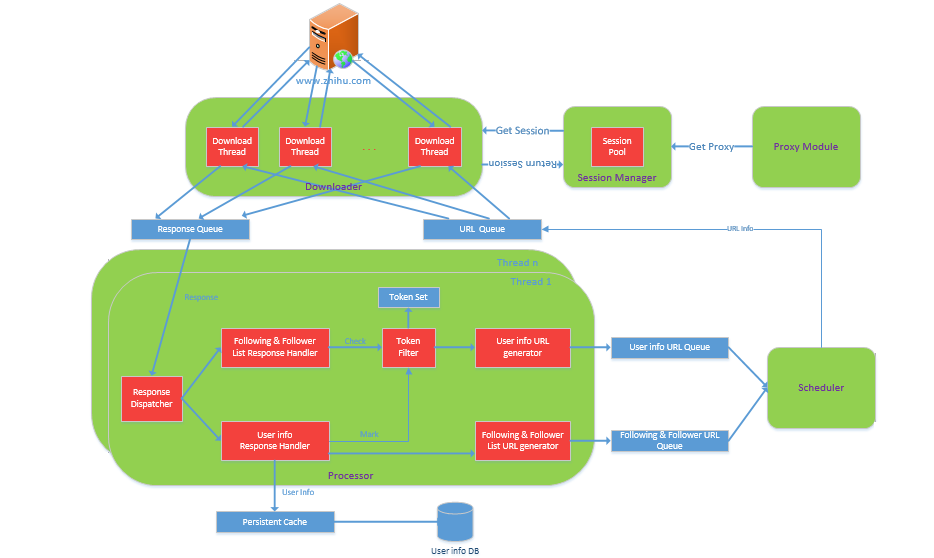
- 除了爬取用户信息外,还可以选择爬取用户之间的关注关系
- 使用多线程爬取,并可以自行配置使用的线程数目
- 使用Redis作为任务队列
- 使用高匿代理IP进行数据的爬取,并且失效后会重新分配新的可用代理,避免频繁访问导致本机 IP 被封
- 可以启用邮件定时通知功能
- Python 版本:3.0 以上
- 数据库:MySQL、Redis
项目中使用到的 Python 第三方库如下:
- requests——一个非常好用的请求库,http://docs.python-requests.org/en/master/
- pymysql——python 与 MySQL 连接,https://github.com/PyMySQL/PyMySQL
- BeautifulSoup——简单但是强大的网页文档解析库,https://www.crummy.com/software/BeautifulSoup/bs4/doc/
- Redis-py——Redis Python客户端,How To Configure a Redis Cluster on CentOS 7


用户Token是注册知乎账号时设置的一个非中文昵称,通过其可唯一确定某一个用户。同时由于URL中也是通过该Token区分不同用户的页面,所以我们可以很容易的利用token来爬取
爬虫中用到3类URL,分别是:
-
用户与获取用户详细信息:
https://www.zhihu.com/people/excited-vczh/pins个人认为用户详细信息仅仅在加载用户信息页时已经在后端进行渲染一同载入,数据放在
id为data的<div>标签中的data-state属性,目前没有找到可以直接提取数据的接口,所以只能够选择一个数据量较少的页面整个爬取 -
用户正在关注列表信息:
http://www.zhihu.com/api/v4/members/xzer/followees?limit=20&offset=0该URL需要用户登陆后才用权限获取数据,返回的数据格式为JSON,URL的参数:
limit列表分页大小,offset列表分页偏移值 -
用户关注者列表信息:
http://www.zhihu.com/api/v4/members/xzer/followers?limit=20&offset=0该URL需要用户登陆后才用权限获取数据,返回的数据格式为JSON,URL的参数:
limit列表分页大小,offset列表分页偏移值
本爬虫的目标是爬取知乎中用户公开的个人信息,例如:
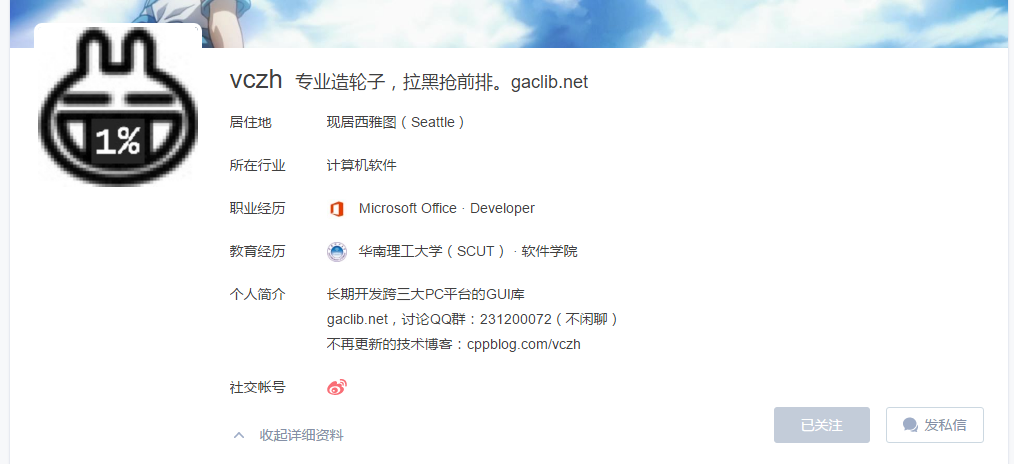
由于其中包含的信息较多,这个知乎爬虫只是选择了其中一些比较有意义的信息进行爬取。具体的信息包括:
| 字段 | 含义 |
|---|---|
| avator_url | 用户头像URL |
| token | 用户标识字段 |
| headline | 用户的一句话介绍 |
| location | 居住地 |
| business | 所在行业 |
| employments | 工作经历 |
| educations | 教育经历 |
| description | 用户描述 |
| sinaweibo_url | 新浪微博网址(知乎貌似已不再提供) |
| gender | 性别 |
| followingCount | 该用户正在关注的用户数目 |
| followerCount | 关注该用户的用户数目 |
| answerCount | 该用户回答的问题的数目 |
| questionCount | 该用户提问的问题数目 |
| voteupCount | 该用户获得赞的数目 |
| userName | 用户昵称 |
-
安装指定版本的 Python
-
执行
pip3 install -r requirements.txt命令安装数据库、以及必须的第三方库 -
配置程序中的数据库配置
-
打开
SpiderCoreConfig.conf文件,修改MySQL的配置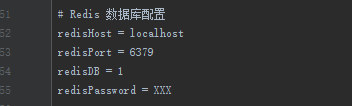
-
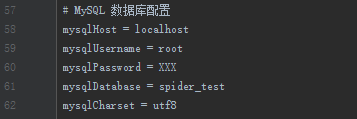
在同一个文件下,修改Redis的配置、
-
-
执行
db.sql文件,创建使用到的数据库以及表 -
添加若干个初始的用户 token,程序运行后将会以这个用户开始搜索
-
修改
SpiderCoreConfig.conf文件中里面的的startToken变量的值为初始的用户token(可以设置多个)# 初始token(如果有多个初始token, 使用‘,’分隔) initToken = excited-vczh
-
-
配置数据下载以及数据处理的线程数目
- 数据下载线程数目,修改
SpiderCoreConfig.conf文件中的downloadThreadNum,默认为10个线程

- 数据处理线程数目,修改
SpiderCoreConfig.conf文件中的processThreadNum,默认为3个线程

- 数据下载线程数目,修改
-
配置是否使用代理
-
使用代理可避免爬虫频繁访问导致IP被屏蔽。修改
SpiderCoreConfig.conf文件中的isProxyServiceEnable,值为1代表启动,0代表关闭# 是否启用代理服务(1代表是,0代表否) isProxyServiceEnable = 1
-
-
知乎账户配置
-
配置登陆方式。设定配置文件的
isLoginByCookie字段, 若值为1则使用Cookie方式登陆,若为1则使用普通方式(邮箱或手机号码)登陆# 是否使用Cookie登陆 isLoginByCookie = 1 -
配置登陆认证信息。以下两种登陆方式
- Cookie登陆方式。首先使用PC浏览器手动登陆知乎账号,然后从浏览器中将登陆成功后的Cookie配置到爬虫配置文件中。配置的cookie包括:
z_c0。(如何从浏览器获取Cookie不详述)
# Cookie 登陆方式配置 z_c0 = XXX- 普通方式。(当前不可用)配置知乎账户的账号和密码,最好不要使用自己的主账号(目前知乎的邮箱登陆和手机号码登陆方式均需要输入普通验证码或选择倒转文字验证码, 还没有解决)

- Cookie登陆方式。首先使用PC浏览器手动登陆知乎账号,然后从浏览器中将登陆成功后的Cookie配置到爬虫配置文件中。配置的cookie包括:
-
-
日志配置
-
可选择将程序运行信息输出到控制台,或者写入到日志文件中,选择哪一种方式在
Logger.py文件中配置。而日志级别等具体的设置在SpiderLoggingConfig.conf中配置
-
-
若使用的Window平台,打开CMD,打开项目所在的文件夹的根目录
-
输入
startup.py运行程序
需要注意的是,CMD的字符集需要设置为utf8,否则可能会出现问题
-
程序开始运行
-
运行结果

-
爬虫的相关参数在配置文件SpiderCore.conf中设置.具体如下:
[spider_core]
# 数据下载配置
# 是否启用代理服务(1代表是,0代表否)
isProxyServiceEnable = 1
# session pool 的大小
sessionPoolSize = 20
# 下载线程数量
downloadThreadNum = 5
# 网络连接错误重试次数
networkRetryTimes = 3
# 网络连接超时(单位:秒)
connectTimeout = 30
# 下载间隔
downloadInterval = 6
# 数据处理配置
# 数据处理线程数量
processThreadNum = 2
# 是否解析following列表(通过用户的正在关注列表获取下一批需要分析的token)
isParserFollowingList = 1
# 是否解析follower列表(通过用户的关注者列表获取下一批需要分析的token)
isParserFollowerList = 0
# URL调度配置
# 用户信息下载和用户关注列表下载URL比例(用户信息URL / URL总数, 例如:值为8,代表每次调度中80%是用户信息URL)
urlRate = 8
# 数据持久化配置
# 用户信息数据库写缓存大小(记录条数)
persistentCacheSize = 100
# 用户关注关系数据库写缓存大小
followRelationPersistentCacheSize = 500
# 邮件服务配置
# 是否启用邮件通知(1代表是,0代表否)
isEmailServiceEnable = 0
# SMTP邮件服务器域名
smtpServerHost = smtp.mxhichina.com
# SMTP邮件服务器端口
smtpServerPort = 25
# SMTP邮件服务器登陆密码
smtpServerPassword = XXX
# 邮件发送人地址
smtpFromAddr = centosserver@ken-ljq.xyz
# 邮件接收人地址
smtpToAddr = ljq1120799726@outlook.com
# 邮件标题
smtpEmailHeader = ZhiZhuSpiderNotification
# 邮件发送间隔(单位:秒)
smtpSendInterval = 3600
# Redis 数据库配置
redisHost = localhost
redisPort = 6379
redisDB = 1
redisPassword = XXX
# MySQL 数据库配置
mysqlHost = localhost
mysqlUsername = root
mysqlPassword = XXX
mysqlDatabase = spider_user
mysqlCharset = utf8
# 知乎登陆配置
# 是否使用Cookie登陆
isLoginByCookie = 1
# Cookie 登陆方式配置
z_c0 = XXX
# 普通登陆方式配置
loginToken = XXX
password = XXX
# 初始token(如果有多个初始token, 使用‘,’分隔)
initToken = excited-vczh
代理模块参数在配置文件proxyConfiguration.conf中设置.具体如下:
[proxy_core]
# 代理验证连接超时时长(单位:秒)
proxyValidate_connectTimeout = 30
# 代理验证重新连接次数
proxyValidate_networkReconnectTimes = 3
# 代理数据抓取连接超时时长(单位:秒)
dataFetch_connectTimeout = 30
# 代理数据抓取重新连接时间间隔(单位:秒)
dataFetch_networkReconnectInterval = 30
# 代理数据抓取重新连接次数
dataFetch_networkReconnectionTimes = 3
# 代理网页数据抓取起始页码
proxyCore_fetchStartPage = 1
# 代理网页数据抓取结束页码
proxyCore_fetchEndPage = 5
# 代理池大小(不大于100)
proxyCore_proxyPoolSize = 10
# 代理池更新扫描间隔
proxyCore_proxyPoolScanInterval = 300
# 代理验证线程数量
proxyCore_proxyValidateThreadNum = 5