lightspeedEmbeddings
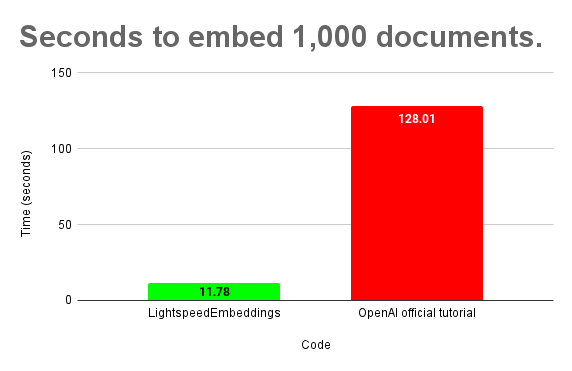
Use multithreading to get vector embeddings 10x faster. Built for the OpenAI text-ada-002 model.
100 stars => command line script + more features & customization
This Python code uses OpenAI's Ada API to generate embedding vectors for text data. Embeddings are powerful representations of text data for use in machine learning models. This code is designed to work with Google Colab to make things easy.
Prerequisites
To run this code, you will need:
- An OpenAI API key (which you can obtain from the OpenAI website)
- A Google Colab account to run the code (Google Colab is a free environment for running Jupyter notebooks using Google's cloud infrastructure).
Run the demo in TWO STEPS!
- Put your OpenAI API key into the demo.ipynb code (you can open in Colab)
- Upload the Fine Food Reviews dataset into Colab.
Then, just hit run on the code cells!
Installation
This code uses several Python modules that may need to be installed (easily) with pip. The modules and their installation commands are listed below:
pip install openai
pip install pandas
pip install tiktoken
pip install tqdm
How to Use
- Enter your OpenAI API key into the code.
- Upload a CSV file containing the text data you want to generate embeddings for in one column, named 'combined'. You can download the sample dataset CSV and upload it. You should have no missing values in your 'combined' column. I recommend that this column contains the concatenated titles and contents for the text you want to embed. The title usually has valuable keywords that hint at the content of the full text.
- Update the
input_datapathvariable with the file name of your uploaded CSV file. - Update the
output_file_namevariable with the desired name for the output CSV file that will contain the generated embeddings. - Update the
embedding_modelvariable if desired (the default is "text-embedding-ada-002"). This is not recommended - Adjust the max_tokens. This is the maximum length of texts that will be allowed. This can't exceed 8,000 due to Ada limits on length.
- Run the code. The embeddings will be generated and saved to the output CSV file.
- Important: When generating embeddings, the code provides two methods:
- The "filter" method removes any texts that are longer than the set maximum tokens (default is 4000 tokens in the demo), while
- The "truncate" method removes any tokens from long texts that exceed the set maximum tokens limit. Whichever method you choose, pass it to the
methodparameter while calling theprocess_datafunction. Truncate is recommended.