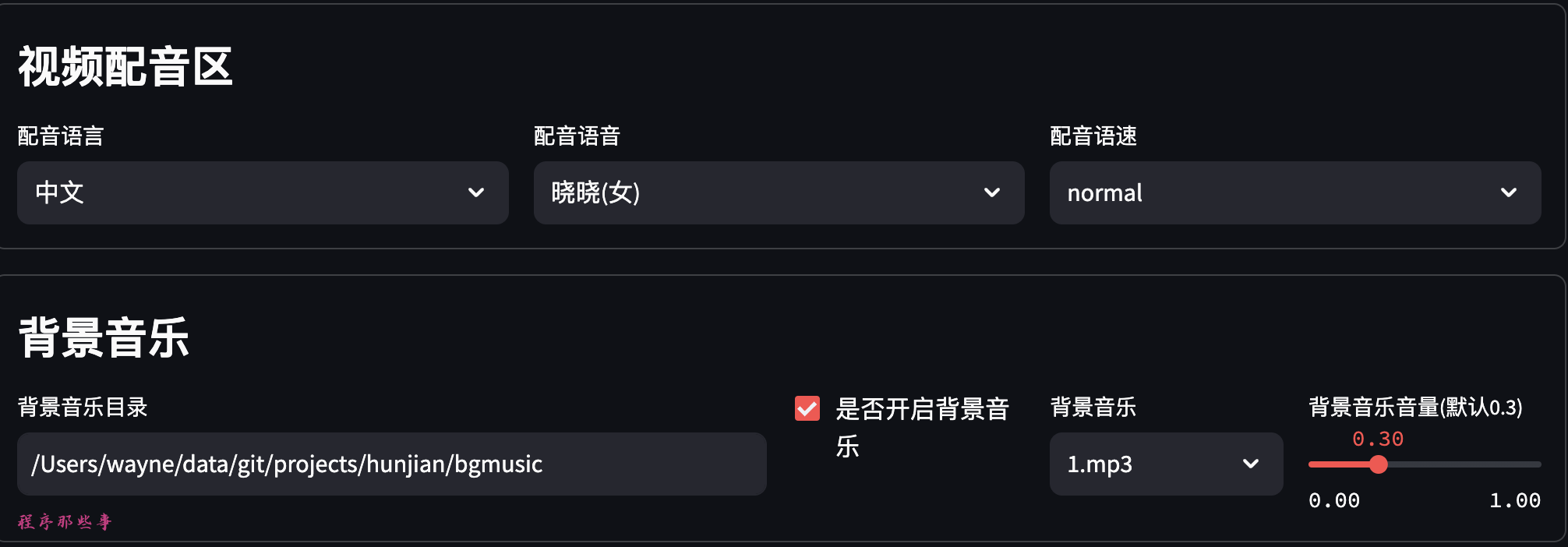
可以选择配音的语言和配音的语音。
还支持配音语速调节。
后续会支持语音试听功能。
背景音乐放在项目的bgmusic文件夹中。
目前里面只有两个背景音乐。大家可以自行添加自己需要的背景应用。
视频配置区,大家可以选择视频的布局,视频帧率,视频尺寸。
视频片段最小长度和最大长度。
还可以开启视频转场效果。目前支持30+转场效果。
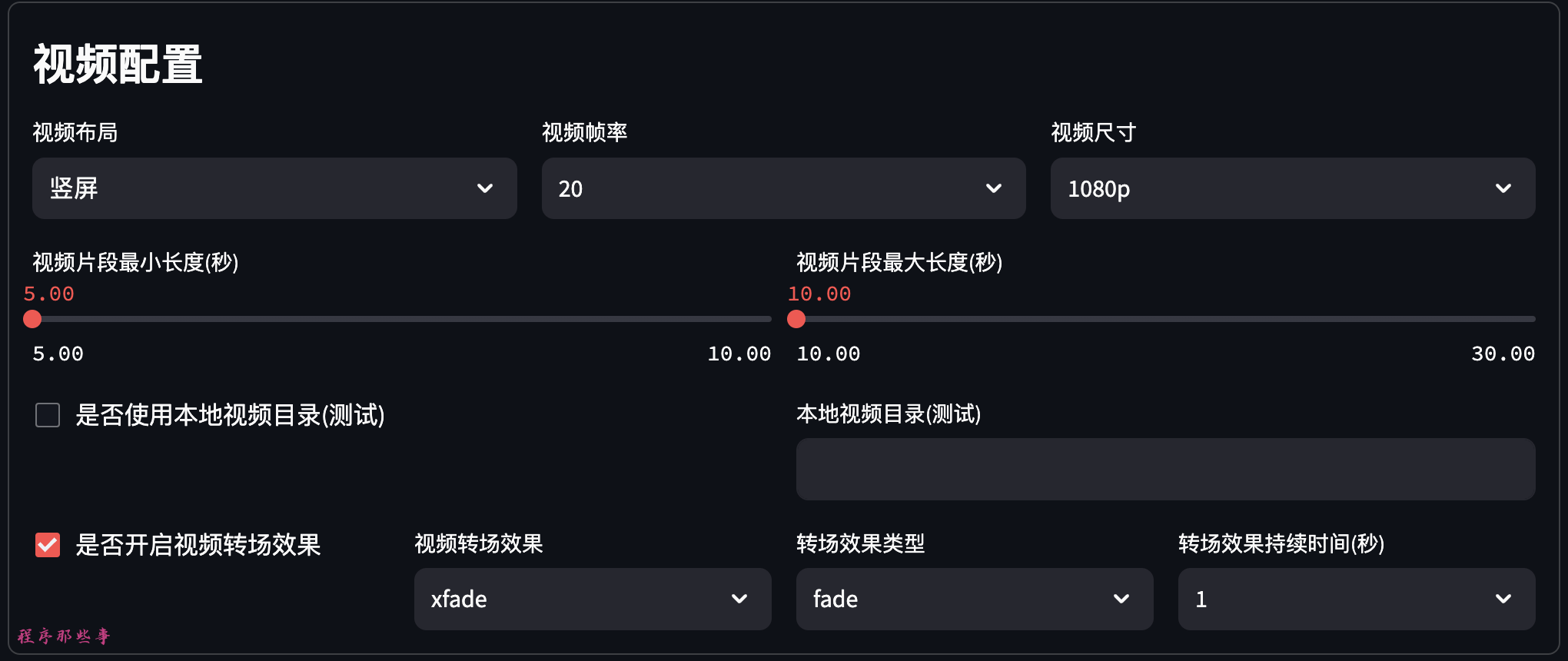
后续会添加使用本地视频资源功能。
字幕文件位于项目根目录的fonts文件夹。
目前支持宋体和苹方两个字体集合。
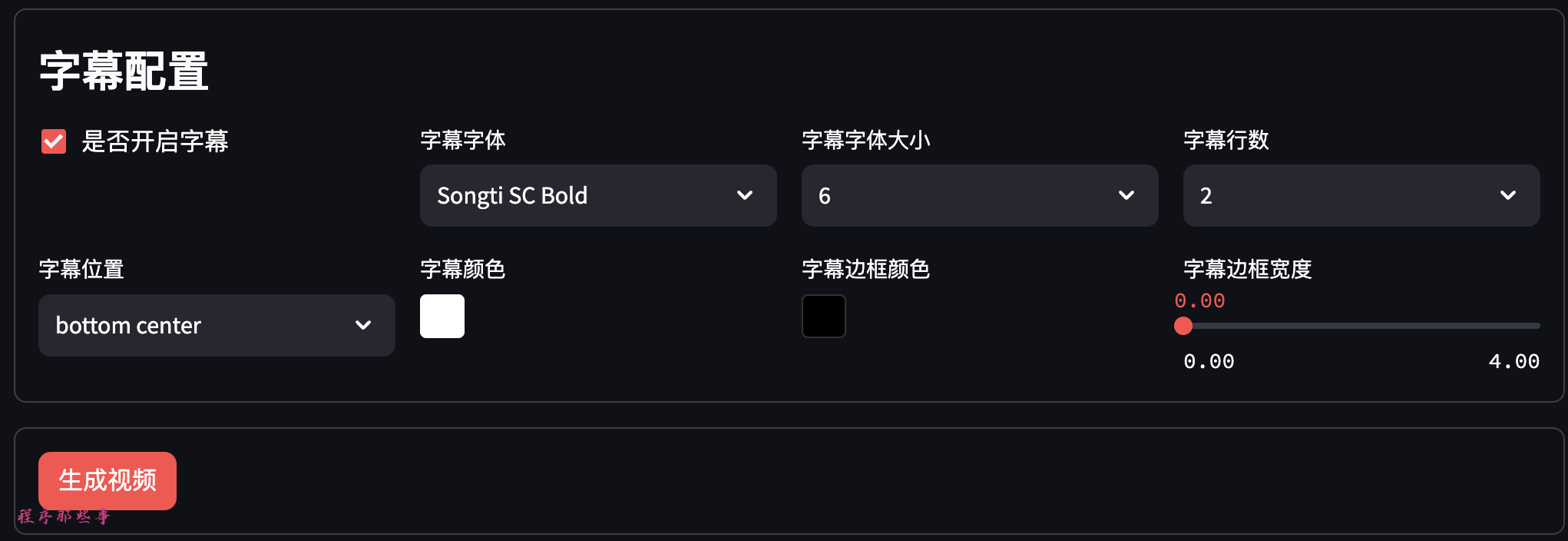
可以选择字幕位置,字幕颜色,字幕边框颜色和字幕边框宽度。
最后,就可以点击生成视频生成视频了。
会在页面上列出具体的步骤名称和进度。
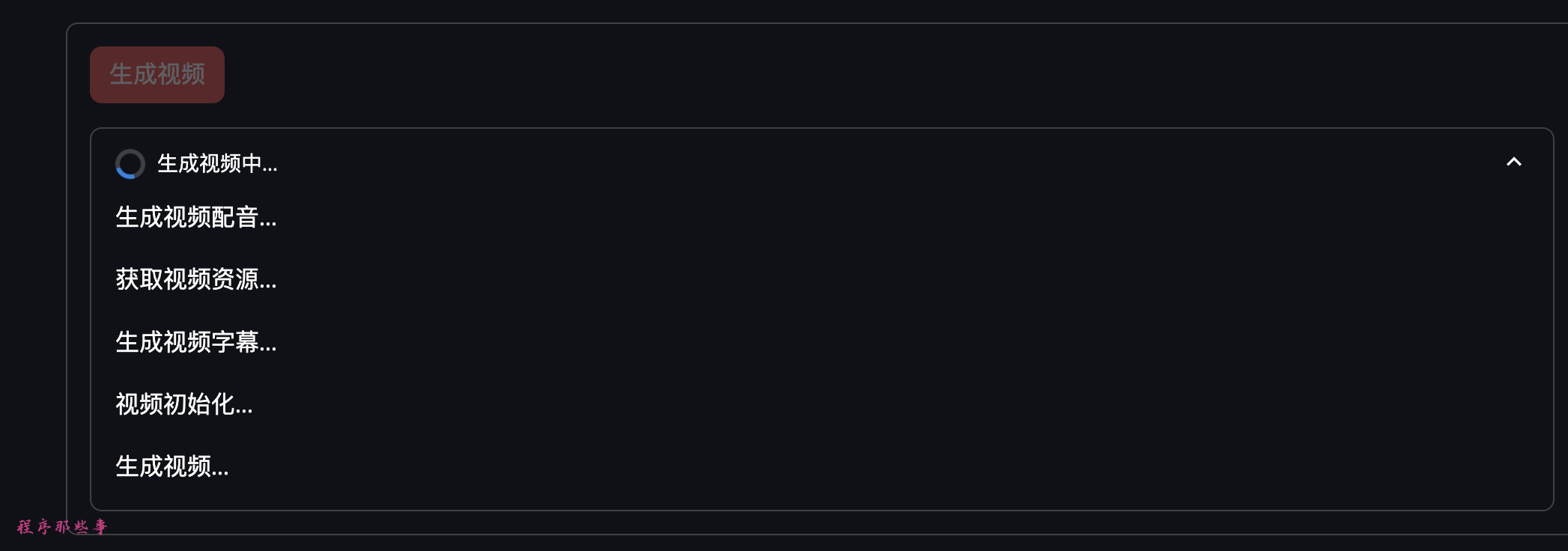
生成视频完成后,视频会显示在最下方,大家直接可以播放观看效果。

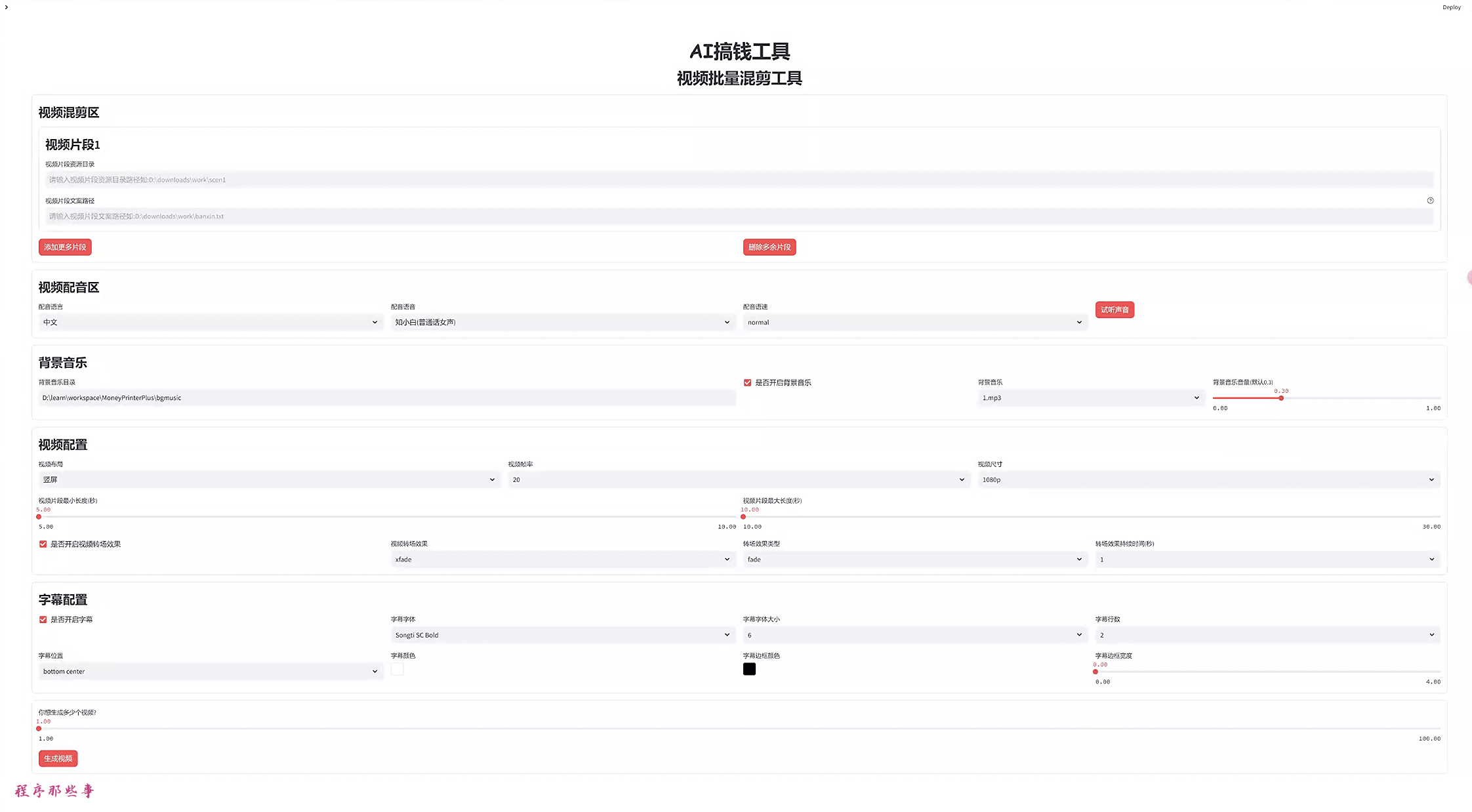
启动项目之后,左上角可以找到视频混剪区。
点击它,进入到视频批量混剪工具页面。
在视频混剪区,我们最多可以配置5个视频片段。
你可以通过点击添加片段或者删除片段来控制片段区域的多少。
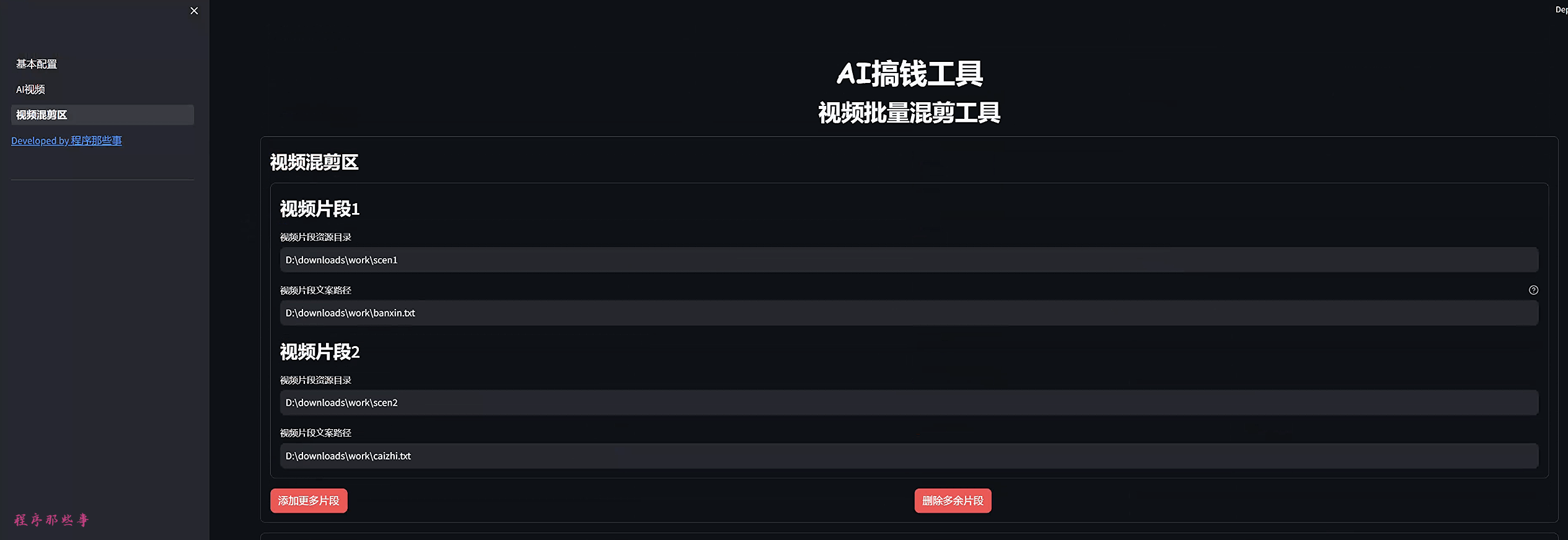
那么有朋友会问了,什么是视频片段呢?
一个长视频,里面不可能只有一个视频主题,可能你的视频前半部分讲的是衣服的版型,后半部分讲的是衣服的材质。
那么衣服的版型就是片段1,材质就是片段2。
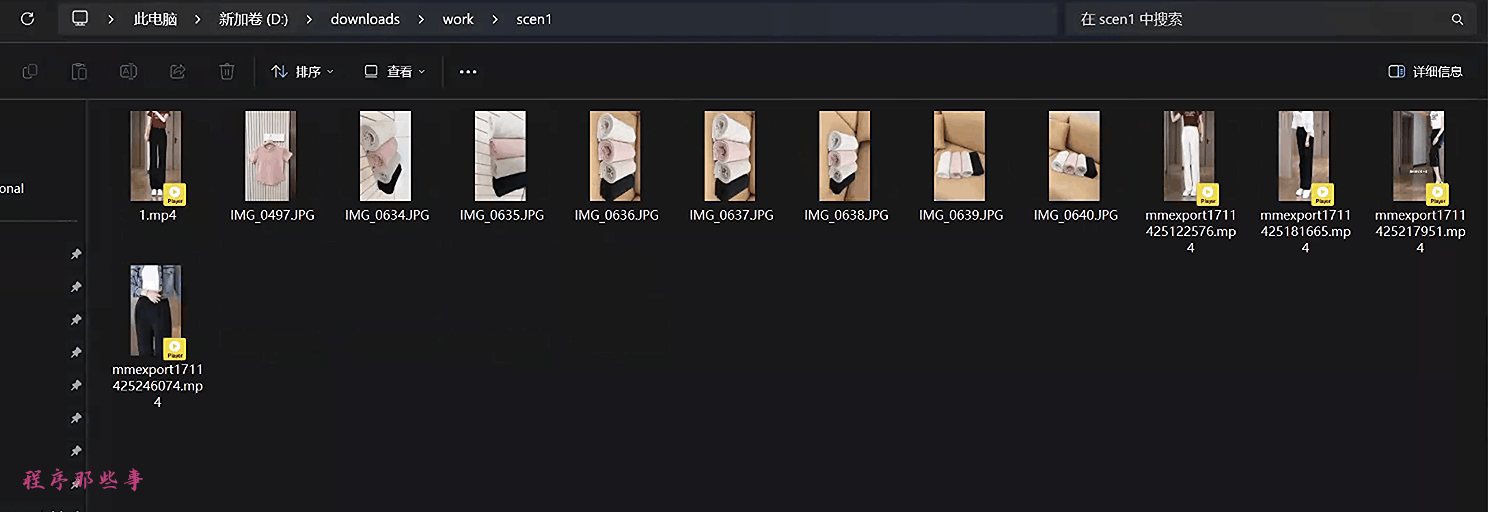
我们要做的就是收集衣服版型的素材,可以是mp4视频,也可以是jpg,png等图片资源。分辨率尽量大一点,否则后面生成的视频质量就不太好。
然后把衣服版型的素材放到视频片段1的资源目录中。
比如上图的资源目录中:
d:\downloads\work\scen1同样的,我们把衣服的材质的素材放到视频片段2的资源目录中。
如下所示:
什么是视频资源文案呢?
视频资源文案就是你需要给这段视频片段配的文字描述。
你可以为一个片段准备很多条文案,然后把这些文案放在一个txt文件中。一条文案放在txt文件中的一行。
系统会随机从txt文件中挑选一行最为最终视频片段的文字描述。
下面是一个文案文件的例子:
精准的剪裁,流畅的线条,这款马甲的版型设计,完美贴合身形,无论是宽松还是修身,都能展现你的优雅姿态。
我们的设计师们,将经典与现代完美融合。每一道线条,每一个剪裁,都是为了展现你的独特身形。
每一刀剪裁,都经过精心计算,只为打造最适合你身形的版型。从肩部线条到腰部剪裁,每一处都彰显着你的独特风格。
精准的剪裁,流畅的线条,这款马甲的版型设计,旨在让每一位穿着者都能感受到定制般的贴合。
精准剪裁流畅线条,马甲版型设计完美贴合身形,宽松或修身皆展现优雅姿态。
设计师将经典与现代融合,每道线条每个剪裁展现独特身形。
精心计算每一刀剪裁,打造适合身形的版型,肩部线条至腰部剪裁彰显独特风格。
剪裁精准流畅,马甲版型旨在定制般贴合,展现穿着者个性魅力。
面料精选剪裁精致,马甲版型以优雅线条展现身形,正式或休闲皆完美。
人体工学设计,马甲版型舒适透气,优雅线条展现身形,每次穿搭成焦点。
经典版型现代演绎,马甲独特剪裁设计,穿着成展现个性品味舞台。
细节精心打磨,马甲版型合体剪裁优雅设计,任何场合自信满满。
舒适型格并存,马甲版型精致剪裁舒适面料,工作休闲展现最佳状态。
时尚马甲版型多样,每款为你而生,经典剪裁现代设计,轻松驾驭各种风格。
优雅线条修身设计,马甲版型考究剪裁精致细节,任何场合成焦点,彰显个人风格。配置好的你的视频片段跟视频文案。
在视频配音区可以选择配音语言和对应的配音语言,目前支持100+配音语言。
还可以选择不同的配音语速,以支持不同使用场景。

如果你对配音不太确定,可以点击试听声音试听对应的配音语音。
背景音乐放在项目下的bgmusic目录下面,你可以自行添加背景音乐文件到该文件夹下面。

可以选择是否开启背景音乐,和默认的背景音乐音量。
视频配置区可以选择视频布局:竖屏,横屏或者方形。
可以选择视频帧率,视频的尺寸。
还可以选择每个视频片段的最小长度和最大长度。
最最重要的,还可以开启视频转场特效。目前支持30+视频转场特效。
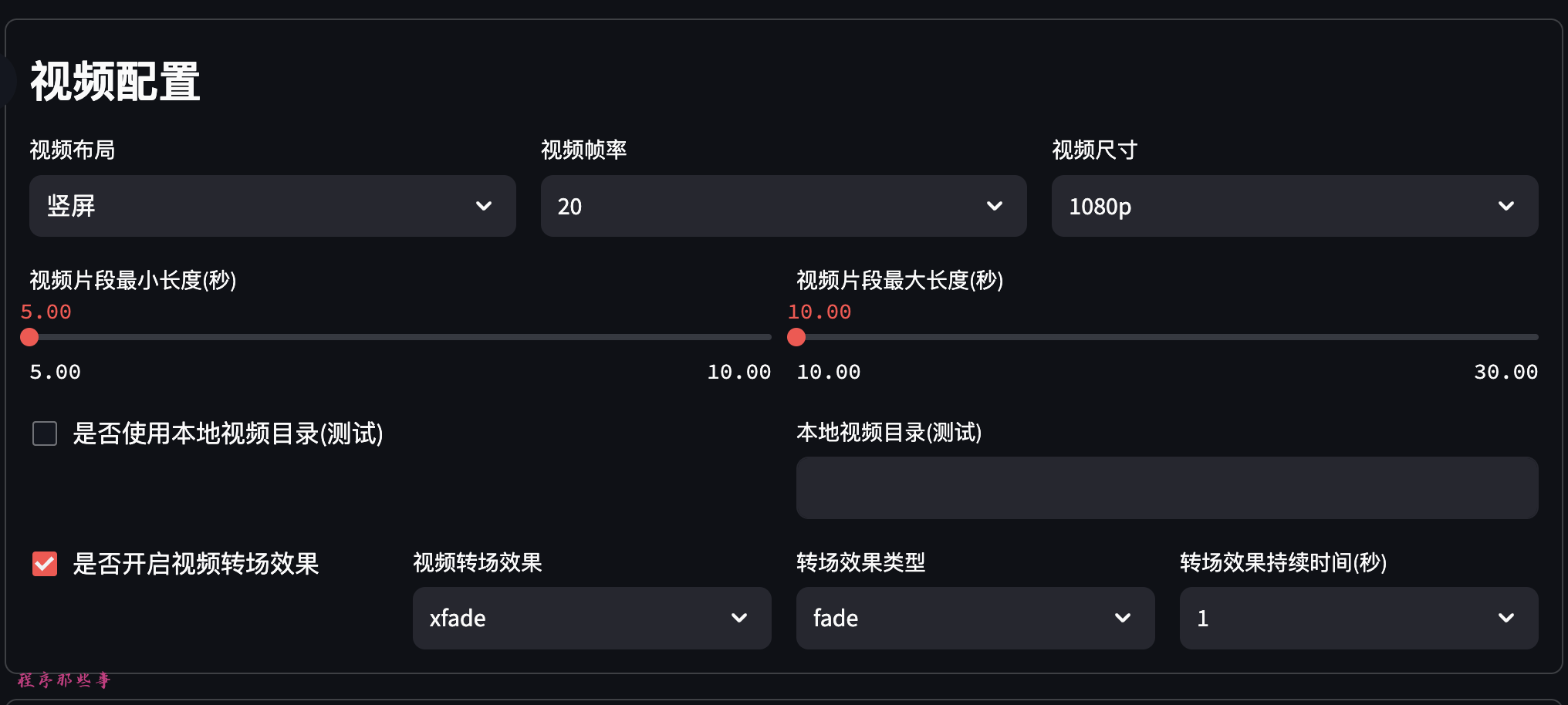
如果你需要字幕,那么可以点击开启字幕选项,可以设置字幕字体,字幕字体的大小和字幕颜色等。
如果你不知道怎么设置,选择默认即可。
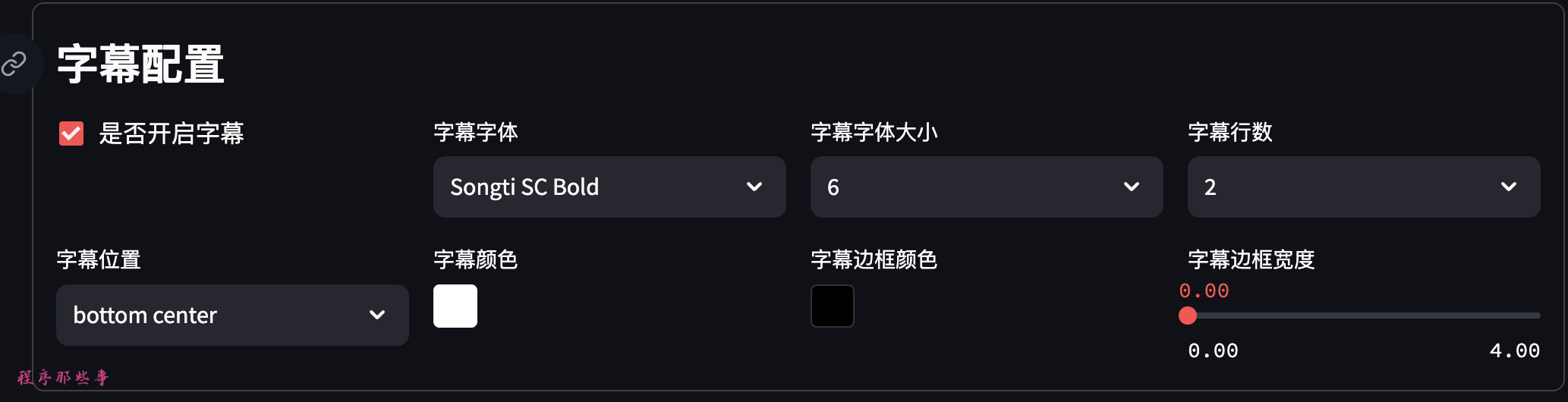
目前系统支持一次批量生成100个视频,根据你自己的需要自行调整。

最后点击生成视频按钮即可生成视频。
页面会有相应的进度提醒。
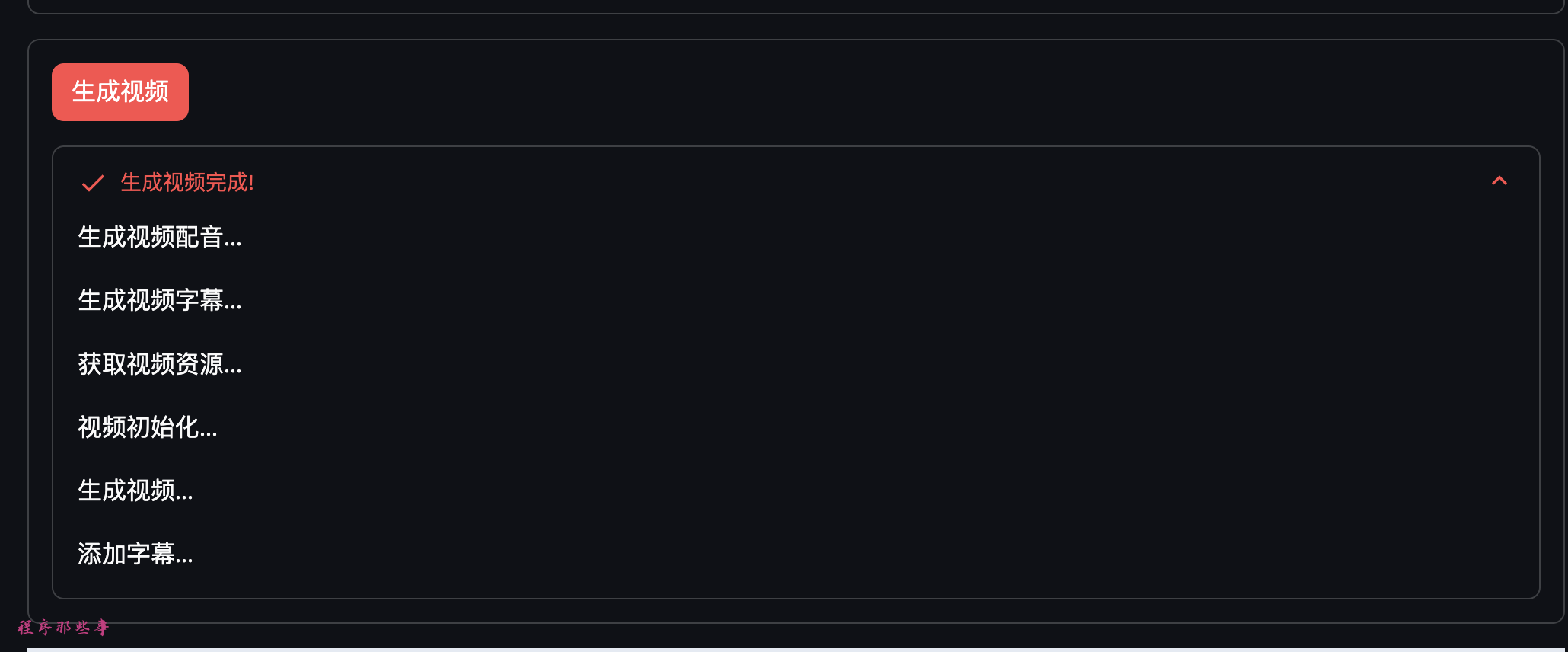
最后生成的视频会展示在页面最下面,大家可以自行播放。
如果你生成了多个视频,可以在项目文件夹的final目录中找到你批量生成的视频。
自动发布工具的本质上是基于selenium这个自动化框架实现的。
通过模拟人工的点击操作,可以完成绝大多数需要人手工才能完成的工作。解放大家的双手。
另外这个自动化的实现方式有两种,一种是在运行程序的过程中启动一个浏览器。另外一种是依附到现有的浏览器上来操作现有浏览器的页面。
本工具选择的是依附到现有的浏览器上。
主要是因为有些视频平台需要用手机扫码二维码才能登录。所以在程序中很难模拟这种登录的过程。
目前自动发布支持chrome和firfox两种浏览器。大家根据需要自行选择一种即可。
现在的主流浏览器肯定是chrome无疑了。所以我们首先聊一聊如何实现对chrome浏览器的支持。
-
首先你需要下载安装Chrome,记住你的版本号,你可以从chrome官网上下载chrome,也可以从这个页面去下载 ChromeDriver下载页面。
-
你需要从ChromeDriver下载页面下载与你的Chrome浏览器版本相对应的ChromeDriver。确保你下载的是与你的操作系统和Chrome版本相匹配的版本。
下载完毕之后,把chromeDriver解压到本地目录,目录的路径最好不要带中文。不能保证能正常运行。
- chrome 以debug模式启动
如果是mac电脑,那么可以先给chrome设置一个alias
alias chrome="/Applications/Google\ Chrome.app/Contents/MacOS/Google\ Chrome"以debug模式启动chrome。
chrome --remote-debugging-port=9222如果你是windows,可以在chrome的桌面快捷方式,右键目标中添加:
--remote-debugging-port=9222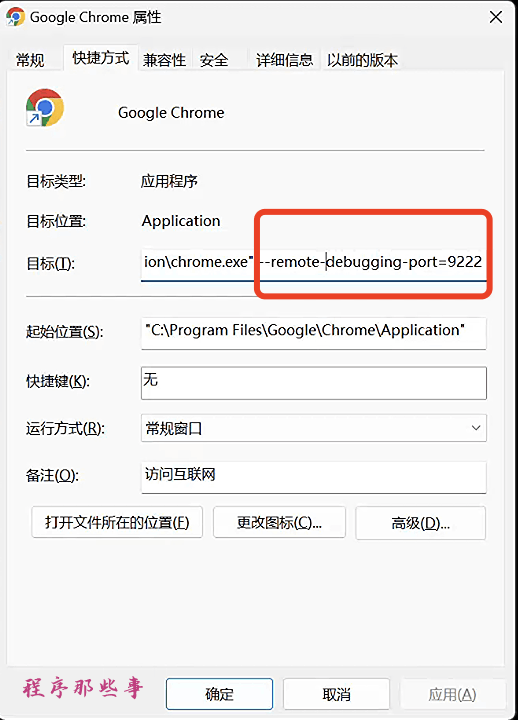
然后双击即可以debug模式打开chrome。
除了chrome之外,用的最多的应该就是firefox了。
所以我们也提供了对firefox的支持。
要想使用firefox,你需要下面几步:
-
下载并安装 Firefox。
-
下载geckodriver 驱动.下载与你的Firefox浏览器版本相对应的geckodriver。确保你下载的是与你的操作系统和Firefox版本相匹配的版本。
下载完毕之后,把geckodriver解压到本地目录,目录的路径最好不要带中文。不能保证能正常运行。
-
以debug模式启动firefox:
和chrome类似,我们在firefox的启动命令之后加上:
-marionette -start-debugger-server 2828
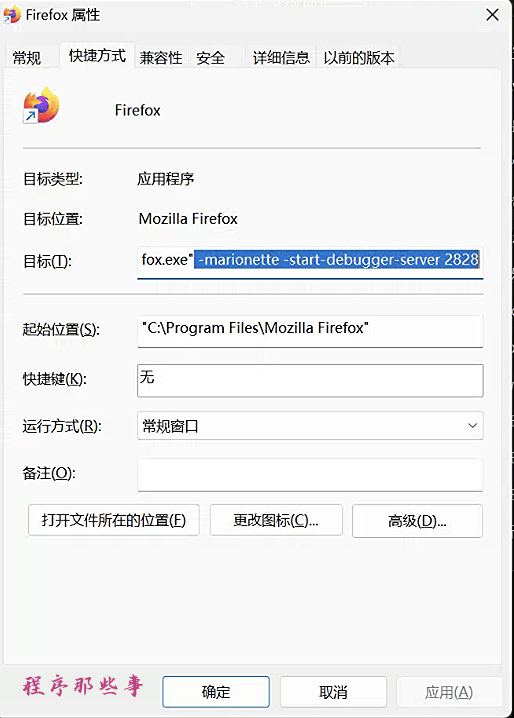
注意,这里的端口一定要是2828,不能自定义。
这时候你如果打开firefox,就会看到导航栏变成了红色,表示你已经启动了远程调试模式。
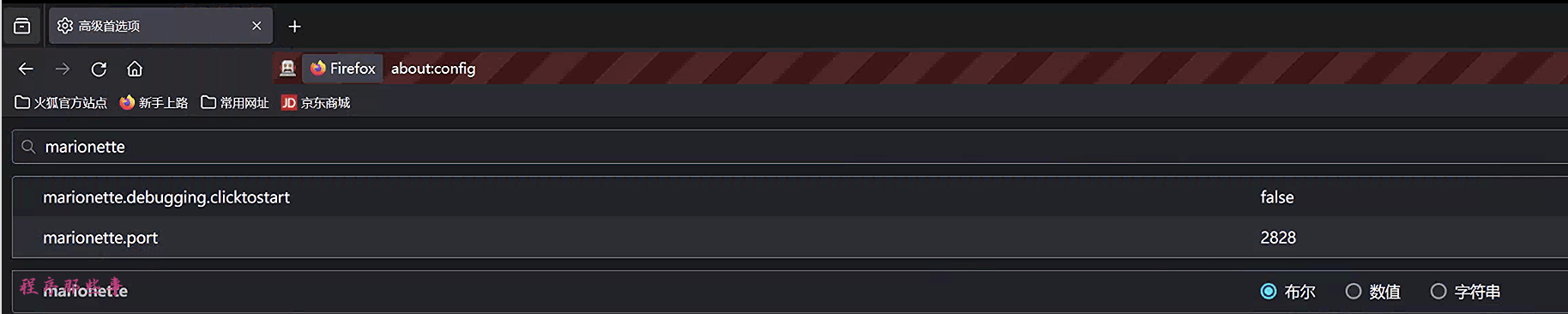
输入about:config
可以看到marionette.port的端口就是2828。
windows环境下,直接双击start.bat即可启动。
mac环境下,在项目根目录下面执行sh start.sh即可。
浏览器会自动打开MoneyPrinterPlus的首页。
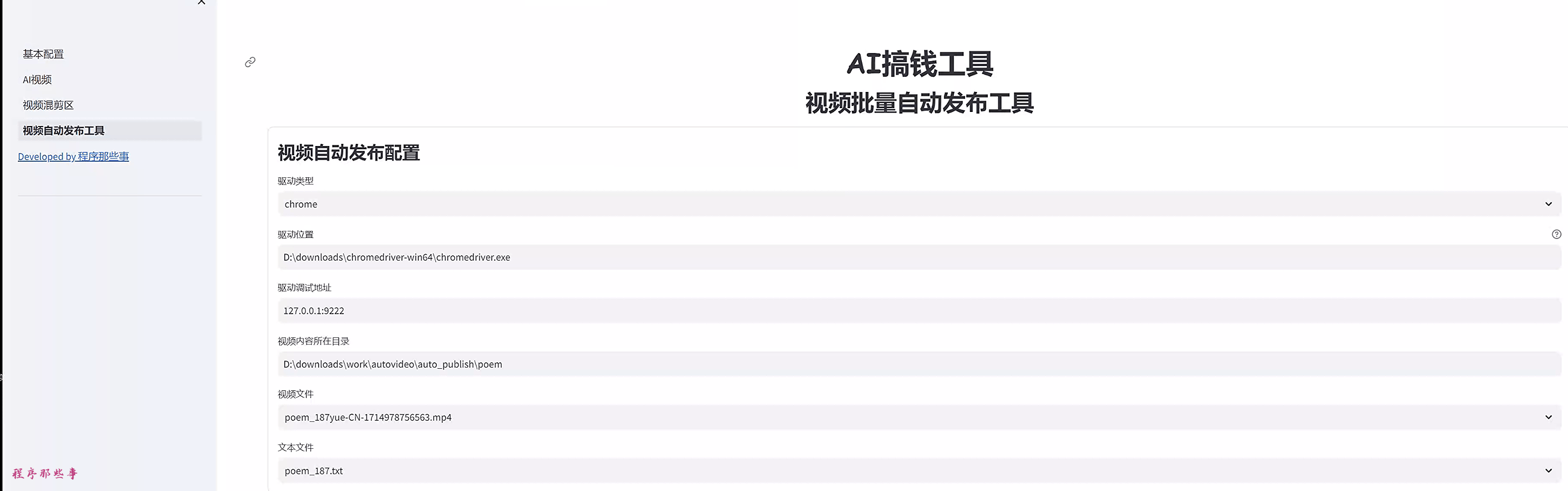
点击左边的视频自动发布工具,可以看到视频自动发布工具的页面。
你可以选择驱动类型。chrome还是firefox。
驱动位置就是之前下载的chromedirver或者geckodriver的位置。
视频内容所在目录,就是你想要发布的视频目录。
当你修改视频目录之后,会自动列出视频目录里面的视频文件和文本文件。
其中视频文件就是你要发布的视频内容。
文本文件是什么呢?
文本文件是和视频配套的文字内容。
举个例子, 我想要发布一个关于唐诗的视频到网站上,那么对应的文本文件内容如下:
王维:酬郭给事
洞门高阁霭馀辉,桃李阴阴柳絮飞。
禁里疏钟官舍晚,省中啼鸟吏人稀。
晨摇玉佩趋金殿,夕奉天书拜琐闱。
强欲从君无那老,将因卧病解朝衣。大家记住,第一行一定是视频的标题。
其他行的内容,大家自由决定。
然后我们看下面的页面:
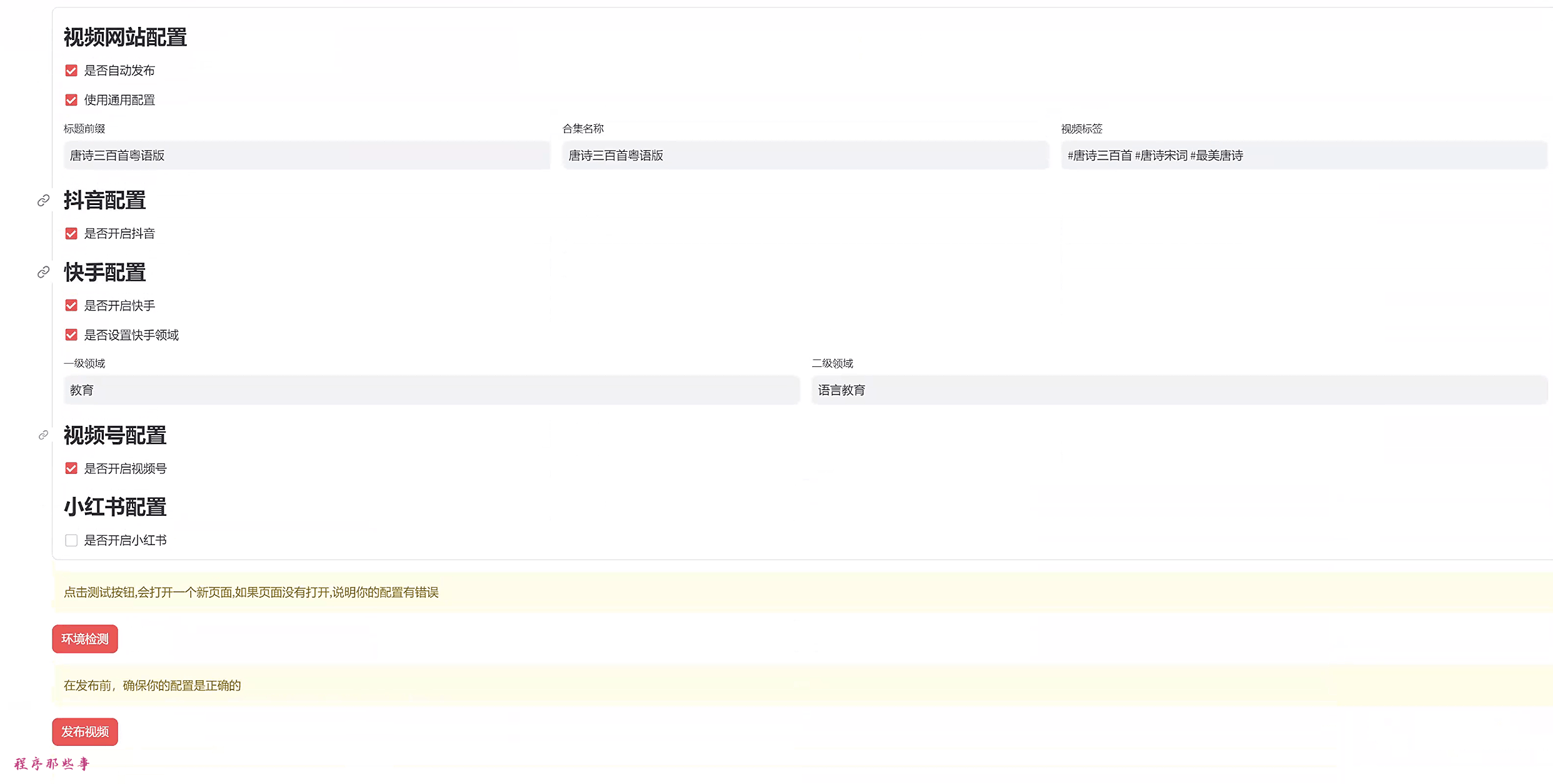
视频网站配置应该很直白了,上过幼儿园的朋友应该都能懂。
标题前缀:如果你需要额外给视频标题添加一些前缀,可以在这里设置。
合集名称:有些视频网站需要选择合集。这里就是合集的名字。(程序不会帮你创建合集,你需要自己提前在网站上创建。)
视频标签:很好理解了,就是标签,用空格分割。
快手还有一个额外的领域配置。
你可以选择是否开启抖音,快手,视频号或者小红书。
接下来就可以准备发布视频了。
但是在发布之前,你可以点一下环境检测。
如果自动打开了我的主页,那么就说明你的环境配置是没问题的。接下来就可以发布视频了。
因为所有的视频网站都需要登录。所以在点击发布视频按钮之前,你需要打开对应的网站,登录你的账号先。
如果你的账号都登录完毕了,点击发布视频按钮吧。
开启你的自由之旅。
运行的界面大概如下:
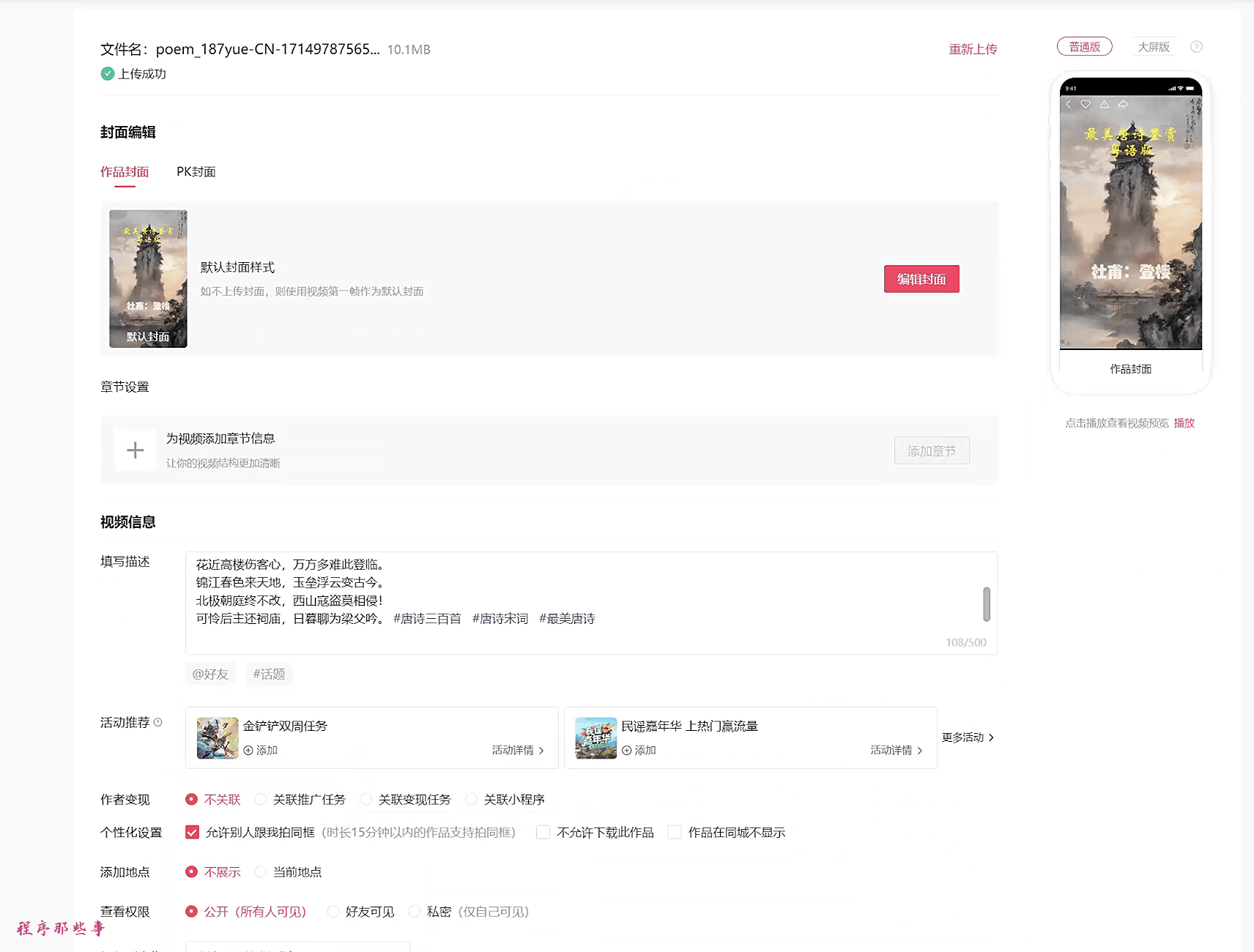
遇到问题的朋友,可以先看看这里的问题汇总,看看能不能解决问题先。
如果大家有什么问题或者想法,欢迎入群讨论。觉得项目不错的朋友可以请作者喝个茶,或者加作者好友私人订制。
| 交流群 | 我的微信 |
|---|---|
 |
 |