For this data set, since the number of data sets is relatively large, the discriminative method yields a smaller loss for both training and validation. When the number of training data is small, the generative model may yield a better result because of the assumption of probability distribution.
HW3 - Image Classification with CNN
Use Convolutional Neural Network for image classification. 11 different classes of images are given.
TensorFlow is used for image processing and model training;
Note: TensorFlow V2.3 is used with command image_dataset_from_directory. The command has a bug (link), which cannot load label lists. Images should be manually seperated by classes into different subdirectories.
Five layers of convolutional layers + max pooling are used, with 3 layers of regular layers after flatten;
After 30 epoches, training accuracy is 96.9%, and validation error is 43.5%. The reason why validation error is low needs further study.
HW4 - Text Classification with RNN and Semi-Supervised Learning (self learning)
Use RNN and self learning for text classification. Output is a binary class, with 1 as positive sentence and 0 for negative sentence;
70% of labelled texts are used as the training data, and the remaining 30% labelled texts are used for validation;
TensorFlow is used for model building and training. Bidirectional LSTM layer is applied as the RNN structure;
For self learning, 0.8 is chosen as the threshold to get pseudo-labels for unlabelled data. For each unlabelled data, if output is larger than 0.8, the data will be labelled as 1; if the output is smaller than 0.2, the data will be labelled as 0. Remaining data will not be labelled/used for training.
In each training, 1,000 unlabelled data will be predicted. After considering possibility threshold, newly labelled data are added into original training data set for training. In this project, 500~600 cases are added to the training set in each epoch.
After 10 epoches of learning without using unlabelled data, the accuracy is 97.3% for training data, and is 74.7% for validation data;
After 10 epoches of self-learning with considering 1,000 unlabelled data, the accuracy is 97.5% for the training data, and is 74.5% for validation data.
Pixel limit for adversarial images is set to 15 for more obvious results;
VGG16 is used as the proxy network;
The predicted label for Image 0 is ground bettle (49.1%) before attack. After attack, the label is cardigan (23.1%);
The predicted label for Image 1 is vase (49.3) before attack. After attack, the label is mosque (24.4%).
HW7 - Network Compression
This homework includes applications of network pruning, knowledge distillation, parameter quantization, and architecture design;
Network pruning: remove less important weights/neurons after training, then fine tune the pruned model;
Knowledge distillation: a smaller 'student' model learns 'everything' output by the 'teacher' model, not only the final output;
Parameter quantization: use less bits or weight clustering to reduce the size of a model (e.g., change weights from float64 to int8);
Achitecture design: by adding intermediate layers, the total number of parameters in a model can be reduced (e.g., depthwise & pointwise CNN);
In Tensorflow, SeparableConv2D layer can be directly used for depthwise & pointwise CNN. The code in the folder is to show how to build complicated architectures in TensorFlow.
HW8 - Seq2Seq Model for Translation
This homework is to use different seq2seq models to translate English to Chinese;
Colab is used to run codes with GPU, all Colab files are uploaded here;
The De-noising autoencoder-decoder model with 2 de-convolution layers (Conv2DTranspose) is used. Image original sizes (32, 32, 3) are embedded into 128-element vectors, then transformed to 2-D vectors by t-SNE;
Original images:
Noised images:
Images output by decoders:
Accuracy in validation set: 70.8%
HW10 - Anomaly Detection
This homework is to detect anomaly with autoencoders. After reconstruction with the trained autoencoder, if the reconstruction error is larger than a setted threshold, the data is considered as an anomaly;
Squared error 200 is set as the threshold. After running, 62/10000 (0.62%) test data is considered as anomaly;
Two models were built for GAN. Model structures are the same, but the training strategies are different. Model 1 used gradients to update parameters directly, and Model 2 used tf.keras.Model.fit and tf.keras.Model.compile instead of using gradients directly;
Both models were trained with 10000 photos and 50 epochs.
Image generated by Model 1:
Image generated by Model 2:
In both models, when using generator or discriminator to predict values, training=True is necessary to activate BatchNormalization layers. Batch normalization layers are important for a large model like GAN. For instance:
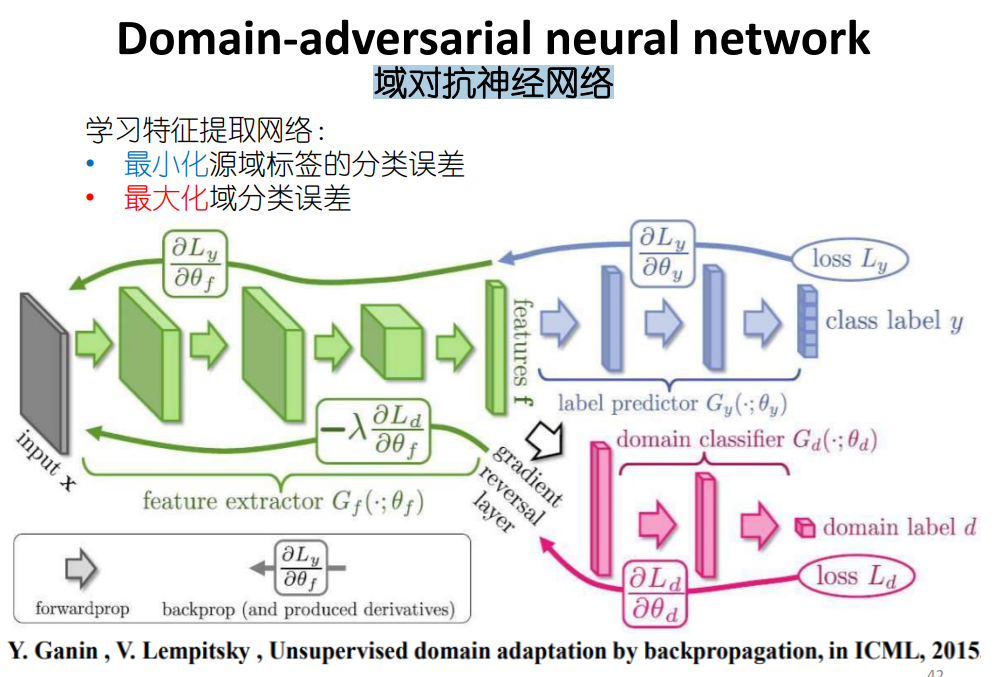
Domain classifier: decide which domain is the feature coming from (from source or target). Target domain is set to 1, and source domain is set to 0;
Target images and source images are preprocessed by PIL: preprocess code
Becasue of limited GPU capacity, the whole network is trained with 15 epochs. The structure works according to a trail with limited data. The code is available for reference [here].(https://github.com/hansxiao7/ML2020/blob/main/HW12/DaNN.ipynb)
The labelling accuracy for source data is 99.0% (4951/5000);
For the first 20 target images, the predicted labels are shown in the following image. Only 35% (7/20) are predicted correctly.
HW13 - Meta Learning
This homework is to apply meta learning. The original task is to change codes with 2nd order gradients to codes with 1st order gradient approximiation;
This homework is to use EWS to achieve lifelong learning;
Task 1: digit recognition on MNIST dataset;
Task 2: digit recognition on SVHN dataset;
The image size for MNIST is (28, 28, 1), and the image size for SVHN is (32, 32, 3). Data preprocessing is conducted first to transfer SVHN data with the same dimension of MNIST data. An ImageNet-like network is built for these two tasks;
Without EWS, the cross-entropy loss table for these two tasks is shown as follows. The model is firstly trained with MNIST data, then trained with SVHN data.
Test on MNIST
Test on SVHN
Random Init.
2.94
2.51
MNIST Trained
0.09
11.89
SVHN Trained
2.43
0.69
With EWS and learning rate for EWS = 10, the cross-entropy loss table for these two tasks is shown as follows:
Test on MNIST
Test on SVHN
Random Init.
2.54
2.64
MNIST Trained
0.08
14.82
SVHN Trained
0.09
4.24
With EWS and learning rate for EWS = 0.001, the cross-entropy loss table for these two tasks is shown as follows: