Contador de palavras para a Competição AeroDesign // Word counter for the Aerodesign Competition
Author: Member of Comissao Tecnica Aerodesign
Geovana Neves (geovanan90@gmail.com)
Get the standalone application in the folder 'dist'
./dist/PyAeroCounter.exeor download here the .exe file
If you have any problem downloading the executable file, download the .zip that contains the PyAeroCounter.exe
./dist/PyAeroCounter.zipor download here the .zip file
This standalone application requires MikTeK and Tesseract OCR in order to execute properly, see item 3 of this file.
When the download is complete, it is recommended to create a folder and move the downloaded file to it.
It is necessary to place the .pdf file you want to count in the folder created earlier, together with the PyAeroCounter.exe file
PyAeroCounter.exe default input is to read a PDF document named 'pdffile.pdf'.
The default outputs include a log file containing the final result as well as text files with the extract text.
PyAeroCounter.exe also extract images from the PDF document and save them into 'PDFFILE' folder.
To start counting, just run the PyAeroCounter.exe file and wait for it to finish counting. When the console closes, the count is finished and the logfile.txt file can be opened to check the count values.
For different options, use the command line:
Example 1:
PyAeroCounter.exe -i EXAMPLE.pdf -d EXAMPLE_IMAGESAvailable options:
-o : logfile filename (string)
-w : wordsfile filename (string)
-n : nonwordsfile filename (string)
-d : images_folder name (string)
-i : pdffile filename (string)
-e : extract images (boolean, integer: 0 or 1)
-f : strings_figures filename (string)
-g : mathmodewords filename (string)In order to properly handle images and its content, the user must have the following softwares installed:
Download here
Tesseract repo: https://github.com/tesseract-ocr/tesseract
In order for Tesseract to function correctly, it is necessary to create the Tesseract PATH environment variable.
-
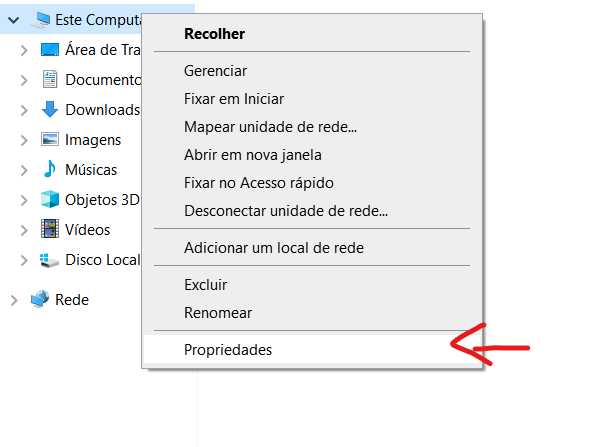
Right click on "This computer", another menu will open, click on the last option, named "Properties"
-
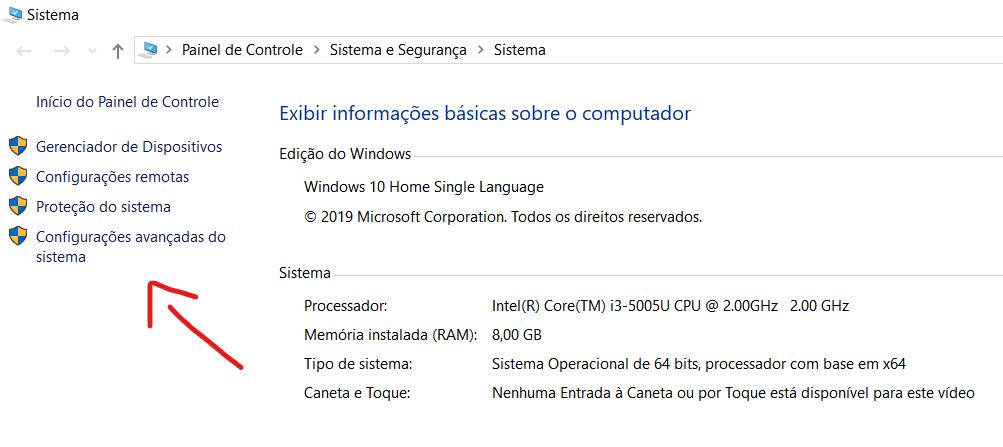
Then, in the left-hand menu, click on the last option, whose name is 'Advanced system settings'
-
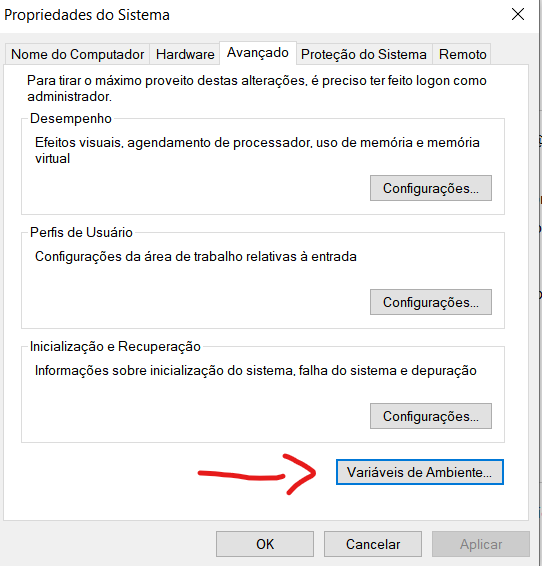
Click on the 'Environment Variables' option
-
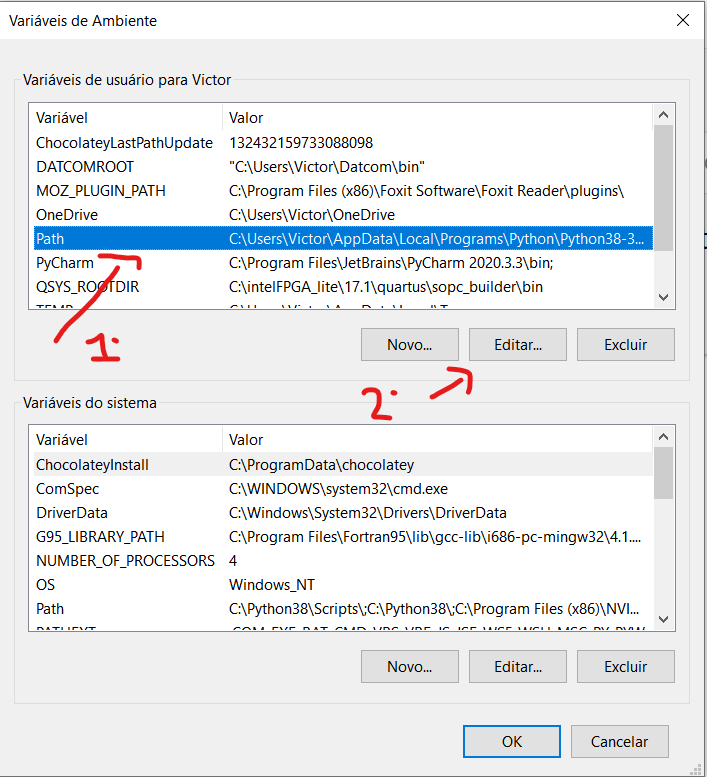
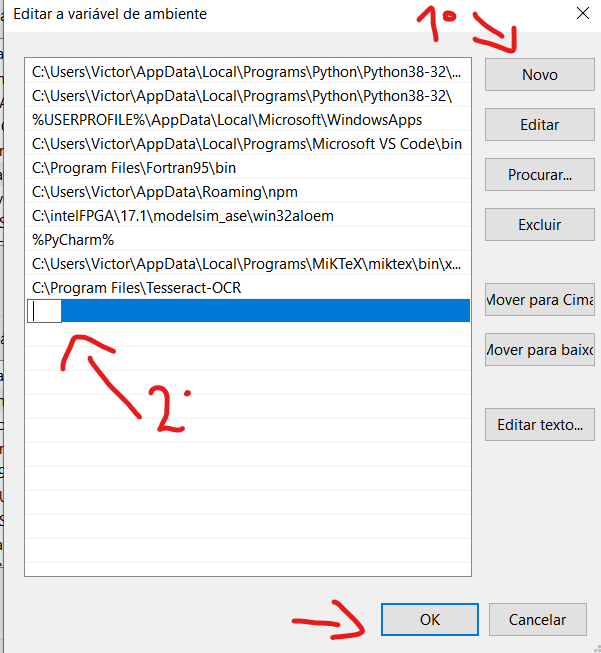
Look for the 'Path' variable, click on it and then click on edit, as shown in the image.
-
Click on 'New' to create a new variable, and paste the directory in which Tesseract is installed, it is usually installed in C: \ Program Files \ Tesseract-OCR, in the location indicated with a 2 in the image. After doing this, click on 'OK'.
-
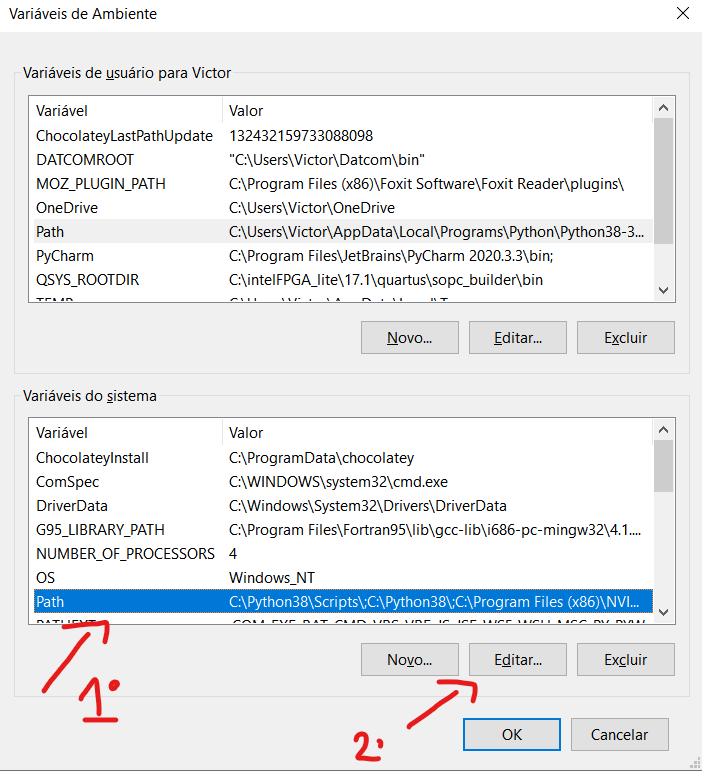
Similar to step x, now in the system variables, click on 'Path' and then click on 'new'.
-
Repeat the step 5.
-
After finishing, press 'Ok' on all screens to close and save the process.






If the user does not install the above software, PyAeroCounter.exe will not extract image and read the text from it.
pdfminer3
pytesseract (It requires the installation of the Google's Tesseract-OCR Engine)
------ Check the source code for more information.
WARNING: The pdfminer3 package was modified during the development of the PyAeroCounter script.
Substitute the following installed scripts in your computer for the ones provided in 'auxiliar' folder:
cmapdb.py
converter.pyGet it: https://pypi.org/project/pyinstaller/
pyinstaller --onefile --nowindowed PyAeroCounter.pyIf you have any problem or suggestion, please send it to www.aeroct.com.br