![]()
Forked from Openchatpaper. An open-source version that attempts to reimplement ChatPDF. A different dialogue version of another ChatPaper project.
本代码库是从Openchatpaper中fork过来。做了部分更改,试图实现基于开源对话模型的 ChatPDF 的版本。 目前的对话模型使用的是Vicuna-13b 8bit版本,文本检索模型使用的是"sentence-transformers/msmarco-distilbert-base-v4",
News
- Sat. Apr.1, 2023: Add some buttons to get some basic aspects of paper quickly.

- Install dependencies (tested on Python 3.9)
pip install -r requirements.txt- Setup and lauch GROBID local server (add & at the end of command to run the program in the background)
bash serve_grobid.sh- Setup backend
python backend.py --port 5000 --host localhost- Frontend
streamlit run frontend.py --server.port 8502 --server.address localhost程序在
Python>=3.9,Ubuntu 20.04下测试,若在其他平台测试出错,欢迎提issue
- 创建一个Python的环境(推荐使用anaconda,关于如何安装请查阅其他教程),创建环境后激活并且安装依赖
conda create -n cpr python=3.9
conda activate cpr
pip install -r requirements.txt-
确保本机安装了java环境,如果
java -version成功放回版本即说明安装成功。关于如何安装JAVA请查阅其他教程 -
GROBID是一个开源的PDF解析器,我们会在本地启动它用来解析输入的pdf。执行以下命令来下载GROBID和运行,成功后会显示
EXECUTING[XXs]
bash serve_grobid.sh
- 开启后端进程:每个用户的QA记录放进一个缓存pool里
python backend.py --port 5000 --host localhost- 最后一步,开启Streamlit前端,访问
http://localhost:8502,在API处输入OpenAI的APIkey(如何申请?),上传PDF文件解析完成后便可开始对话
streamlit run frontend.py --server.port 8502 --server.address localhost- Prepare an OpenAI API key and then upload a PDF to start chatting with the paper.
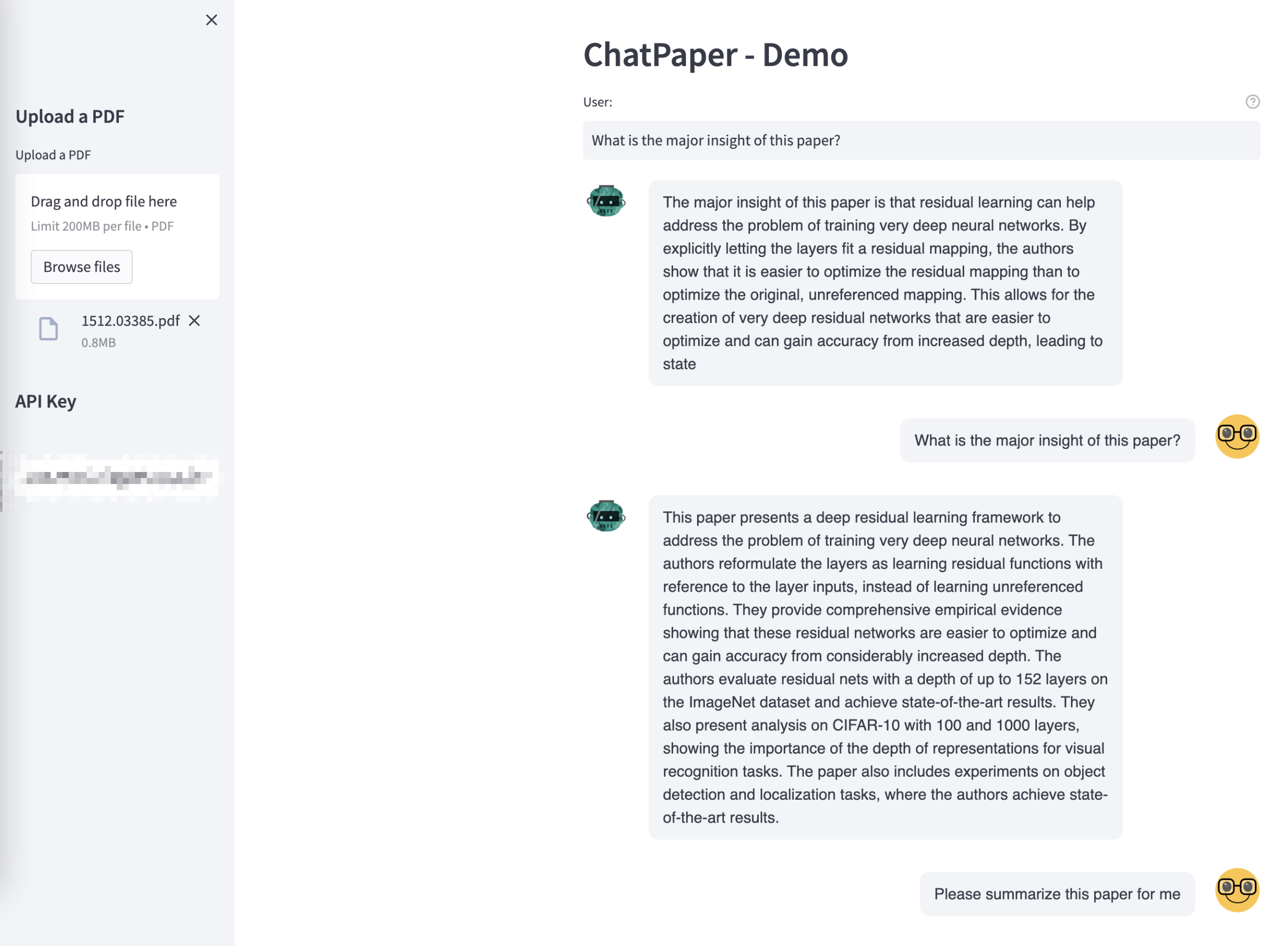
-
Greedy Dynamic Context: Since the max token limit, we select the most relevant paragraphs in the pdf for each user query. Our model split the text input and output by the chatbot into four part: system_prompt (S), dynamic_source (D), user_query (Q), and model_answer(A). So upon each query, we first rank all the paragraphs by using a sentence_embedding model to calculate the similarity distance between the query embedding and all source embeddings. Then we compose the dynamic_source using a greedy method by to gradually push all relevant paragraphs (maintaing D <= MAX_TOKEN_LIMIT - Q - S - A - SOME_OVERHEAD).
-
Context Truncating: When context is too long, we now we simply pop out the first QA-pair.
- Context Condense: how to deal with long context? maybe we can tune a soft prompt to condense the context
- Poping context out based on similarity
- Handling paper with longer pages
Feel free to reach out for possible cooperations or Contributions! (aauiuui@163.com)
- SciPDF Parser: https://github.com/titipata/scipdf_parser
- St-chat: https://github.com/AI-Yash/st-chat
- Sentence-transformers: https://github.com/UKPLab/sentence-transformers
- ChatGPT Chatbot Wrapper: https://github.com/acheong08/ChatGPT
- Openchatpaper https://github.com/liuyixin-louis/ChatPaper
- langchain-ChatGLM https://github.com/imClumsyPanda/langchain-ChatGLM
- Vicuna https://github.com/lm-sys/FastChat