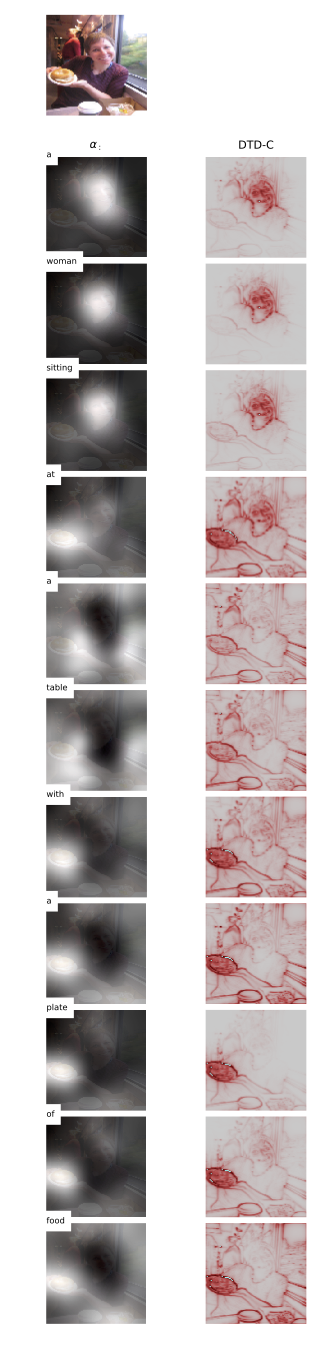
Generates caption for an image and creates heatmap that highlights image pixels that were important for attention mechanism. For implementation details see Thesis.
Example output:
Setup:
- create Python 2 virtual environment and activate the environment
virtualenv ~/.venvs/image-captioning
source ~/.venvs/image-captioning/bin/activate
- install Python dependencies with
pip install -r requirements.txt
- download VGG16 pretrained weights
wget -P data ftp://mi.eng.cam.ac.uk/pub/mttt2/models/vgg16.npy
- download pretrained image captioning model (trained by Christopher Lennan) and unzip
wget https://www.dropbox.com/s/laexkey0a4hqc9u/models.zip &&
unzip models.zip &&
rm models.zip
Generate heatmaps:
- choose image file to generate heatmaps and caption for (e.g. ./data/COCO_val2014_000000038678.jpg)
- choose pretrained model folder (e.g. ./models)
- choose DTD approach (dtda, dtdb, or dtdc)
- choose alpha for DTD-C approach (optional, default 2)
python -m evaluater.heatmap \
--image-file data/COCO_val2014_000000038678.jpg \
--pretrained-model-folder models \
--approach dtdc \
--alpha 2
- generated heatmaps are saved in
resultsfolder
Train:
- download images and label files from http://cocodataset.org/#download
- create training dataset with
python -m tools.convert_to_tfrecords \
--images-dir /path/to/train/images \
--label-file /path/to/train/labels \
--save-dir data \
--train True
- set hyperparameters in
trainer/train.py(bottom) and run
python -m trainer.train \
--train-file /path/to/tfrecords \
--job-dir data \
--weights-file data/vgg16.npy \
--bias-file data/word_bias_init.npy \
--dict-file data/dict_top_words_to_index.npy