Christian Cosgrove, Darius Irani, Jung Min Lee
- Download and extract the MovieTriples data into
dat/MovieTriples_Dataset/. git lfs fetch --allto get the model files from Git LFS (Might not be necessary if you had LFS installed prior to cloning the repo)python create_dict_pickle.pypython examples/train_model.py -t movie_triples -m hred/hred -mf test_hred --datapath dat -vsz 10008 -stim 30 -bms 20 -e 80 -seshid 300 -uthid 300 -drp 0.4 -lr 0.0005 --batchsize 50 --truncate 256 --optimizer adampython examples/interactive.py -m hred/hred -mf test_hred.checkpoint.checkpointpython alexa_server2.py
We used Harshal's HRED implementation; with minor modifications, we were able to integrate it with ParlAI. We also implemented a ParlAI Task for the MovieTriples dataset (data provided by Joao).
What we modified:
-
MovieTriples Task --
/parlai/tasks/movie_triples/agents.py. We created a dataloader where each triple is a single utterance. We experimented with different approaches here--e.g. considering each utterance separately and using the history vector functionality. However, the simplest approach we decided on was to (at training time) consider the triple to be a single utterance separated by</s>tokens and split these utterances in thebatchifymethod. (At inference time, we used thehistory_vecsinstead). -
Dictionary creation. Part of the challenge of working with the MovieTriples data is that it has custom separation/person tokens. Rather than hardcoding this, we wanted to use the most ParlAI-friendly code. Noticing that
train_model.pywill load a.dictfile if it is already present, we wrote code to generate a ParlAI dictionary directly from the dictionary provided with the MovieTriples data. Runcreate_dict_pickle.pyto generate a ParlAI.dictbefore runningtrain_model.pyorinteractive.pyto ensure that tokens are mapped correctly. -
HredAgent-- This is t]he core ParlAI code for the HRED model. It inherits fromTorchGeneratorAgent, which provides scaffolding code for an encoder-decoder-type model. However, we were unable to rely on most of the initial code because it was designed for a single encoder and decoder; in our case, we have two encoders (utterance encoder and session encoder), the first of which is called multiple times (on each of the input utterances). Therefore, we had to override the_generateand_compute_lossmethods inHredAgent, calling Harshal's code instead. -
Alexa integration. Using flask-ask We followed this tutorial to create an alexa endpoint. We used ngrok to host.
One challenge we ran into was integrating the Alexa webservice with ParlAI. The best way to do this would probably have been to write a custom agent and run world.parley between the Alexa webservice agent and the model. Instead, we opted to call interactive.py using subprocess pipes--this quick fix worked well for us.
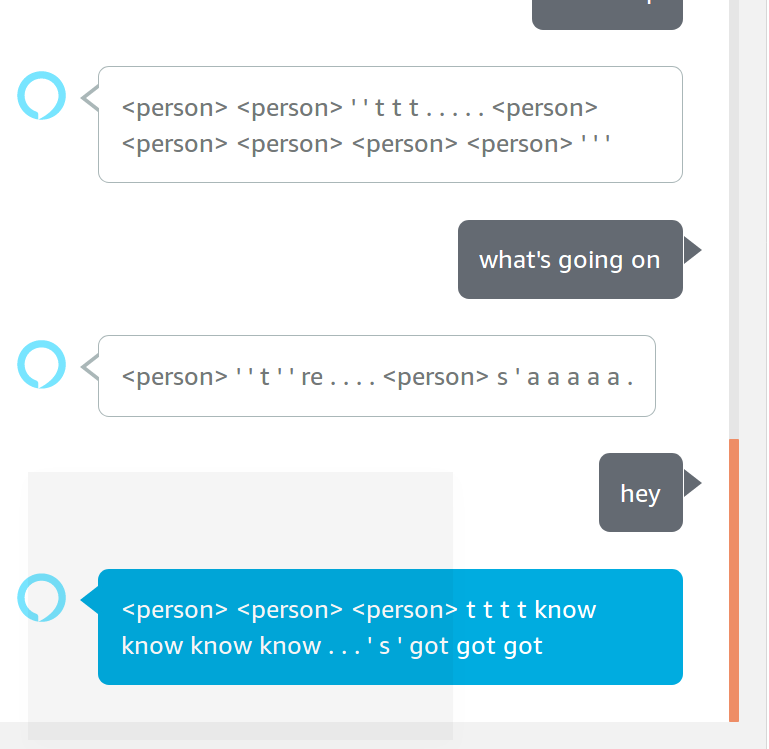
Output of model trained for roughly 12 hrs:
It achieved the following statistics on the training set (we didn't get the chance to implement validation set logic for MovieTriples):
[ time:43019.0s total_exs:7122850 epochs:36.28 ] {'exs': 350, 'loss': 2.066, 'ppl': 7.891, 'token_acc': 0.6367, 'tokens_per_batch': 3363.0, 'gnorm': 0.763, 'clip': 1.0, 'updates': 7, 'lr': 0.0005, 'gpu_mem_percent': 0.5598, 'total_train_updates': 132620}
/home/christian/developer/cs767hw3/parlai/agents/hred/hred.py:580: UserWarning: volatile was removed and now has no effect. Use `with torch.no_grad():` instead.
_target = Variable(torch.LongTensor([seq]), volatile=True)
[metrics]: {'loss': AverageMetric(0.0004177), 'ppl': PPLMetric(1), 'token_acc': AverageMetric(1)}
[HRED]: no no no . . no no no no no no one . . . <continued_utterance> <continued_utterance> . <person> <continued_utterance>
Enter Your Message: how are you doing today?
[metrics]: {'loss': AverageMetric(0.0003052), 'ppl': PPLMetric(1), 'token_acc': AverageMetric(1)}
[HRED]: i i ' ' m m m . . . . . i i i i i i i i
Enter Your Message: What's up?
[metrics]: {'loss': AverageMetric(0.01836), 'ppl': PPLMetric(1.019), 'token_acc': AverageMetric(1)}
[HRED]: i . . i . . i . . m m afraid . i i i i i i .
Enter Your Message:
The model tends to repeat tokens multiple times---we are not sure why this happens (possibly because of no teacher forcing?)
/home/christian/developer/cs767hw3/parlai/agents/hred/hred.py:580: UserWarning: volatile was removed and now has no effect. Use `with torch.no_grad():` instead.
_target = Variable(torch.LongTensor([seq]), volatile=True)
[metrics]: {'loss': AverageMetric(0.0001736), 'ppl': PPLMetric(1), 'token_acc': AverageMetric(1)}
[HRED]: i i i m fine wondering wondering wondering wondering wondering wondering . . . . <continued_utterance> i m ' just
Enter Your Message: what are you wondering about?
[metrics]: {'loss': AverageMetric(0.0003471), 'ppl': PPLMetric(1), 'token_acc': AverageMetric(1)}
[HRED]: i i ' ' m m m . . . . . i i i i i to to to
Enter Your Message: it's ok
[metrics]: {'loss': AverageMetric(0.0006313), 'ppl': PPLMetric(1.001), 'token_acc': AverageMetric(1)}
[HRED]: i . . i . . i
- Because we were training for a limited time, we wanted the model to learn to generate responses immediately, rather than "cheating" through teacher forcing. Therefore, we set teacher_forcing=False and set the teacher forcing probability to zero. Perhaps if we trained for longer, we would use teacher forcing and anneal this probability to zero with training.
While we are able to run train_model.py for a few minutes, we are encountering a mysterious CUDA error that causes training to crash. We are not sure what is causing this error (no error message printed). Because of limited training time, our model outputs were poor.
FIX: we had to increase the vocabulary size from 10004 to 10008.
python examples/train_model.py -t movie_triples -m hred/hred -mf test_hred.checkpoint --datapath dat -vsz 10004 -stim 30 -tc -bms 20 -bs 100 -e 80 -seshid 300 -uthid 300 -drp 0.4 -lr 0.0005 --batchsize 25 --truncate 64
[ Main ParlAI Arguments: ]
[ batchsize: 25 ]
[ datapath: dat ]
[ datatype: train ]
...
[ update_freq: 1 ]
[ warmup_rate: 0.0001 ]
[ warmup_updates: -1 ]
[ building dictionary first... ]
[ dictionary already built .]
[ no model with opt yet at: test_hred.checkpoint(.opt) ]
[ Using CUDA ]
Dictionary: loading dictionary from test_hred.checkpoint.dict
[ num words = 10008 ]
/home/christian/.conda/envs/parlai/lib/python3.7/site-packages/torch/nn/modules/rnn.py:51: UserWarning: dropout option adds dropout after all but last recurrent layer, so non-zero dropout expects num_layers greater than 1, but got dropout=0.4 and num_layers=1
"num_layers={}".format(dropout, num_layers))
Total parameters: 12612000
Trainable parameters: 12612000
[creating task(s): movie_triples]
loading: dat/MovieTriples_Dataset
4%|██▏ | 7989/196308 [00:00<00:03, 57141.41it/s]
[ training... ]
Computing loss tensor(9.1967, device='cuda:0', grad_fn=<DivBackward0>)
Computing loss tensor(9.2328, device='cuda:0', grad_fn=<DivBackward0>)
Computing loss tensor(9.2259, device='cuda:0', grad_fn=<DivBackward0>)
Computing loss tensor(9.2635, device='cuda:0', grad_fn=<DivBackward0>)
Computing loss tensor(9.2591, device='cuda:0', grad_fn=<DivBackward0>)
Computing loss tensor(9.2241, device='cuda:0', grad_fn=<DivBackward0>)
Computing loss tensor(9.2418, device='cuda:0', grad_fn=<DivBackward0>)
Computing loss tensor(9.2213, device='cuda:0', grad_fn=<DivBackward0>)
Computing loss tensor(9.1893, device='cuda:0', grad_fn=<DivBackward0>)
Computing loss tensor(9.2253, device='cuda:0', grad_fn=<DivBackward0>)
Computing loss tensor(9.2156, device='cuda:0', grad_fn=<DivBackward0>)
Computing loss tensor(9.2257, device='cuda:0', grad_fn=<DivBackward0>)
Computing loss tensor(9.2419, device='cuda:0', grad_fn=<DivBackward0>)
[ time:2.0s total_exs:4625 epochs:0.46 ] {'exs': 4625, 'loss': 9.229, 'ppl': 10190.0, 'token_acc': 0, 'tokens_per_batch': 1372.0, 'gnorm': 2.339, 'clip': 1.0, 'updates': 13, 'lr': 0.0005, 'gpu_mem_percent': 0.08476, 'total_train_updates': 13}
Computing loss tensor(9.2104, device='cuda:0', grad_fn=<DivBackward0>)
Computing loss tensor(9.2234, device='cuda:0', grad_fn=<DivBackward0>)
Computing loss tensor(9.3123, device='cuda:0', grad_fn=<DivBackward0>)
Computing loss tensor(9.2417, device='cuda:0', grad_fn=<DivBackward0>)
Computing loss tensor(9.2715, device='cuda:0', grad_fn=<DivBackward0>)
Computing loss tensor(9.1723, device='cuda:0', grad_fn=<DivBackward0>)
Computing loss tensor(9.2327, device='cuda:0', grad_fn=<DivBackward0>)
Computing loss tensor(9.1948, device='cuda:0', grad_fn=<DivBackward0>)
Computing loss tensor(9.2188, device='cuda:0', grad_fn=<DivBackward0>)
Computing loss tensor(9.2541, device='cuda:0', grad_fn=<DivBackward0>)
Computing loss tensor(9.2441, device='cuda:0', grad_fn=<DivBackward0>)
Computing loss tensor(9.2795, device='cuda:0', grad_fn=<DivBackward0>)
Computing loss tensor(9.2659, device='cuda:0', grad_fn=<DivBackward0>)
Computing loss tensor(9.1956, device='cuda:0', grad_fn=<DivBackward0>)
Computing loss tensor(9.2122, device='cuda:0', grad_fn=<DivBackward0>)
[ time:4.0s total_exs:10050 epochs:1.0 ] {'exs': 5425, 'loss': 9.236, 'ppl': 10260.0, 'token_acc': 0, 'tokens_per_batch': 1389.0, 'gnorm': 2.319, 'clip': 1.0, 'updates': 15, 'lr': 0.0005, 'gpu_mem_percent': 0.08477, 'total_train_updates': 28}
Computing loss tensor(9.1954, device='cuda:0', grad_fn=<DivBackward0>)
Computing loss tensor(9.2452, device='cuda:0', grad_fn=<DivBackward0>)
Computing loss tensor(9.1885, device='cuda:0', grad_fn=<DivBackward0>)
Computing loss tensor(9.2382, device='cuda:0', grad_fn=<DivBackward0>)
Computing loss tensor(9.2388, device='cuda:0', grad_fn=<DivBackward0>)
Computing loss tensor(9.2685, device='cuda:0', grad_fn=<DivBackward0>)
Computing loss tensor(9.1634, device='cuda:0', grad_fn=<DivBackward0>)
Computing loss tensor(9.2699, device='cuda:0', grad_fn=<DivBackward0>)
Computing loss tensor(9.2546, device='cuda:0', grad_fn=<DivBackward0>)
Computing loss tensor(9.2601, device='cuda:0', grad_fn=<DivBackward0>)
Computing loss tensor(9.2436, device='cuda:0', grad_fn=<DivBackward0>)
Computing loss tensor(9.2403, device='cuda:0', grad_fn=<DivBackward0>)
Computing loss tensor(9.2084, device='cuda:0', grad_fn=<DivBackward0>)
[ time:6.0s total_exs:15450 epochs:1.54 ] {'exs': 5400, 'loss': 9.233, 'ppl': 10220.0, 'token_acc': 0, 'tokens_per_batch': 1431.0, 'gnorm': 2.308, 'clip': 1.0, 'updates': 13, 'lr': 0.0005, 'gpu_mem_percent': 0.08476, 'total_train_updates': 41}
Computing loss tensor(9.2614, device='cuda:0', grad_fn=<DivBackward0>)
Computing loss tensor(9.1843, device='cuda:0', grad_fn=<DivBackward0>)
Computing loss tensor(9.2037, device='cuda:0', grad_fn=<DivBackward0>)
Computing loss tensor(9.2279, device='cuda:0', grad_fn=<DivBackward0>)
Computing loss tensor(9.2326, device='cuda:0', grad_fn=<DivBackward0>)
Computing loss tensor(9.1960, device='cuda:0', grad_fn=<DivBackward0>)
Computing loss tensor(9.2107, device='cuda:0', grad_fn=<DivBackward0>)
Computing loss tensor(9.2866, device='cuda:0', grad_fn=<DivBackward0>)
Computing loss tensor(9.2092, device='cuda:0', grad_fn=<DivBackward0>)
Computing loss tensor(9.1780, device='cuda:0', grad_fn=<DivBackward0>)
Computing loss tensor(9.2745, device='cuda:0', grad_fn=<DivBackward0>)
Computing loss tensor(9.2331, device='cuda:0', grad_fn=<DivBackward0>)
Computing loss tensor(9.2063, device='cuda:0', grad_fn=<DivBackward0>)
[ time:8.0s total_exs:20100 epochs:2.01 ] {'exs': 4650, 'loss': 9.223, 'ppl': 10120.0, 'token_acc': 0, 'tokens_per_batch': 1369.0, 'gnorm': 2.323, 'clip': 1.0, 'updates': 13, 'lr': 0.0005, 'gpu_mem_percent': 0.08477, 'total_train_updates': 54}
Computing loss tensor(9.2682, device='cuda:0', grad_fn=<DivBackward0>)
Computing loss tensor(9.2238, device='cuda:0', grad_fn=<DivBackward0>)
Computing loss tensor(9.2419, device='cuda:0', grad_fn=<DivBackward0>)
Computing loss tensor(9.2312, device='cuda:0', grad_fn=<DivBackward0>)
/tmp/pip-req-build-zfu01l1o/aten/src/THC/THCTensorIndex.cu:361: void indexSelectLargeIndex(TensorInfo<T, IndexType>, TensorInfo<T, IndexType>, TensorInfo<long, IndexType>, int, int, IndexType, IndexType, long) [with T = float, IndexType = unsigned int, DstDim = 2, SrcDim = 2, IdxDim = -2, IndexIsMajor = true]: block: [41,0,0], thread: [96,0,0] Assertion `srcIndex < srcSelectDimSize` failed.
/tmp/pip-req-build-zfu01l1o/aten/src/THC/THCTensorIndex.cu:361: void indexSelectLargeIndex(TensorInfo<T, IndexType>, TensorInfo<T, IndexType>, TensorInfo<long, IndexType>, int, int, IndexType, IndexType, long) [with T = float, IndexType = unsigned int, DstDim = 2, SrcDim = 2, IdxDim = -2, IndexIsMajor = true]: block: [41,0,0], thread: [97,0,0] Assertion `srcIndex < srcSelectDimSize` failed.
/tmp/pip-req-build-zfu01l1o/aten/src/THC/THCTensorIndex.cu:361: void indexSelectLargeIndex(TensorInfo<T, IndexType>, TensorInfo<T, IndexType>, TensorInfo<long, IndexType>, int, int, IndexType, IndexType, long) [with T = float, IndexType = unsigned int, DstDim = 2, SrcDim = 2, IdxDim = -2, IndexIsMajor = true]: block: [41,0,0], thread: [98,0,0] Assertion `srcIndex < srcSelectDimSize` failed.
... Repeated many times ...
SrcDim = 2, IdxDim = -2, IndexIsMajor = true]: block: [41,0,0], thread: [95,0,0] Assertion `srcIndex < srcSelectDimSize` failed.
Traceback (most recent call last):
File "examples/train_model.py", line 17, in <module>
TrainLoop(opt).train()
File "/home/christian/developer/cs767hw3/parlai/scripts/train_model.py", line 635, in train
world.parley()
File "/home/christian/developer/cs767hw3/parlai/core/worlds.py", line 903, in parley
batch_act = self.batch_act(agent_idx, batch_observations[agent_idx])
File "/home/christian/developer/cs767hw3/parlai/core/worlds.py", line 871, in batch_act
batch_actions = a.batch_act(batch_observation)
File "/home/christian/developer/cs767hw3/parlai/core/torch_agent.py", line 1844, in batch_act
output = self.train_step(batch)
File "/home/christian/developer/cs767hw3/parlai/agents/hred/hred.py", line 412, in train_step
super().train_step(batch)
File "/home/christian/developer/cs767hw3/parlai/core/torch_generator_agent.py", line 611, in train_step
raise e
File "/home/christian/developer/cs767hw3/parlai/core/torch_generator_agent.py", line 594, in train_step
loss = self.compute_loss(batch)
File "/home/christian/developer/cs767hw3/parlai/agents/hred/hred.py", line 383, in compute_loss
model_output = self.model(self._model_input(batch))
File "/home/christian/.conda/envs/parlai/lib/python3.7/site-packages/torch/nn/modules/module.py", line 541, in __call__
result = self.forward(*input, **kwargs)
File "/home/christian/developer/cs767hw3/parlai/agents/hred/modules.py", line 43, in forward
preds, lmpreds = self.dec((final_session_o, u3, u3_lens))
File "/home/christian/.conda/envs/parlai/lib/python3.7/site-packages/torch/nn/modules/module.py", line 541, in __call__
result = self.forward(*input, **kwargs)
File "/home/christian/developer/cs767hw3/parlai/agents/hred/modules.py", line 241, in forward
dec_o, dec_lm = self.do_decode_tc(ses_encoding, x, x_lens)
File "/home/christian/developer/cs767hw3/parlai/agents/hred/modules.py", line 142, in do_decode_tc
target_emb = torch.nn.utils.rnn.pack_padded_sequence(target_emb, target_lens, batch_first=True, enforce_sorted=False)
File "/home/christian/.conda/envs/parlai/lib/python3.7/site-packages/torch/nn/utils/rnn.py", line 277, in pack_padded_sequence
sorted_indices = sorted_indices.to(input.device)
RuntimeError: CUDA error: device-side assert triggered