极市平台打榜使用的yolov5模板
冠军方案代码分享 ECV2022|沿街晾晒识别冠军方案
需要填补类别
- preprocess.py
- ji.py
- /yolov5/data/cvmart.yaml
1)目标描述 (了解应用场景)
算法报警的业务逻辑:利用开关,控制识别到占道经营,违规晾晒的行为,触发报警。
识别场景:街道
识别对象:
1)悬挂式的衣服/被子等物品(小目标例如一条毛巾、一个梳子、一条鱼不识别,当数量大于5时,可以识别)
2)占道行为摊位
环境要求:白天,或光线充足
算法准确率:85%
2) 数据描述
标注方式:2D 框标注
标签:
固定摆摊fixed_stall:街道、人行道周边的地面摊位,确认在摆摊
遮阳伞sunshade:遮阳伞、临时贩卖小棚
晾晒物:drying_object


其实就是把占道的各种行为识别出来,保证道路畅通。
看看大致的数据分布制定训练策略,决定使用模型,对以后调参也有帮助。
1) 探索性数据分析(EDA)--数据集信息


数据量够大了,为了保证训练速度跟推理速度,选择轻量级模型yolo系列,这也是工业上应用比较广泛的模型。其中我使用的YOLOv5s网络体积最小,速度最快。我确实更喜欢小模型,训练起来更容易。因为有性能分,模型融合、测试时增强(TTA)就不考虑了。


2)探索性数据分析(EDA) — 标签数量
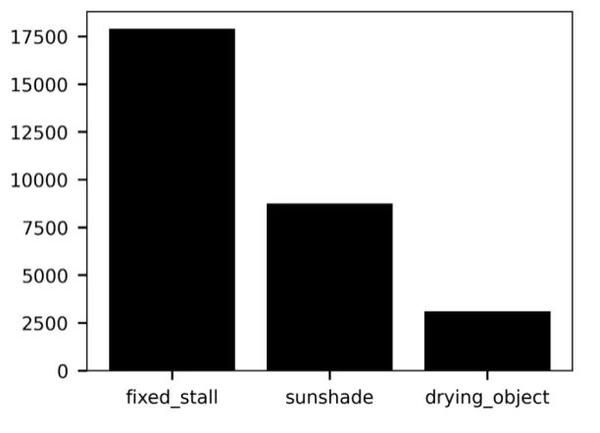

标签数量差距大,类别不均衡,是长尾分布。因此我考虑两个策略:数据增强用Mosaic数据增强 + 损失函数用Focal loss。
这也是应对数据不均衡比较常规的想法,而且都很有效。
3)探索性数据分析(EDA)--标注框
标注框绝对大小:


标注框相对大小:
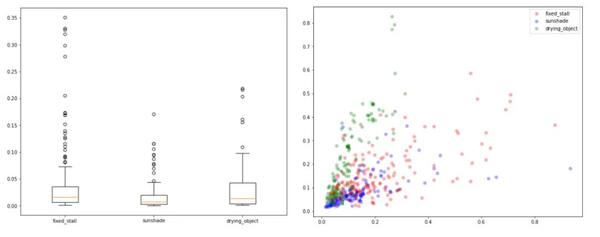

可以发现Anchor的特点有:小目标为主,偶尔有大目标,我通过聚类确定anchor大小。
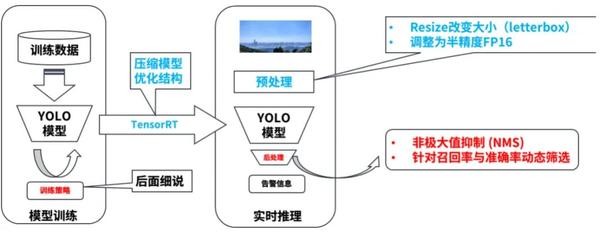

这里主要分成3部分。
- Yolo 模型的选择 : v5 还是 v6?
- 我所用的策略
- 更多可能性的探讨
比赛进行的时候我在网上看到了yolov6的信息,但那时候我已经训练出了Yolo V5s。但还是试了下YoloV6.下面总结下我对两个框架的感受。
1)Yolo v5
- 我一直在用;有一套熟悉的代码模板,训练超参数
- 发布时间久,更成熟,tensorRT转换与半精度推理资料更多
- 训练快(相比YOLO v6)
2)Yolo v6
- Anchor-free,在训练之前无需进行聚类分析以确定最佳anchor集合
- 论文数据,在精度与推理速度超过Yolo v5
Yolov6的Anchor-free很吸引我,但无奈训练太慢了,最后我训练epochs少于v5,可能因此效果不如v5.并且我没有对v6进行tensorrt转换,这也是性能分较低的原因吧。




其中蓝色为了推理速度设计,红色为了模型精度。下面分别介绍:
1)针对性调整训练类别
这里说的“针对性”是针对评分榜单。我发现实战榜只是计算drying_object的f-score,这样的话其他标签就不是很有价值了。于是我修改3分类为1分类,舍弃其他标签,把参数用到该用的地方。这样其实不用考虑类别不均衡问题了,但后面还是照之前想法做了。


2)灵活调整训练策略
这里介绍我的训练策略。因为极市的训练超过12小时会被终止,正好可以作为一个阶段。因此我分为三个阶段,分阶段调整训练策略。
第一阶段,使用强数据增强,img_size = 640,默认损失函数;
第二阶段,换上弱数据增强,img_size减小到480,损失函数用Focal Loss;
第三阶段进行微调,使模型适应原始图像,无数据增强,img_size = 480,但是低学习率,防止过拟合。
3)多尺度训练
尺度小的话图片测试速度快,准确度低。尺度大的话测试速度慢,但准确度高。使用多尺度训练能提高检测模型对物体大小的鲁棒性,提高模型精度。
4)TensorRT:
TensorRT几乎是必须了。TensorRT是Nvidia为了加速基于GPU训练模型的推理而设计,能有效加速模型的推理部署。加上使用半精度FP16,推理速度可以提高一倍甚至更多,且精度基本不会受到影响。
5)Optuna调整推理超参数
Optuna是我用LGBM时了解的,是一个特别为机器学习设计的自动超参数优化软件框架,通过在搜索空间进行多次实验来寻找最佳超参数,可谓调参利器。我用的超参数主要是非极大值抑制(NMS)的了,我基于划分的验证集,使用Optuna搜索最佳超参数,最后寻找到NMS超参数为conf_thres = 0.12,iou_thres = 0.31。
6)划定不同类别阈值筛选
因为我只有一类,所以阈值就统一了。多类的情况下可以分别指定。


想法就是参考召回率跟精确率,务求两者平衡得到最高f-score。针对召回率与精确率不匹配的情况,用低的conf_threshold保证召回,分类别划定筛选阈值保证精确率。
以下介绍一些我想到但未实现(完善)的想法:


1)Yolo v5 模型剪枝
我尝试了下Yolo v5 模型剪枝。剪枝的好处有使模型轻量,便于部署,而且加快推理速度 (CPU)。使用论文Soft Filter Pruning for Accelerating Deep Convolutional Neural Networks中提到的软剪枝方法,想法是降低模型宽度,减少特征图通道数。使用0.7的剪枝率,权重文件确实小了,但是GPU推理速度下降,因此比赛中我没有使用。
2)小目标问题
这个赛题中小目标并不突出。我同时进行的其他榜单上会有一些,就一起处理了。


小目标的解决方案可以有:
- 修改网络结构,增加特征图融合程度
- 添加小瞄框
- 滑动窗口推理
- 增大输入图片大小
这里滑动窗口推理不太有必要(还有很多大目标),其他可以考虑。
3) Yolo v6
之前提到v6训练速度慢,我训练不充分,但这个很有潜力。我已经写好了数据转换、训练、推理脚本,其实和v5很像。
4)速度换精度


最后性能分很高了,可以考虑速度换精度的一些方法,比如特征图融合,更大图片尺寸。