Memcached is a high performance, multithreaded, event-based key/value cache store intended to be used in a distributed system. It is generic in nature, but is used in speeding up dynamic web applications by alleviating database load. It is generally used for small chunks of arbitrary data (strings, objects) from results of database calls, API calls, or page rendering.
Here are some of the supported features of this implementation of memcached server:
-
Supports only the memcached text protocol, specifically get and set operations. The flags, exptime, and (optional) noreply parameters are accepted but not used.
-
The TCP listening port is 11211 by default. It can be overriden by providing "http.port" in a json configuration file and passing it to the jar.
-
The get command is only for one key. Multi-key get is not supported
-
There is a limit to key size (256 bytes) and value size (1024 bytes) in this implementation. This limit is to allow 100,000 LRU cache entries, which together take up, at max 128 MB of memory. This is configurable by modifying the Constants.
-
The eviction policy used is LRU. It is easy to extend this to other policies in the future
To launch tests:
./gradlew clean testTo package application:
./gradlew clean assembleRunning the memcached server:
Build the fat jar:
$ ./gradlew build
Run the memcached server:
$ java -jar ./build/libs/memcache-1.0.0-SNAPSHOT-fat.jar -conf src/main/conf/conf.json
Run the memcached client:
$ telnet localhost 11211
set abc 0 0 5
hello
STORED
get abc
VALUE abc 0 5
hello
ENDConfiguration file format:
{
"tcp.port" : 11211
}In case of a timeout issue talking to a local port (or if the tests time out) on a Mac:
Modify the /etc/hosts file to include Computer name. Computer name can be
obtained from System Preferences → Sharing
The /etc/hosts file should look like:
##
# Host Database
#
# localhost is used to configure the loopback interface
# when the system is booting. Do not change this entry.
##
127.0.0.1 localhost computer-name
255.255.255.255 broadcasthost
::1 localhost computer-nameFor our server implementation, we took several design decisions and made tradeoffs. Emphasis was placed on trying to keep code simple and performant, while leveraging several available frameworks (most notably: Concurrent LRU cache implementation, and a high performant async io framework). Here we try to enlist some of the decisions we took
We chose to implement the server using Vert.x framework. Vert.x is a lightweight, high performance application platform for the JVM.
The advantages of a reactive framework are:
-
Responsive : the system responds in an acceptable time;
-
Elastic : the system can scale up and scale down;
-
Resilient : the system is designed to handle failures gracefully;
-
Asynchronous : the interaction with the system is achieved using asynchronous messages;
We considered other alternatives such as using Dropwizard framework or Netty TCP client.
-
-
Vertx performs better than Dropwizard under heavy load. This means Vert.x lets our app scale with minimal hardware.
-
Dropwizard is suitable for applications which handle less QPS.
-
CPU utilisation rate is better in Vertx than in Dropwizard.
-
Vertx is able to handle more requests per second and has low memory footprint.
-
-
-
Vertx is built on top of Netty. Netty is more low level and does not support the many languages that Vertx supports. So, multiple verticles (think of them as servlets) can be written in different languages.
-
Vertx allows user to build richer reactive APIs.
-
Vert.x provides a non-blocking, event-driven runtime. If a server has to do a task that requires waiting for a response (e.g. requesting data from a database) there are two possibilities how this can be implemented: blocking and non-blocking.
- Blocking
-
The traditional approach is a synchronous or blocking call. The program flow pauses and waits for the answer to return. To be able to handle more than one request in parallel, the server would execute each request in a different thread. The advantage is a relatively simple programming model, but the downside is a significant amount of overhead if the number of threads becomes large.
- Non-blocking
-
The second solution is a non-blocking call. Instead of waiting for the answer, the caller continues execution, but provides a callback that will be executed once data arrives. This approach requires a (slightly) more complex programming model, but has a lot less overhead. In general a non-blocking approach results in much better performance when a large number of requests need to be served in parallel.
Vertx chooses the non-blocking model where events are picked up by an event loop to process them.

A Vert.x application consists of loosely coupled components, which can be rearranged to match increasing performance requirements.
An application consists of several components called Verticles, which run independently. A Verticle runs a single thread and communicates with other Verticles by exchanging messages on the global event-bus.
Because they do not share state, Verticles can run in parallel. The result is an easy to use approach for writing multi-threaded applications. You can create several Verticles which are responsible for the same task and the runtime will distribute the workload among them, which means you can take full advantage of all CPU cores without much effort.
Verticles can also be distributed between several machines. This will be transparent to the application code. The Verticles use the same mechanisms to communicate as if they would run on the same machine. This makes it extremely easy to scale your application.
The Vert.x event bus is the main tool for different verticles to communicate through asynchronous message passing.
For instance suppose that we have a verticle for dealing with HTTP requests, and a verticle for managing access to the database. The event bus allows the HTTP verticle to send a request to the database verticle that performs a SQL query, and responds back to the HTTP verticle:

In our memcache server implementation, we define two verticles:
- Command Verticle
-
This is the verticle that starts a TCP server, and processes the incoming data from the client. It is responsible for validating the input, parsing the input command, and forwarding the command (and its parameters) to the vertx global event bus. It also processes the response back from the event bus and responds back to the client.
- Cache Verticle
-
This verticle is responsible for performing the cache related functions, such as get and put. It reads messages off the event bus, and performs the operation, and writes the messages back to the event bus.
By separating our code into two separate verticles, the advantages we gain:
-
The verticles provide better debuggability and scalabilty as they can scale independently & indicates a separation of concerns.
-
In multi-core systems, we can have multiple instances of each type of verticle. This allows us, for example, to have multiple command verticles and a single cache verticle. This would be useful if we are dealing with a surge in incoming load.
These reasons give Vertx an edge over other frameworks for high performance applications such as Dropwizard & Netty.
Another design decision we took was having an LRU policy for cache eviction. LRU means that the Least Recently Used entry in the cache is evicted to make space for the more recent entry. A very basic implementation of LRU would use a LinkedList which tracks the order of accesses, and a HashMap to avoid traversing the List to update an entry. In Java, a LinkedHashMap contains both these properties.
-
LinkedHashMap:
LinkedHashMap provides a convenient data structure that maintains the ordering of entries within the hash-table.
This is accomplished by cross-cutting the hash-table with a doubly-linked list, so that entries can be removed or reordered in O(1) time. When operating in access-order an entry is retrieved, unlinked, and relinked at the tail of the list. The result is that the head element is the least recently used and the tail element is the most recently used. When bounded, this class becomes a convenient LRU cache.
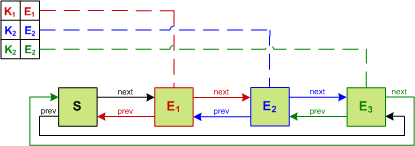
The problem with this approach is that every access operation requires updating the list. To function in a concurrent setting the entire data structure must be synchronized.
-
Lock Amortization
An alternative approach is to realize that the data structure can be split into two parts: a synchronous view and an asynchronous view. The hash-table must be synchronous from the perspective of the caller so that a read after a write returns the expected value. The list, however, does not have any visible external properties.
This observation allows the operations on the list to be applied lazily by buffering them. This allows threads to avoid needing to acquire the lock and the buffer can be drained in a non-blocking fashion. Instead of incurring lock contention, the penalty of draining the buffer is amortized across threads. This drain must be performed when either the buffer exceeds a threshold size or a write is performed.
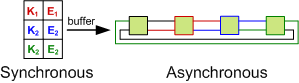
This is the basis of the ConcurrentLinkedHashMap The default policy in this implementation is LRU which can be implemented with O(1) time complexity. We have used LRU in our implementation.
We made several design tradeoffs in our implementation, most of them are easy to implement.
- Multiple Instances of Verticles
-
Our implementation uses one instance each of Cache Verticle and Command Verticle. This works well in a 2-core system. Most of the modern systems have multiple cores. We can extend our code to instantiate multiple instances of these verticles, thereby fully leveraging the parallelism offered by multi-core systems.
- Distributed Memcached
-
The current implementation works on a single node. To support a distributed memcache server, we can write a client that performs a distributed lookup and insert. We would use Consistent Hashing methods, such as those used in Chord, Pastry to forward requests from the clients to appropriate memcached server nodes, each running their own local cache. This will allow elastic scale by use.
- LRU cache based on weight, instead of number of elements
-
The current implementation of LRU cache takes in the number of cache entries and evicting the least recently accessed. Instead, we could have a policy which takes in the size of the entry into account, which will allow us to have variable sized entries, and we dont have to place a limit on the key/value size.
This implementation would be in the following way, by using the Jamm library to get the exact size of objects in JVM:
EntryWeigher<K, V> memoryUsageWeigher = new EntryWeigher<K, V>() {
final MemoryMeter meter = new MemoryMeter();
@Override public int weightOf(K key, V value) {
long bytes = meter.measure(key) + meter.measure(value);
return (int) Math.min(bytes, Integer.MAX_VALUE);
}
};
ConcurrentMap<K, V> cache = new ConcurrentLinkedHashMap.Builder<K, V>()
.maximumWeightedCapacity(1024 * 1024) // 1 MB
.weigher(memoryUsageWeigher)
.build();- Beyond LRU
-
The least recently used policy provides a good reference point. It does not suffer degradation scenarios as the cache size increases, it provides a reasonably good hit rate, and can be implemented with O(1) time complexity.
However, an LRU policy only utilizes the recency of an entry and does not take advantage of its frequency. The Low Inter-Reference Recency Set Replacement policy does, while also maintaining the same beneficial characteristics. This allows improving the hit rate at a very low cost.
We can also use the Google Guava Cache instead of the ConcurrentLinkedHashMap. It provides different eviction algorithms which take care of specific use cases such as streaming data.
- Dockerize the server
-
Ideally, we would’ve preferred dockerizing this vertx application. Dockerizing the gradle application would allow any user to pull docker images and run it on any machine.
- Use mockito for unit testing
-
Current testing strategy covers 100% of the code lines, we have Command & Cache verticle tests and LRU cache test. In the future, we would like to evaluate mocking an event bus for writing even smaller units of tests.
- Extensibility
-
Features that can be added to our implementation with relatively few changes:
-
Get multiple keys
-
Set flag & expTime in value cached
-
Support noreply optional parameter
-