
Welcome to rag_bot, a powerful solutions accelerator for building enterprise apps with adaptive intelligence. Rooted in a tool-using agenic architecture and retrieval augmented generation (RAG), rag_bot seamlessly integrates state-of-the-art open-source frameworks such as LangChain, LlamaIndex, and FastAPI. This platform is containerized, primed for Infrastructure as Code (IaC) deployments, and harnesses the scalability and advanced filtering capabilities of the Qdrant vector database. Dive into building intelligent applications with rag_bot at your side!
rag_bot isn't just a project; it's an innovation accelerator. With a focus on enabling developers like you, here's what you can achieve:
- Dynamic Conversations: Powered by vast language models, your bots can hold enriched conversations like never before.
- Knowledge Access: Retrieve pertinent information from custom knowledge reservoirs, making your bots more informed.
- Immediate Development: You don't need to wait. You can dive right in! Load content into techdocs, test out chatting on that content, and then start pioneering custom tools for your use case!
With rag_bot, you're not bound by limitations. The platform is your canvas:
- Data Integration: Bring in new data sources, be it databases or internal documents.
- Model Experimentation: Choose the language model that fits your narrative.
- Tool Development: Extend the agent's capabilities. Integrate calendars, fetch weather data, or even add translation services.
- Prompt Refinement: Customize the bot's persona, ensuring it aligns with your vision.
- Ready-to-Use & Extensible UI: rag_bot features a basic Gradio UI for chat demos, primed for integration with your custom frontend.
- Seamless API Integration: With FastAPI at its core, integrate effortlessly with other services.
Your chatbot can be as unique as your vision. Customize, adapt, and let your creativity soar.
Ready to revolutionize conversational agents? The subsequent sections guide you through the journey, right from prerequisites to deployment. Get to know the architecture, explore features, and tailor the platform to your needs. The world of advanced conversational agents awaits you.
To use this project, you will need:
- Docker and Docker Compose installed
- Python 3.7+
- An OpenAI API key
To set up the project:
-
Clone this repository to your local machine.
-
Rename
key.env.exampletokey.envand add your OpenAI API key. -
In
docker-compose.yml, update thevolumespath forRAG_BOT_QDRANTto a local folder where you want persistent storage for the vector database. -
Create needed directories for persistant storage
mkdir -p .data/qdrant/
-
Build the Docker images:
docker-compose build
-
Start the services:
docker-compose up -d
The services will now be running.
Once the Docker containers are up and running, you can start interacting with the bot via:
- The interactive Swagger docs at http://localhost:8000/docs
- The Gradio Chat Interface at http://localhost:7860
- The Qdrant Web Interface at http://localhost:6333/dashboard
-
Scrape Documents:
- Go to the FastAPI server by navigating to the interactive Swagger docs at http://localhost:8000/docs.
- Use the
scrapeendpoint to scrape content from a specified URL. You will need to provide the URL you want to scrape in the request body. - The
scrapeendpoint will return the scraped content which will be processed in the next step.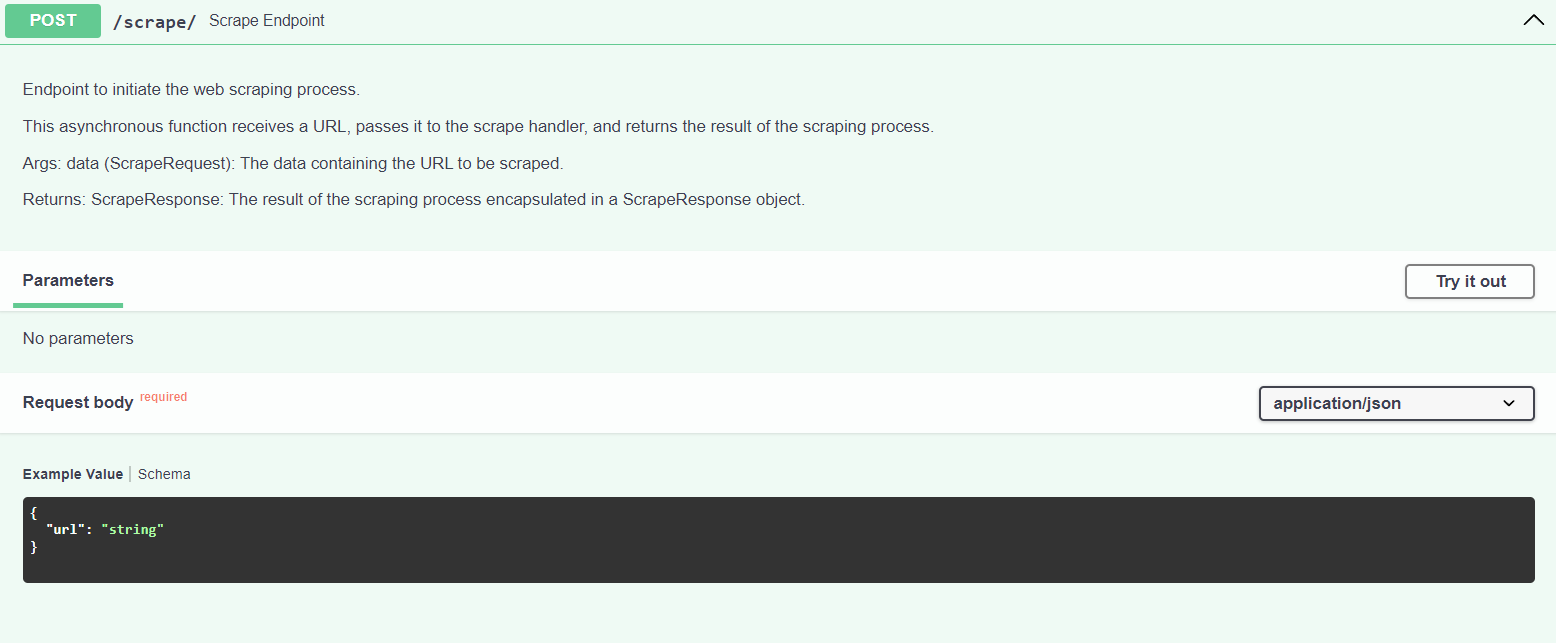
-
Create a Vector Index:
- Use the
process-documentsendpoint to create a vector index from the scraped content. - In case the
techdocscollection does not exist, theprocess-documentsendpoint will create one for you. - This endpoint will process the scraped documents, create a vector index, and load it into Qdrant.
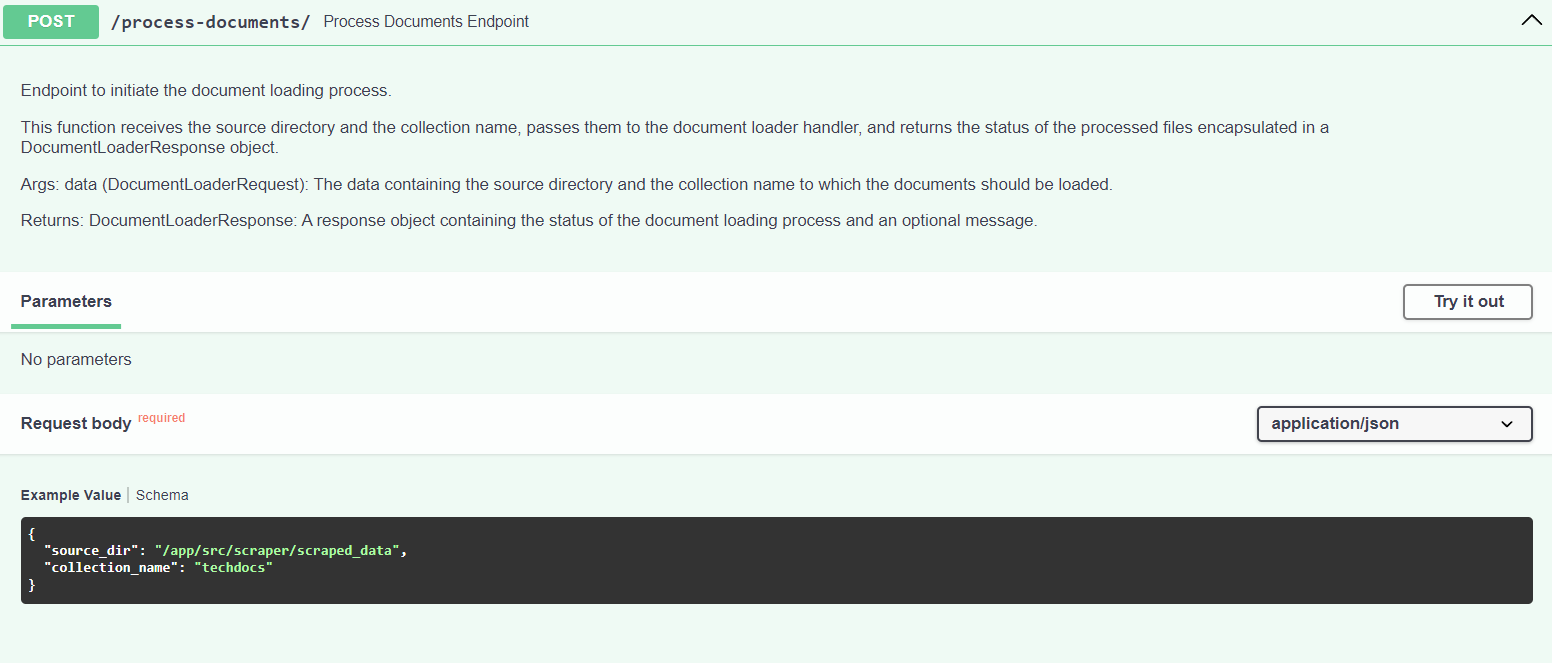
- Use the
-
Interact with Processed Documents:
- Now that the documents are processed and loaded into Qdrant, you can start interacting with them.
- Try chatting with the documents via the Gradio Chat Interface at http://localhost:7860.
- The bot should automatically check the
techdocscollection for technical information while responding to your queries. If it doesn't, you can instruct the bot by typing "check techdocs" in the chat interface.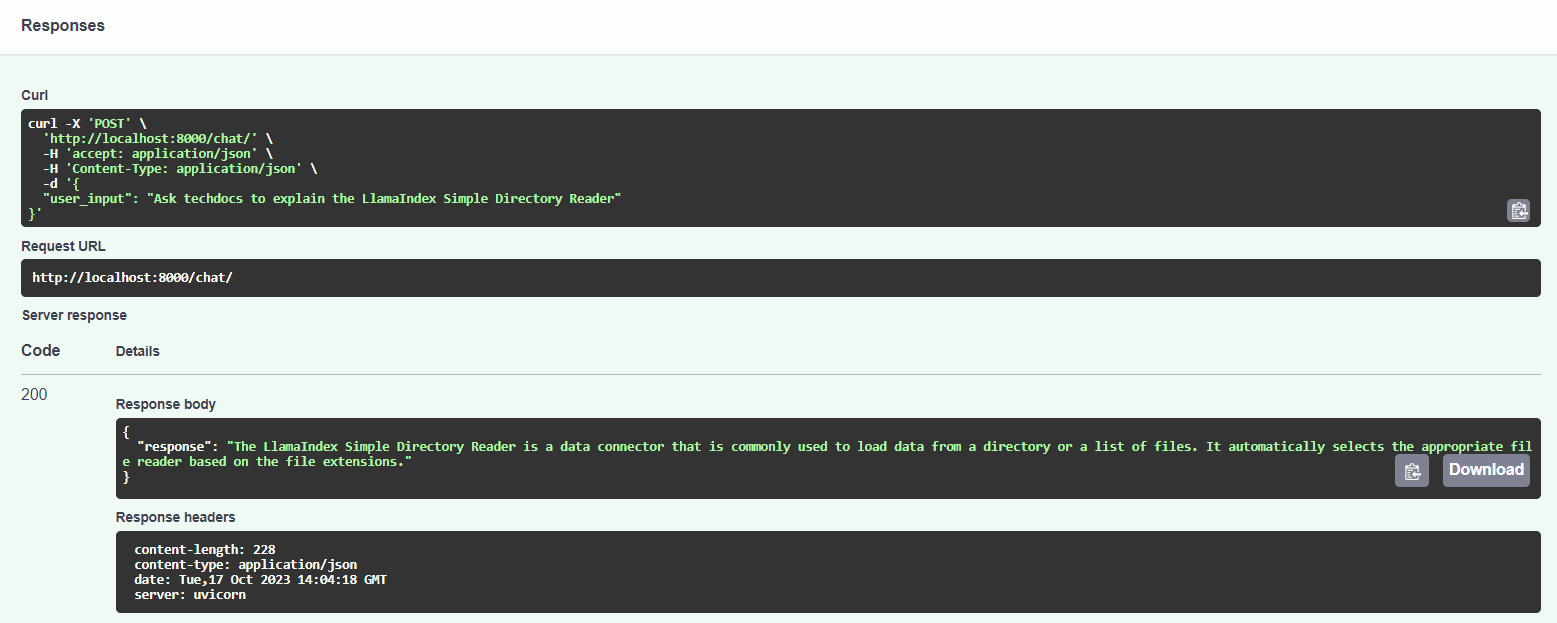



The rag_bot architecture consists of the following key components:
- FastAPI - High performance REST API framework. Handles HTTP requests and routes them to application logic.
- Gradio - Interface for interacting with the bot via GUI.
- Qdrant - Vector database for storing document embeddings and enabling similarity search.
- AgentHandler - Orchestrates the initialization and execution of the conversational agent.
- Scraper - A tool that scrapes a web page and converts it to markdown.
- Loader - A tool that loads content from the scrped_data directory to a VectorStoreIndex
- Tools - Custom tools that extend the capabilities of the agent.
Let's take a closer look at some of the key bot infrastructure components:
FastAPI provides a robust web framework for handling the API routes and HTTP requests/responses.
Some key advantages:
- Built on modern Python standards like type hints and ASGI.
- Extremely fast - benchmarked to be faster than NodeJS and Go.
- Automatic interactive docs using OpenAPI standards.
In this project, main.py initializes the application and sets up the /chat endpoint which is the gateway for users to interact with the bot. Functionality can be tested directly via the docs interface:

Gradio serves as the interactive graphical interface allowing users to easily interact with the chatbot, providing a user-friendly way to visualize and test the bot's capabilities.

Qdrant is a vector database optimized for ultra-fast similarity search across large datasets. It is used in this project to store and index document embeddings, enabling the bot to quickly find relevant documents based on a search query or conversation context.

AgentHandler is a central class, designed to initialize and manage the conversational agent within the rag_bot framework. It aims to provide developers with a clear and efficient way to handle the conversational agent's components and interactions.
_initialize(): Orchestrates the initialization of all the components required for the agent, ensuring each element is set up correctly._setup_config_and_env(): Loads configurations and sets up environment variables, providing a context for the agent's operation.
_setup_openai(): Initializes the OpenAI model based on loaded configurations. It includes error handling to log and raise exceptions if any issues occur during initialization.
_setup_memory(): Establishes the conversation buffer memory for maintaining chat history, enabling contextual conversations.
_load_prompt_templates(): Loads the prompt templates that guide the agent's responses and handles exceptions during the loading process, logging errors for troubleshooting.
_initialize_agent_executor(): Initializes theAgentExecutor, setting up theZeroShotAgentwith proper configurations and tools.
_setup_tools() -> list: Initializes and returns the tools required for theZeroShotAgent._setup_prompt_template() -> PromptTemplate: Constructs and returns the prompt template for the agent based on loaded templates and tools.
_setup_agent() -> AgentExecutor: Constructs and returns theZeroShotAgentwith all its configurations and tools.chat_with_agent(user_input: str) -> str: Handles user input, manages interaction with the agent, and returns the agent's response, with error handling and logging.
get_agent_handler() -> AgentHandler: Returns the singleton instance of theAgentHandler, preventing unnecessary instantiations and initializations.
agent_handler = get_agent_handler()
response = agent_handler.chat_with_agent("How does photosynthesis work?")The scraper module, located in /app/src/scraper/scraper_main.py, serves as a robust utility for extracting content from web pages and converting it into structured markdown format. This module is integral for enabling the framework to access and utilize information from a plethora of web sources. Below is a succinct overview focusing on its core functionalities and workflow for developers aiming to integrate and leverage this module effectively.
-
WebScraper Class:
- Inherits from the base Scraper class and implements the Singleton pattern to ensure a unique instance.
- Orchestrates the entire scraping process, from fetching to parsing, and saving the content.
- Leverages
ContentParserto extract and convert meaningful data from HTML tags into markdown format.
-
ContentParser Class:
- Designed to parse and convert meaningful content from supported HTML tags into markdown format.
- Supports a variety of HTML tags including paragraphs, headers, list items, links, inline code, and code blocks.
-
URL Validation:
- The provided URL undergoes validation to ensure its correctness and accessibility.
- If the URL is invalid, the process is terminated, and an error message is logged.
-
Content Fetching:
- Content from the validated URL is fetched using HTTP requests.
- Utilizes random user agents to mimic genuine user activity and avoid potential blocking by web servers.
- If the content fetching fails, the process is halted, and an error message is logged.
-
Content Parsing:
- The fetched content is parsed using BeautifulSoup, and the
ContentParserclass is employed to extract meaningful data. - The parsed data includes the title, metadata, and the content in markdown format.
- The fetched content is parsed using BeautifulSoup, and the
-
File Saving:
- The parsed content is saved to a file, the filename is generated using a hash of the URL.
- The file is stored in a pre-configured data directory.
- If the file saving fails, an error message is logged.
-
Result Return:
- Upon the successful completion of the scraping process, a success message and the filepath of the saved content are returned.
- If any step in the process fails, an appropriate error message is returned.
Developers can initiate the scraping process by invoking the run_web_scraper(url) function with the desired URL. This function initializes a WebScraper instance and triggers the scraping process, returning a dictionary containing the outcome of the scraping process, including messages indicating success or failure and the location where the scraped data has been saved.
result = run_web_scraper("http://example.com")
if result and result.get("message") == "Scraping completed successfully":
print(f"Scraping complete! Saved to {result['data']}")
else:
print(result["message"])The DocumentLoader class, located within your project structure, is a pivotal component designed to load, embed, and index documents from a specified source directory into a Qdrant collection. This class is crucial for developers looking to manage and utilize a collection of documents efficiently within the framework. Below is a concise overview of its core functionalities and workflow to aid developers in integrating and leveraging this class effectively.
-
QdrantCollectionManager Class:
- Manages Qdrant collections, ensuring their existence or creating them as needed.
- Interacts with the
QdrantClientto perform operations on the collections.
-
DocumentLoader Class:
- Initializes with a source directory, collection name, configuration, and embedding model.
- Loads documents from the source directory and indexes them into the specified Qdrant collection.
- Moves the loaded documents to an output directory after successful indexing.
-
Initialization:
- The
DocumentLoaderinitializes with a specified source directory and collection name. - Loads configurations and sets up environment variables.
- Initializes the embedding model and Qdrant client.
- Ensures the existence of the specified Qdrant collection or creates it if it doesn’t exist.
- The
-
Document Loading and Indexing:
- Reads documents from the source directory using
SimpleDirectoryReader. - Embeds and indexes the documents into the specified Qdrant collection using
VectorStoreIndex. - If any error occurs during this process, it is logged, and the error is raised.
- Reads documents from the source directory using
-
File Movement:
- After successful loading and indexing, the documents are moved from the source directory to an output directory.
- If the output directory doesn’t exist, it is created.
Developers can instantiate the DocumentLoader class with the desired source directory and collection name and call the load_documents method to load, embed, and index the documents into the specified Qdrant collection. After successful indexing, the documents are moved to an output directory.
document_loader = DocumentLoader(source_dir='/path/to/documents', collection_name='mycollection')
index = document_loader.load_documents() # This will load, embed, and index the documents and then move them to the output directory.The DocumentSearch class is a component of the framework that is designed to facilitate document searches within a specified collection using a vector store index. This class is integral for developers aiming to implement and leverage efficient document retrieval functionalities within the framework. Below is a succinct overview of its core functionalities and workflow to assist developers in understanding and integrating this class effectively.
- DocumentSearch Class:
- Initializes with a specified collection name and user input query.
- Sets up the vector store index and performs searches on it based on the user input query.
- Handles exceptions and logs errors during the index setup and document search processes.
-
Initialization:
- The
DocumentSearchinitializes with a specified collection name and user input query. - Loads configurations and sets up environment variables.
- Initializes the Qdrant client and embedding model.
- The
-
Index Setup:
- Sets up the vector store index for the specified collection using
QdrantVectorStoreandServiceContext. - If any error occurs during this process, it is logged, and the error is raised.
- Sets up the vector store index for the specified collection using
-
Document Search:
- Performs a search on the set up index based on the user input query using the query engine.
- Logs the response received from querying the index.
- If any error occurs during this process, it is logged, and the error is raised.
Developers can instantiate the DocumentSearch class with the desired collection name and user input query and call the search_documents method to perform a search on the specified collection and retrieve documents based on the user input query.
document_search = DocumentSearch(collection_name='mycollection', user_input='my query')
response = document_search.search_documents() # This will perform a search on the specified collection and return the response.The tools module is designed to enhance the agent's capabilities by integrating external libraries, APIs, and custom functionalities. It serves as a practical extension point for developers looking to customize and extend the agent's abilities.
-
Integration of External Libraries and APIs:
- The module allows for the incorporation of various libraries and APIs, enabling the agent to access and leverage external functionalities and data.
-
Contextual Conversations:
- Tools like
SerpAPIandDocumentSearchenable the agent to access real-time, relevant information, allowing for more informed and context-aware conversations.
- Tools like
-
SerpAPI Search Wrapper:
- Conducts Google searches to retrieve real-time search results programmatically.
- Useful for obtaining current and relevant web information for user queries.
-
Document Searcher:
- Queries specialized vector stores like ‘TechDocs’ for technical documentation.
- Useful for addressing technical inquiries by providing relevant context and information.
- Developers can modify existing tools or create new ones to meet specific needs, allowing for a high degree of customization and adaptability.
The ToolSetup class is used to initialize and set up tools. Developers can leverage this class to equip the agent with a variety of tools that can be invoked based on the conversational context to enhance the agent's responses.
The tools module is dynamic and can be continually refined and expanded. Developers are encouraged to explore new integrations and enhancements to keep improving the agent's capabilities.
Prompt Engineering is a pivotal process in developing conversational agents, focusing on optimizing the prompts sent to Language Models (LLMs) to elicit desired responses. It involves utilizing template files and leveraging platforms and resources to refine interactions with LLMs.
Developers should leverage the template files and the LangSmith platform along with the additional resources to enhance the prompt engineering process, ensuring optimized interactions with LLMs and refined conversational experiences.
The project incorporates three template files located in /app/src/template to define the interaction dynamics:
- prefix.txt: Defines the bot's personality and tool access.
- react_cot.txt: Outlines the chain of thought reasoning.
- suffix.txt: Allocates space for the agent scratchpad, memory, and user input.
LangSmith is an integral platform designed to assist developers in building, debugging, testing, evaluating, and refining LLM-powered applications. It provides a suite of tools focusing on visibility, workflows, and extensibility, making it an indispensable resource for developing production-ready LLM applications.
- Debugging: Full visibility into prompts and responses, latency and token usage tracking, and a playground UI for tweaking prompts.
- Testing: Allows the creation and running of chains/prompts over datasets for manual review.
- Evaluating: Integrates with open-source evaluation modules.
- Monitoring: Tracks system metrics and user interactions, and associates user feedback with model runs.
- Unified Platform: Connects workflows and allows export of logs and datasets for integration with other tools.

Developers are encour## 🛠️ Adapt. Customize. Innovate.
document_search = DocumentSearch(collection_name='mycollection', user_input='my query')
response = document_search.search_documents() # This will perform a search on the specified collection and return the response.The tools module is designed to enhance the agent's capabilities by integrating external libraries, APIs, and custom functionalities. It serves as a practical extension point for developers looking to customize and extend the agent's abilities.
-
Integration of External Libraries and APIs:
- The module allows for the incorporation of various libraries and APIs, enabling the agent to access and leverage external functionalities and data.
-
Contextual Conversations:
- Tools like
SerpAPIandDocumentSearchenable the agent to access real-time, relevant information, allowing for more informed and context-aware conversations.
- Tools like
-
SerpAPI Search Wrapper:
- Conducts Google searches to retrieve real-time search results programmatically.
- Useful for obtaining current and relevant web information for user queries.
-
Document Searcher:
- Queries specialized vector stores like ‘TechDocs’ for technical documentation.
- Useful for addressing technical inquiries by providing relevant context and information.
- Developers can modify existing tools or create new ones to meet specific needs, allowing for a high degree of customization and adaptability.
The ToolSetup class is used to initialize and set up tools. Developers can leverage this class to equip the agent with a variety of tools that can be invoked based on the conversational context to enhance the agent's responses.
The tools module is dynamic and can be continually refined and expanded. Developers are encouraged to explore new integrations and enhancements to keep improving the agent's capabilities.
Prompt Engineering is a pivotal process in developing conversational agents, focusing on optimizing the prompts sent to Language Models (LLMs) to elicit desired responses. It involves utilizing template files and leveraging platforms and resources to refine interactions with LLMs.
Developers should leverage the template files and the LangSmith platform along with the additional resources to enhance the prompt engineering process, ensuring optimized interactions with LLMs and refined conversational experiences.
The project incorporates three template files located in /app/src/template to define the interaction dynamics:
- prefix.txt: Defines the bot's personality and tool access.
- react_cot.txt: Outlines the chain of thought reasoning.
- suffix.txt: Allocates space for the agent scratchpad, memory, and user input.
LangSmith is an integral platform designed to assist developers in building, debugging, testing, evaluating, and refining LLM-powered applications. It provides a suite of tools focusing on visibility, workflows, and extensibility, making it an indispensable resource for developing production-ready LLM applications.
- Debugging: Full visibility into prompts and responses, latency and token usage tracking, and a playground UI for tweaking prompts.
- Testing: Allows the creation and running of chains/prompts over datasets for manual review.
- Evaluating: Integrates with open-source evaluation modules.
- Monitoring: Tracks system metrics and user interactions, and associates user feedback with model runs.
- Unified Platform: Connects workflows and allows export of logs and datasets for integration with other tools.
Developers are encouraged to explore the following resources for more insights and guidance on prompt engineering:
- Prompting Engineering Guide: An educational project by DAIR.AI focusing on prompt engineering.
- LangChain Hub: A centralized platform for managing prompts.
While the project provides a solid architecture, there are ample opportunities for customization and extensibility:
- Data Sources - Integrate additional knowledge sources like databases, internal company documents etc.
- Models - Experiment with different language models based on your conversational requirements.
- Tools - Build new tools to extend the agent's capabilitieaged to explore the following resources for more insights and guidance on prompt engineering:
- Prompting Engineering Guide: An educational project by DAIR.AI focusing on prompt engineering.
- LangChain Hub: A centralized platform for managing prompts.
- Tools - Build new tools to extend the agent's capabilities like calendars, weather data, translations etc.
- Prompts - Refine and optimize prompts for your chatbot's persona and use cases.
- Visual Interface - Develop custom graphical interfaces tailored to your needs.
- API Integration - Build on top of the FastAPI backend to integrate with other services.
API tests are provided in ./tests/integration
To run the API tests, first ensure you've started up the application with docker-compose, then run the below command to execute tests from withing docker container with deps installed.
docker exec -t RAG_BOT_FASTAPI pytest -v