一款高性能非法词(敏感词)检测组件,附带繁体简体互换,支持全角半角互换,获取拼音首字母,获取拼音字母,拼音模糊搜索等功能。
C#语言,使用StringSearchEx2.Replace过滤,在48k敏感词库上的过滤速度超过3亿字符每秒。(cpu i7 8750h)
csharp 文件夹说明:
ToolGood.Pinyin.Build: 生成词的拼音
ToolGood.Pinyin.Pretreatment: 生成拼音预处理,核对拼音,词组最小化
ToolGood.Transformation.Build: 生成简体繁体转换文档,更新时文档放在同一目录下,词库参考 https://github.com/BYVoid/OpenCC
ToolGood.Words.Contrast: 字符串搜索对比
ToolGood.Words.Test: 单元测试
ToolGood.Words: 本项目源代码
非法词(敏感词)检测类:StringSearch、StringSearchEx、StringSearchEx2、WordsSearch、WordsSearchEx、WordsSearchEx2、IllegalWordsSearch;
StringSearch、StringSearchEx、StringSearchEx2、StringSearchEx3: 搜索FindFirst方法返回结果为string类型。WordsSearch、WordsSearchEx、WordsSearchEx2、WordsSearchEx3: 搜索FindFirst方法返回结果为WordsSearchResult类型,WordsSearchResult不仅仅有关键字,还有关键字的开始位置、结束位置,关键字序号等。IllegalWordsSearch: 过滤非法词(敏感词)专用类,可设置跳字长度,默认全角转半角,忽略大小写,跳词,重复词,黑名单, 搜索FindFirst方法返回为IllegalWordsSearchResult,有关键字,对应原文,开始、位置,黑名单类型。IllegalWordsSearch、StringSearchEx、StringSearchEx2、WordsSearchEx、WordsSearchEx2使用Save、Load方法,可以加快初始化。- 共同方法有:
SetKeywords、ContainsAny、FindFirst、FindAll、Replace IllegalWordsSearch独有方法:SetSkipWords(设置跳词)、SetBlacklist(设置黑名单)。IllegalWordsSearch字段UseIgnoreCase:设置是忽略否大小写,必须在SetKeywords方法之前,注:使用Load方法则该字段无效。StringSearchEx3、WordsSearchEx3为指针版优化版,实测时发现性能浮动比较大。
string s = "**|国人|zg人";
string test = "我是**人";
StringSearch iwords = new StringSearch();
iwords.SetKeywords(s.Split('|'));
var b = iwords.ContainsAny(test);
Assert.AreEqual(true, b);
var f = iwords.FindFirst(test);
Assert.AreEqual("**", f);
var all = iwords.FindAll(test);
Assert.AreEqual("**", all[0]);
Assert.AreEqual("国人", all[1]);
Assert.AreEqual(2, all.Count);
var str = iwords.Replace(test, '*');
Assert.AreEqual("我是***", str);非法词(敏感词)检测类:StringMatch、StringMatchEx、WordsMatch、WordsMatchEx。
支持部分正则表达式类型:.(点)?(问号) [](方括号) (|)(括号与竖线)
string s = ".[中美]国|国人|zg人";
string test = "我是**人";
WordsMatch wordsSearch = new WordsMatch();
wordsSearch.SetKeywords(s.Split('|'));
var b = wordsSearch.ContainsAny(test);
Assert.AreEqual(true, b);
var f = wordsSearch.FindFirst(test);
Assert.AreEqual("是**", f.Keyword);
var alls = wordsSearch.FindAll(test);
Assert.AreEqual("是**", alls[0].Keyword);
Assert.AreEqual(".[中美]国", alls[0].MatchKeyword);
Assert.AreEqual(1, alls[0].Start);
Assert.AreEqual(3, alls[0].End);
Assert.AreEqual(0, alls[0].Index);//返回索引Index,默认从0开始
Assert.AreEqual("国人", alls[1].Keyword);
Assert.AreEqual(2, alls.Count);
var t = wordsSearch.Replace(test, '*');
Assert.AreEqual("我****", t); // 转成简体
WordsHelper.ToSimplifiedChinese("我愛中國");
WordsHelper.ToSimplifiedChinese("我愛中國",1);// 港澳繁体 转 简体
WordsHelper.ToSimplifiedChinese("我愛中國",2);// **正体 转 简体
// 转成繁体
WordsHelper.ToTraditionalChinese("我爱**");
WordsHelper.ToTraditionalChinese("我爱**",1);// 简体 转 港澳繁体
WordsHelper.ToTraditionalChinese("我爱**",2);// 简体 转 **正体
// 转成全角
WordsHelper.ToSBC("abcABC123");
// 转成半角
WordsHelper.ToDBC("abcABC123");
// 数字转成中文大写
WordsHelper.ToChineseRMB(12345678901.12);
// 中文转成数字
WordsHelper.ToNumber("壹佰贰拾叁亿肆仟伍佰陆拾柒万捌仟玖佰零壹元壹角贰分");
// 获取全拼
WordsHelper.GetPinyin("我爱**");//WoAiZhongGuo
WordsHelper.GetPinyin("我爱**",",");//Wo,Ai,Zhong,Guo
WordsHelper.GetPinyin("我爱**",true);//WǒÀiZhōngGuó
// 获取首字母
WordsHelper.GetFirstPinyin("我爱**");//WAZG
// 获取全部拼音
WordsHelper.GetAllPinyin('传');//Chuan,Zhuan
// 获取姓名
WordsHelper.GetPinyinForName("单一一")//ShanYiYi
WordsHelper.GetPinyinForName("单一一",",")//Shan,Yi,Yi
WordsHelper.GetPinyinForName("单一一",true)//ShànYīYīToolGood.Words.Pinyin 追求更快的加载速度(目前只有C#代码)。
PinyinMatch:方法有SetKeywords、SetIndexs、Find、FindIndex。
PinyinMatch<T>:方法有SetKeywordsFunc、SetPinyinFunc、SetPinyinSplitChar、Find。
string s = "北京|天津|河北|辽宁|吉林|黑龙江|山东|江苏|上海|浙江|安徽|福建|江西|广东|广西|海南|河南|湖南|湖北|山西|内蒙古|宁夏|青海|陕西|甘肃|**|四川|贵州|云南|重庆|西藏|香港|澳门|**";
PinyinMatch match = new PinyinMatch();
match.SetKeywords(s.Split('|').ToList());
var all = match.Find("BJ");
Assert.AreEqual("北京", all[0]);
Assert.AreEqual(1, all.Count);
all = match.Find("北J");
Assert.AreEqual("北京", all[0]);
Assert.AreEqual(1, all.Count);
all = match.Find("北Ji");
Assert.AreEqual("北京", all[0]);
Assert.AreEqual(1, all.Count);
all = match.Find("S");
Assert.AreEqual("山东", all[0]);
Assert.AreEqual("江苏", all[1]);
var all2 = match.FindIndex("BJ");
Assert.AreEqual(0, all2[0]);
Assert.AreEqual(1, all.Count);执行10万次性能对比,结果如下:
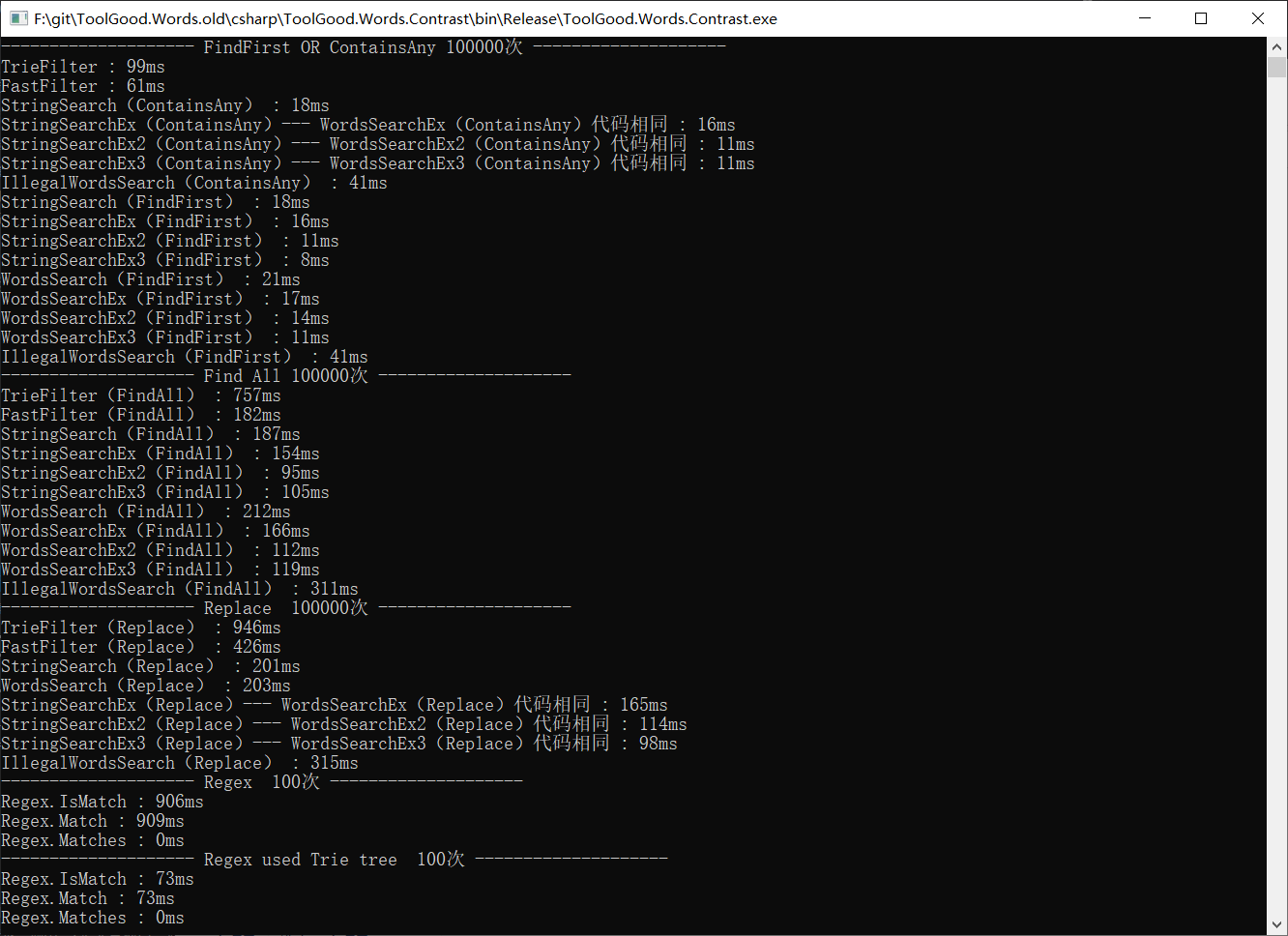
注:C#自带正则很慢,StringSearchEx2.ContainsAny是Regex.IsMatch效率的8.8万倍多,跟关键字数量有关。
Regex.Matches的运行方式跟IQueryable的类似,只返回MatchCollection,还没有计算。
在 Find All测试中,
FastFilter只能检测出7个:
[0]: "主席"
[1]: "赵洪祝"
[2]: "**"
[3]: "铁道部"
[4]: "党"
[5]: "胡锦涛"
[6]: "倒台"
StringSearch检测出14个:
[0]: "党"
[1]: "党委"
[2]: "西藏"
[3]: "党"
[4]: "党委"
[5]: "主席"
[6]: "赵洪祝"
[7]: "**"
[8]: "铁道部"
[9]: "党"
[10]: "胡锦涛"
[11]: "锦涛"
[12]: "倒台"
[13]: "黑社会"
插曲:在细查Regex.Matches神奇3ms,我发现Regex.Matches有一个小问题,
Regex.Matches只能检测出11个:
[0]: "党"
[1]: "西藏"
[2]: "党"
[3]: "主席"
[4]: "赵洪祝"
[5]: "**"
[6]: "铁道部"
[7]: "党"
[8]: "胡锦涛"
[9]: "倒台"
[10]: "黑社会"
非法词(敏感词)检测方法可用于电脑病毒检测及基因检测。
1、完成javascript版本,目前 javascript只写了一小部分。
1、GO语言算法优化:在GO版本移植成功后,测试后性能不理想,性能 GO < JAVA < C#,因为我没有完全理解GO语言。JAVA与C#采用了新的算法,GO还是采用老的算法。
2、汉字转拼音功能扩展:当初为了减少dll体积,删去古诗拼音,准备添加一个加载拼音库的功能,以及拼音库管理器。
3、繁体简体转换功能扩展:https://github.com/BYVoid/OpenCC 项目更新比较频繁,过于频繁更新dll库,对项目更新不太好友。准备添加一个添加繁体简体字典的功能,及字典生成器。
4、代码添加注释:AC自动机原理本身比较难理解,优化后的代码更难理解了。
1、研究一下《多个关键字组合过滤》技术。
2、研究一下《情感分析》技术
3、整理一份敏感词。
细分敏感词词组:动词+名词+特定词
细分敏感词分类:涉政文本、涉爆文本、色情文本、辱骂文本、非法交易文本、广告导流文本
我建一个Q群,用于探讨敏感信息过滤算法、敏感词汇及图片过滤。
群文件分享了一些收集的资料:通用敏感词、购物app、聊天app、游戏app敏感词。
敏感信息过滤研究会,Q群:128994346