This repo contains code examples that demonstrate how to use cleanlab with specific real-world models/datasets, how its underlying algorithms work, how to get better results via advanced functionality, and how to train certain models used in some cleanlab tutorials.
To quickly learn how to run cleanlab on your own data, first check out the quickstart tutorials before diving into the examples below. Our blog demonstrates many more applications beyond these code examples.
| Example | Description |
|---|---|
| datalab | Use Datalab to detect various types of data issues in (a subset of) the Caltech-256 image classification dataset. |
| llm_evals_w_crowdlab | Reliable LLM Evaluation with multiple human/AI reviewers of varying competency (via CROWDLAB and LLM-as-judge GPT token probabilities). |
| fine_tune_LLM | Fine-tuning OpenAI language models with noisily labeled text data |
| entity_recognition | Train Transformer model for Named Entity Recognition and produce out-of-sample pred_probs for cleanlab.token_classification. |
| multiannotator_cifar10 | Iteratively improve consensus labels and trained classifier from data labeled by multiple annotators. |
| active_learning_multiannotator | Improve a classifier model by iteratively collecting additional labels from data annotators. This active learning pipeline considers data labeled in batches by multiple (imperfect) annotators. |
| active_learning_single_annotator | Improve a classifier model by iteratively labeling batches of currently-unlabeled data. This demonstrates a standard active learning pipeline with at most one label collected for each example (unlike our multi-annotator active learning notebook which allows re-labeling). |
| active_learning_transformers | Improve a Transformer model for classifying politeness of text by iteratively labeling and re-labeling batches of data using multiple annotators. If you haven't done active learning with re-labeling, try the active_learning_multiannotator notebook first. |
| outlier_detection_cifar10 | Train AutoML for image classification and use it to detect out-of-distribution images. |
| multilabel_classification | Find label errors in an image tagging dataset (CelebA) using a Pytorch model you can easily train for multi-label classification. |
| find_label_errors_iris | Find label errors introduced into the Iris classification dataset. |
| classifier_comparison | Use CleanLearning to train 10 different classifiers on 4 dataset distributions with label errors. |
| hyperparameter_optimization | Hyperparameter optimization to find the best settings of CleanLearning's optional parameters. |
| simplifying_confident_learning | Straightforward implementation of Confident Learning algorithm with raw numpy code. |
| visualizing_confident_learning | See how cleanlab estimates parameters of the label error distribution (noise matrix). |
| find_tabular_errors | Handle mislabeled tabular data to improve a XGBoost classifier. |
| cnn_mnist | Finding label errors in MNIST image data with a Convolutional Neural Network. |
| huggingface_keras_imdb | CleanLearning for text classification with Keras Model + pretrained BERT backbone and Tensorflow Dataset. |
| fasttext_amazon_reviews | Finding label errors in Amazon Reviews text dataset using a cleanlab-compatible FastText model. |
| transformer_sklearn | How to use KerasWrapperModel to make any Keras model sklearn-compatible, demonstrated here for a BERT Transformer. |
| cnn_coteaching_cifar10 | Train a Convolutional Neural Network on noisily labeled Cifar10 image data using cleanlab with coteaching. |
| non_iid_detection | Use Datalab to detect non-IID sampling (e.g. drift) in datasets based on numeric features or embeddings. |
| object_detection | Train Detectron2 object detection model for use with cleanlab. |
| semantic segmentation | Train ResNeXt semantic segmentation model for use with cleanlab. |
| spurious correlations | Train a CNN model on spurious and non-spurious versions of a subset of Food-101 dataset. Use Datalab to detect issues in the spuriously correlated datasets. |
To run the latest example notebooks, you can install the dependencies required for each example by calling pip install -r requirements.txt inside the subfolder for that example (each example's subfolder contains a separate requirements.txt file).
It is recommended to run the examples with the latest stable cleanlab release (pip install cleanlab).
However be aware that notebooks in the master branch of this repository are assumed to correspond to master branch version of cleanlab, hence some very-recently added examples may require you to instead install the developer version of cleanlab (pip install git+https://github.com/cleanlab/cleanlab.git).
To see the examples corresponding to specific version of cleanlab, check out the Tagged Releases of this repository (e.g. the examples for cleanlab v2.1.0 are here).
For running older versions of cleanlab, look at the Tagged Releases of this repository to see the corresponding older versions of the example notebooks (e.g. the examples for cleanlab v2.0.0 are here).
See the contrib folder for examples from cleanlab versions prior to 2.0.0, which may be helpful for reproducing results from the Confident Learning paper.
Reproducing results in Confident Learning paper (click to learn more)
For additional details, check out the: confidentlearning-reproduce repository.
A step-by-step guide to reproduce these results is available here. This guide is also a good tutorial for using cleanlab on any large dataset. You'll need to git clone
confidentlearning-reproduce which contains the data and files needed to reproduce the CIFAR-10 results.
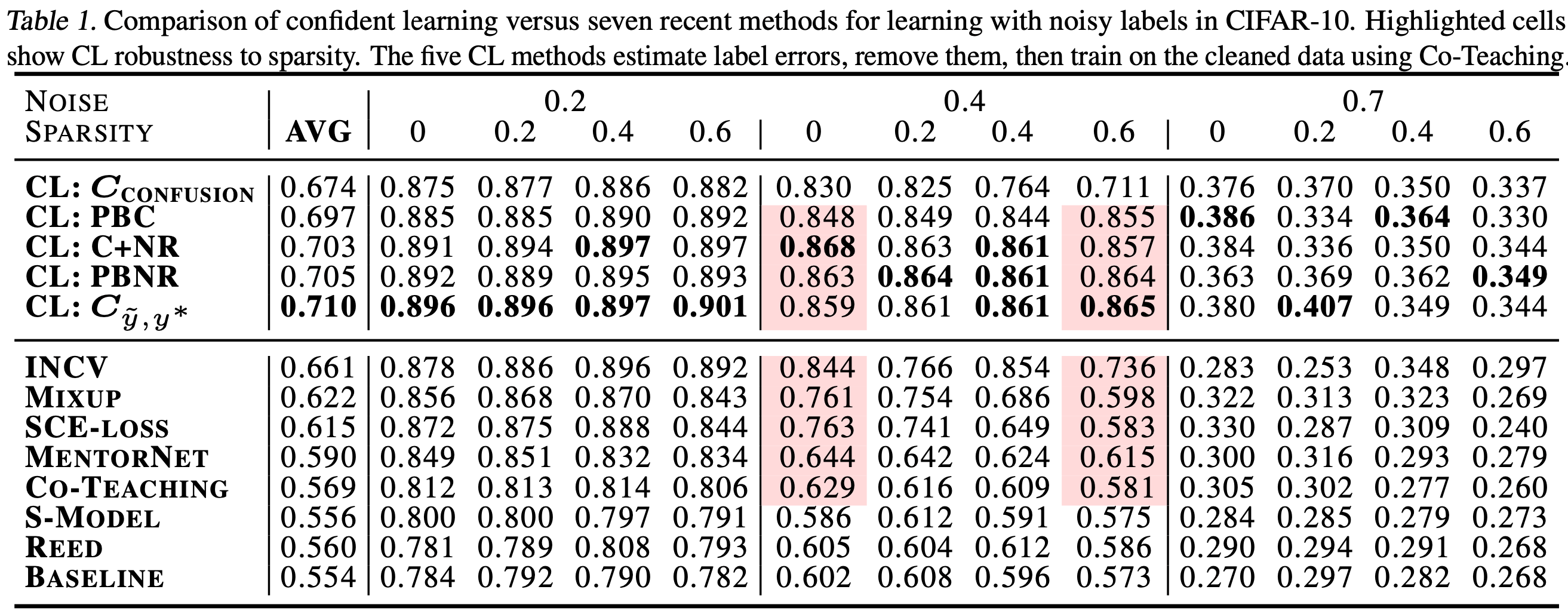
Comparison of confident learning (CL), as implemented in cleanlab, versus seven recent methods for learning with noisy labels in CIFAR-10. Highlighted cells show CL robustness to sparsity. The five CL methods estimate label issues, remove them, then train on the cleaned data using Co-Teaching.
Observe how cleanlab (i.e. the CL method) is robust to large sparsity in label noise whereas prior art tends to reduce in performance for increased sparsity, as shown by the red highlighted regions. This is important because real-world label noise is often sparse, e.g. a tiger is likely to be mislabeled as a lion, but not as most other classes like airplane, bathtub, and microwave.
Use cleanlab to identify ~100,000 label errors in the 2012 ILSVRC ImageNet training dataset: imagenet.
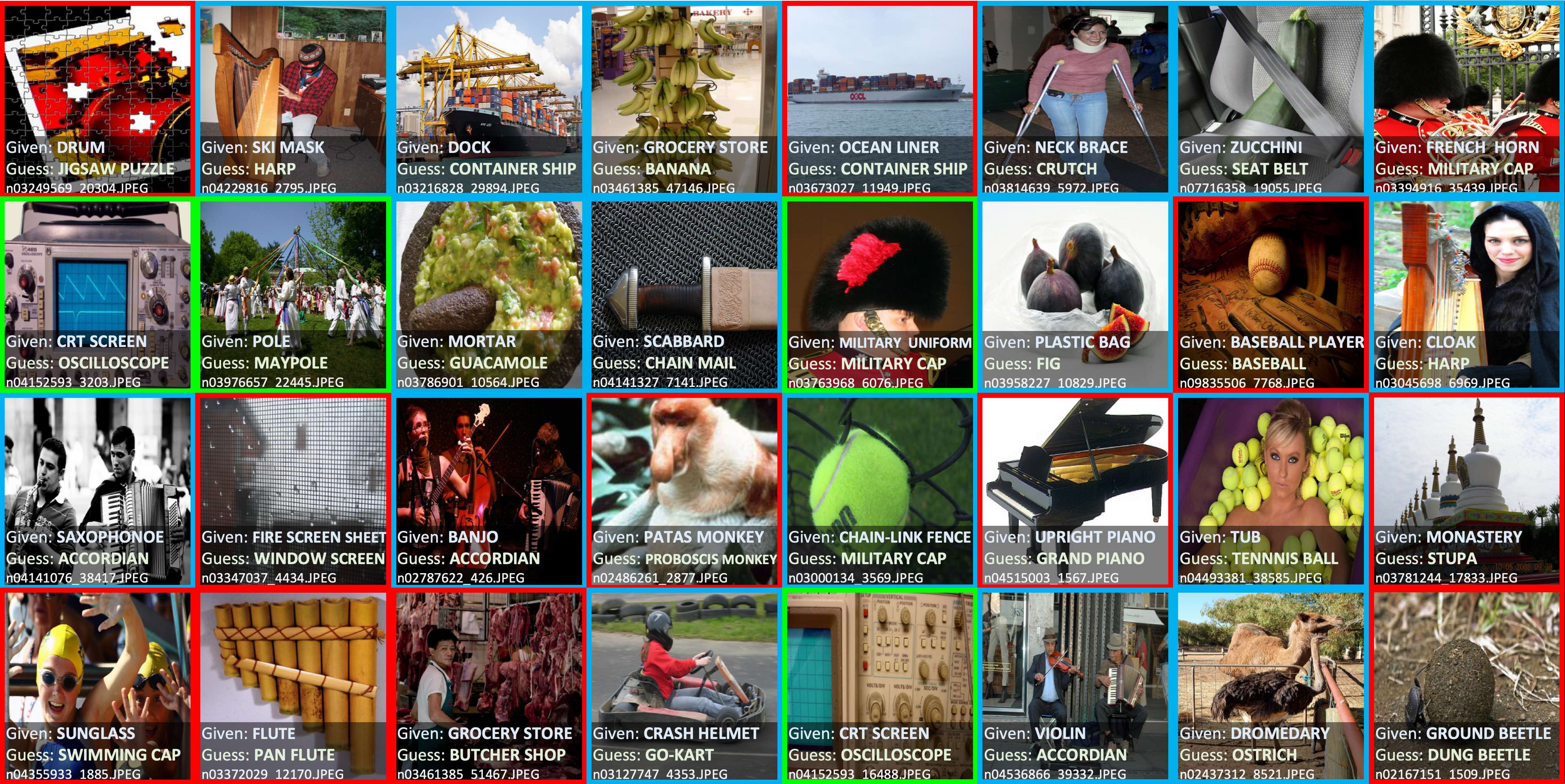
Label issues in ImageNet train set found via cleanlab. Label Errors are boxed in red. Ontological issues in green. Multi-label images in blue.
Use cleanlab to identify ~50 label errors in the MNIST dataset: mnist.
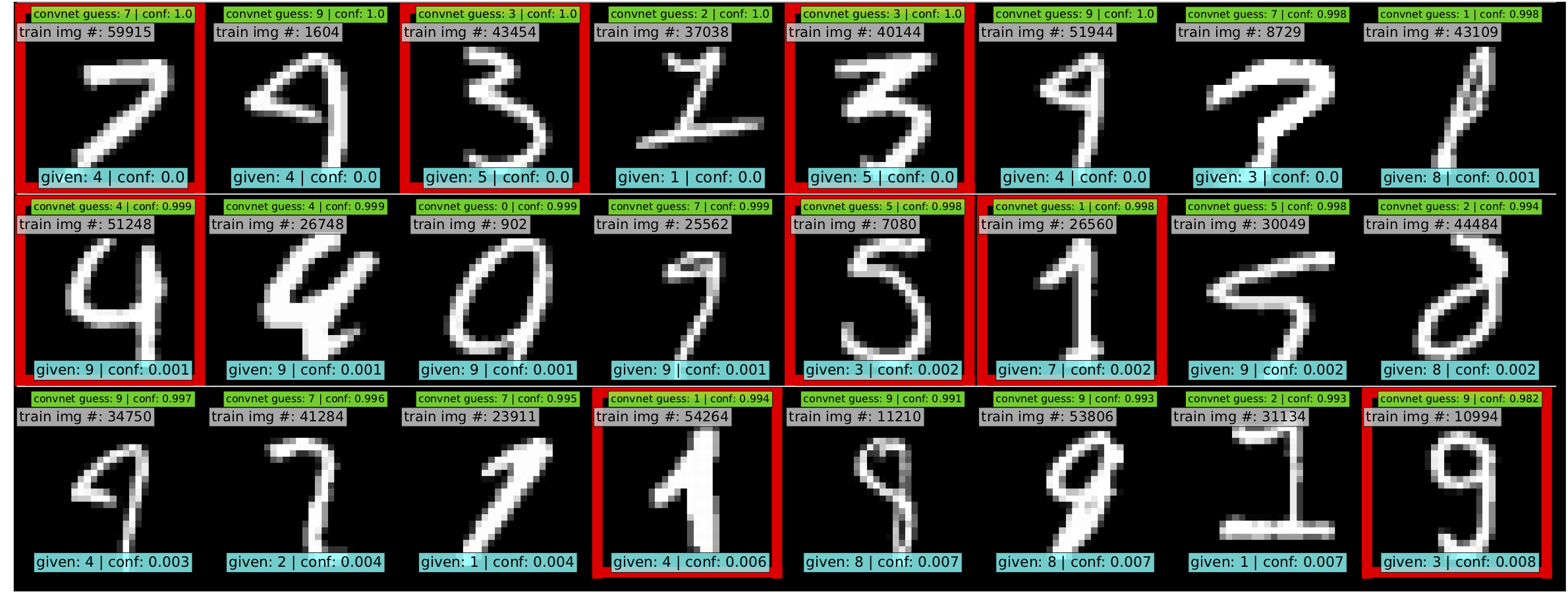
Top 24 least-confident labels in the original MNIST train dataset, algorithmically identified via cleanlab. Examples are ordered left-right, top-down by increasing self-confidence (predicted probability that the given label is correct), denoted conf in teal. The most-likely correct label (with largest predicted probability) is in green. Overt label errors highlighted in red.
Learning with noisy labels across 4 data distributions and 9 classifiers (click to learn more)
cleanlab is a general tool that can learn with noisy labels regardless of dataset distribution or classifier type: classifier_comparison.

Each sub-figure above depicts the decision boundary learned using cleanlab.classification.CleanLearning in the presence of extreme (~35%) label errors (circled in green). Label noise is class-conditional (not uniformly random). Columns are organized by the classifier used, except the left-most column which depicts the ground-truth data distribution. Rows are organized by dataset.
Each sub-figure depicts accuracy scores on a test set (with correct non-noisy labels) as decimal values:
- LEFT (in black): The classifier test accuracy trained with perfect labels (no label errors).
- MIDDLE (in blue): The classifier test accuracy trained with noisy labels using cleanlab.
- RIGHT (in white): The baseline classifier test accuracy trained with noisy labels.
As an example, the table below is the noise matrix (noisy channel) *P(s | y) characterizing the label noise for the first dataset row in the figure. s represents the observed noisy labels and y represents the latent, true labels. The trace of this matrix is 2.6. A trace of 4 implies no label noise. A cell in this matrix is read like: "Around 38% of true underlying '3' labels were randomly flipped to '2' labels in the observed dataset."
p(label︱y) |
y=0 | y=1 | y=2 | y=3 |
|---|---|---|---|---|
| label=0 | 0.55 | 0.01 | 0.07 | 0.06 |
| label=1 | 0.22 | 0.87 | 0.24 | 0.02 |
| label=2 | 0.12 | 0.04 | 0.64 | 0.38 |
| label=3 | 0.11 | 0.08 | 0.05 | 0.54 |
ML research using cleanlab (click to learn more)
Researchers may find some components of the cleanlab package useful for evaluating algorithms for ML with noisy labels. For additional details/notation, refer to the Confident Learning paper.
cleanlab supports a number of functions to generate noise for benchmarking and standardization in research. This next example shows how to generate valid, class-conditional, uniformly random noisy channel matrices:
# Generate a valid (necessary conditions for learnability are met) noise matrix for any trace > 1
from cleanlab.benchmarking.noise_generation import generate_noise_matrix_from_trace
noise_matrix=generate_noise_matrix_from_trace(
K=number_of_classes,
trace=float_value_greater_than_1_and_leq_K,
py=prior_of_y_actual_labels_which_is_just_an_array_of_length_K,
frac_zero_noise_rates=float_from_0_to_1_controlling_sparsity,
)
# Check if a noise matrix is valid (necessary conditions for learnability are met)
from cleanlab.benchmarking.noise_generation import noise_matrix_is_valid
is_valid=noise_matrix_is_valid(
noise_matrix,
prior_of_y_which_is_just_an_array_of_length_K,
)For a given noise matrix, this example shows how to generate noisy labels. Methods can be seeded for reproducibility.
# Generate noisy labels using the noise_marix. Guarantees exact amount of noise in labels.
from cleanlab.benchmarking.noise_generation import generate_noisy_labels
s_noisy_labels = generate_noisy_labels(y_hidden_actual_labels, noise_matrix)
# cleanlab is a full of other useful methods for learning with noisy labels.
# The tutorial stops here, but you don't have to. Inspect method docstrings for full docs.cleanlab for advanced users (click to learn more)
Many methods and their default parameters are not covered here. Check out the documentation for the developer version (aka master branch) for the full suite of features supported by the cleanlab API.
pred_probs (num_examples x num_classes matrix of predicted probabilities) should already be computed on your own, with any classifier. For best results, pred_probs should be obtained in a holdout/out-of-sample manner (e.g. via cross-validation).
- cleanlab can do this for you via
cleanlab.count.estimate_cv_predicted_probabilities - Tutorial with more info: here
- Examples how to compute pred_probs with: CNN image classifier (PyTorch)
# label issues are ordered by likelihood of being an error. First index is most likely error.
from cleanlab.filter import find_label_issues
ordered_label_issues = find_label_issues( # One line of code!
labels=numpy_array_of_noisy_labels,
pred_probs=numpy_array_of_predicted_probabilities,
return_indices_ranked_by='normalized_margin', # Orders label issues
)Pre-computed out-of-sample predicted probabilities for CIFAR-10 train set are available: here.
s denotes a random variable that represents the observed, noisy label and y denotes a random variable representing the hidden, actual labels. Both s and y take any of the m classes as values. The cleanlab package supports different levels of granularity for computation depending on the needs of the user. Because of this, we support multiple alternatives, all no more than a few lines, to estimate these latent distribution arrays, enabling the user to reduce computation time by only computing what they need to compute, as seen in the examples below.
Throughout these examples, you’ll see a variable called confident_joint. The confident joint is an m x m matrix (m is the number of classes) that counts, for every observed, noisy class, the number of examples that confidently belong to every latent, hidden class. It counts the number of examples that we are confident are labeled correctly or incorrectly for every pair of observed and unobserved classes. The confident joint is an unnormalized estimate of the complete-information latent joint distribution, Ps,y.
The label flipping rates are denoted P(s | y), the inverse rates are P(y | s), and the latent prior of the unobserved, true labels, p(y).
Most of the methods in the cleanlab package start by first estimating the confident_joint. You can learn more about this in the confident learning paper.
from cleanlab.count import estimate_latent
from cleanlab.count import estimate_confident_joint_and_cv_pred_proba
# Compute the confident joint and the n x m predicted probabilities matrix (pred_probs),
# for n examples, m classes. Stop here if all you need is the confident joint.
confident_joint, pred_probs = estimate_confident_joint_and_cv_pred_proba(
X=X_train,
labels=train_labels_with_errors,
clf=logreg(), # default, you can use any classifier
)
# Estimate latent distributions: p(y) as est_py, P(s|y) as est_nm, and P(y|s) as est_inv
est_py, est_nm, est_inv = estimate_latent(
confident_joint,
labels=train_labels_with_errors,
)from cleanlab.count import estimate_py_noise_matrices_and_cv_pred_proba
est_py, est_nm, est_inv, confident_joint, pred_probs = estimate_py_noise_matrices_and_cv_pred_proba(
X=X_train,
labels=train_labels_with_errors,
)# Already have pred_probs? (n x m matrix of predicted probabilities)
# For example, you might get them from a pre-trained model (like resnet on ImageNet)
# With the cleanlab package, you estimate directly with pred_probs.
from cleanlab.count import estimate_py_and_noise_matrices_from_probabilities
est_py, est_nm, est_inv, confident_joint = estimate_py_and_noise_matrices_from_probabilities(
labels=train_labels_with_errors,
pred_probs=pred_probs,
)The joint probability distribution of noisy and true labels, P(s,y), completely characterizes label noise with a class-conditional m x m matrix.
from cleanlab.count import estimate_joint
joint = estimate_joint(
labels=noisy_labels,
pred_probs=probabilities,
confident_joint=None, # Provide if you have it already
)Positive-Unlabeled Learning (click to learn more)
Positive-Unlabeled (PU) learning (in which your data only contains a few positively labeled examples with the rest unlabeled) is just a special case of CleanLearning when one of the classes has no error. P stands for the positive class and is assumed to have zero label errors and U stands for unlabeled data, but in practice, we just assume the U class is a noisy negative class that actually contains some positive examples. Thus, the goal of PU learning is to (1) estimate the proportion of negatively labeled examples that actually belong to the positive class (seefraction\_noise\_in\_unlabeled\_class in the last example), (2) find the errors (see last example), and (3) train on clean data (see first example below). cleanlab does all three, taking into account that there are no label errors in whichever class you specify as positive.
There are two ways to use cleanlab for PU learning. We'll look at each here.
Method 1. If you are using the cleanlab classifier CleanLearning(), and your dataset has exactly two classes (positive = 1, and negative = 0), PU learning is supported directly in cleanlab. You can perform PU learning like this:
from cleanlab.classification import CleanLearning
from sklearn.linear_model import LogisticRegression
# Wrap around any classifier. Yup, you can use sklearn/pyTorch/TensorFlow/FastText/etc.
pu_class = 0 # Should be 0 or 1. Label of class with NO ERRORS. (e.g., P class in PU)
cl = CleanLearning(clf=LogisticRegression(), pulearning=pu_class)
cl.fit(X=X_train_data, labels=train_noisy_labels)
# Estimate the predictions you would have gotten by training with *no* label errors.
predicted_test_labels = cl.predict(X_test)Method 2. However, you might be using a more complicated classifier that doesn't work well with CleanLearning (see this example for CIFAR-10). Or you might have 3 or more classes. Here's how to use cleanlab for PU learning in this situation. To let cleanlab know which class has no error (in standard PU learning, this is the P class), you need to set the threshold for that class to 1 (1 means the probability that the labels of that class are correct is 1, i.e. that class has no error). Here's the code:
import numpy as np
# K is the number of classes in your dataset
# pred_probs are the cross-validated predicted probabilities.
# s is the array/list/iterable of noisy labels
# pu_class is a 0-based integer for the class that has no label errors.
thresholds = np.asarray([np.mean(pred_probs[:, k][s == k]) for k in range(K)])
thresholds[pu_class] = 1.0Now you can use cleanlab however you were before. Just be sure to pass in thresholds as a parameter wherever it applies. For example:
# Uncertainty quantification (characterize the label noise
# by estimating the joint distribution of noisy and true labels)
cj = compute_confident_joint(s, pred_probs, thresholds=thresholds, )
# Now the noise (cj) has been estimated taking into account that some class(es) have no error.
# We can use cj to find label errors like this:
indices_of_label_issues = find_label_issues(s, pred_probs, confident_joint=cj, )
# In addition to label issues, cleanlab can find the fraction of noise in the unlabeled class.
# First we need the inv_noise_matrix which contains P(y|s) (proportion of mislabeling).
_, _, inv_noise_matrix = estimate_latent(confident_joint=cj, labels=s, )
# Because inv_noise_matrix contains P(y|s), p (y = anything | labels = pu_class) should be 0
# because the prob(true label is something else | example is in pu_class) is 0.
# What's more interesting is p(y = anything | s is not put_class), or in the binary case
# this translates to p(y = pu_class | s = 1 - pu_class) because pu_class is 0 or 1.
# So, to find the fraction_noise_in_unlabeled_class, for binary, you just compute:
fraction_noise_in_unlabeled_class = inv_noise_matrix[pu_class][1 - pu_class]Now that you have indices_of_label_errors, you can remove those label issues and train on clean data (or only remove some of the label issues and iteratively use confident learning / cleanlab to improve results).
If you'd like to accomplish any of the workflows demonstrated in these notebooks without having to: write code, train your own machine learning system, or set up your own interface to the data/results, then try Cleanlab Studio. This platform integrates Cleanlab data quality algorithms with the best AI and interfaces to automatically find and fix issues in datasets. There is no easier way to turn unreliable raw data into reliable models/analytics.

Copyright (c) 2017 Cleanlab Inc.
All files listed above and contained in this folder (https://github.com/cleanlab/examples) are part of cleanlab.
cleanlab is free software: you can redistribute it and/or modify it under the terms of the GNU Affero General Public License as published by the Free Software Foundation, either version 3 of the License, or (at your option) any later version.
cleanlab is distributed in the hope that it will be useful, but WITHOUT ANY WARRANTY; without even the implied warranty of MERCHANTABILITY or FITNESS FOR A PARTICULAR PURPOSE. See the GNU Affero General Public License for more details.
You should have received a copy of the GNU Affero General Public License in LICENSE.