本工具是python tkinter编写的一个简单的Gui,任务批量管理器。通过Gui选项生成CMD(command),来调用whisper,达到批量生成,管理的目的。
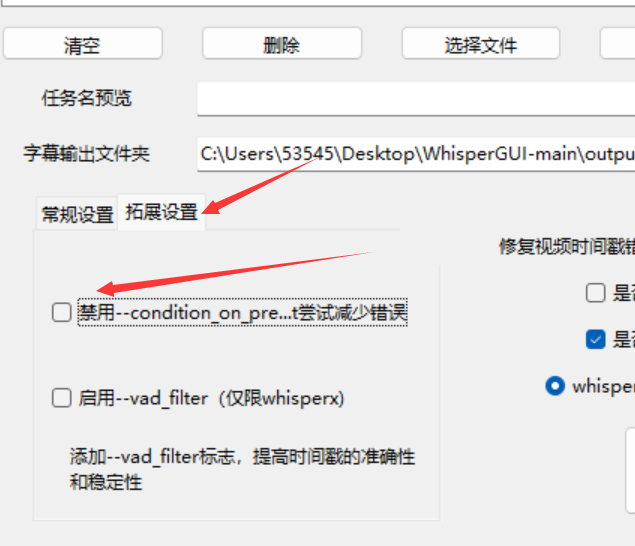
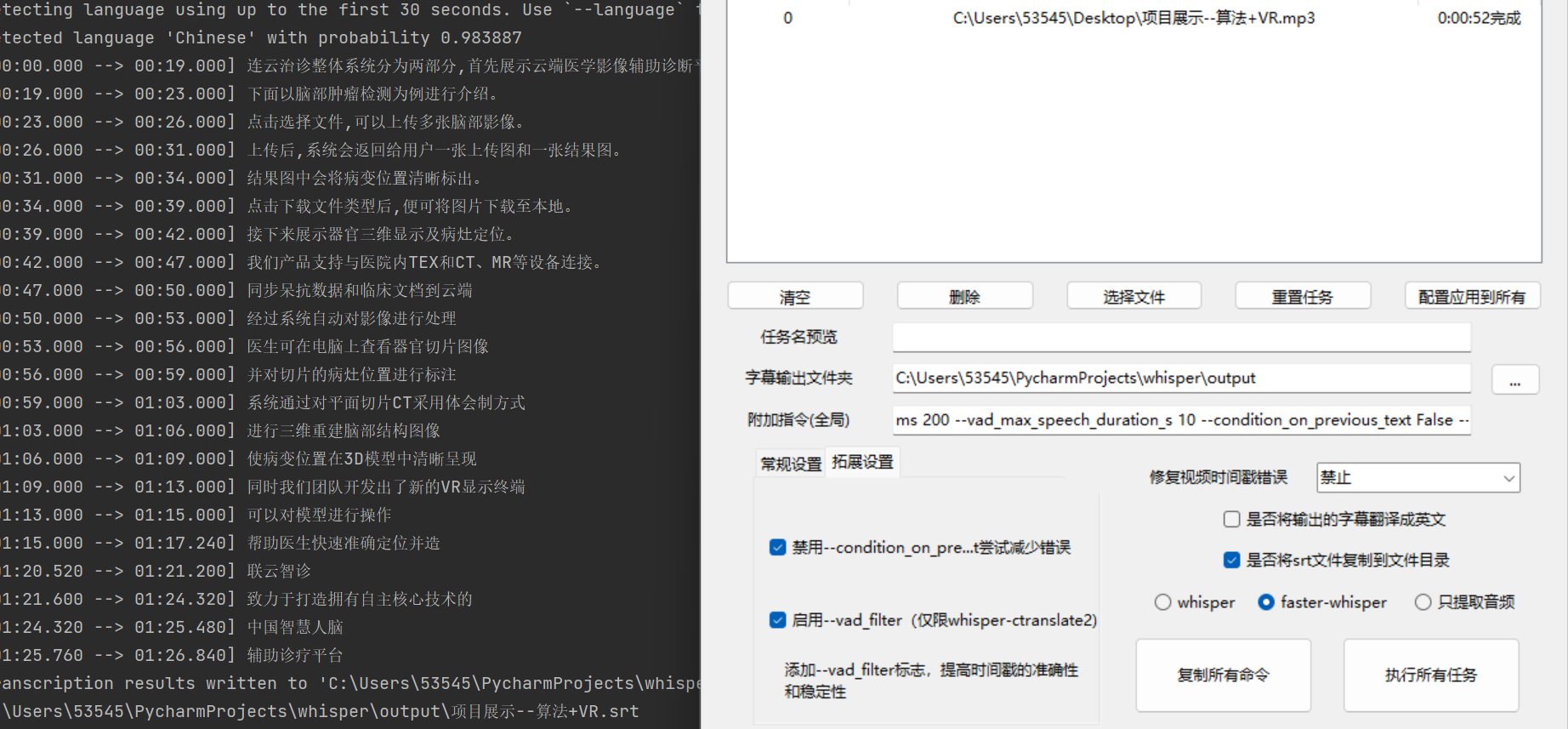
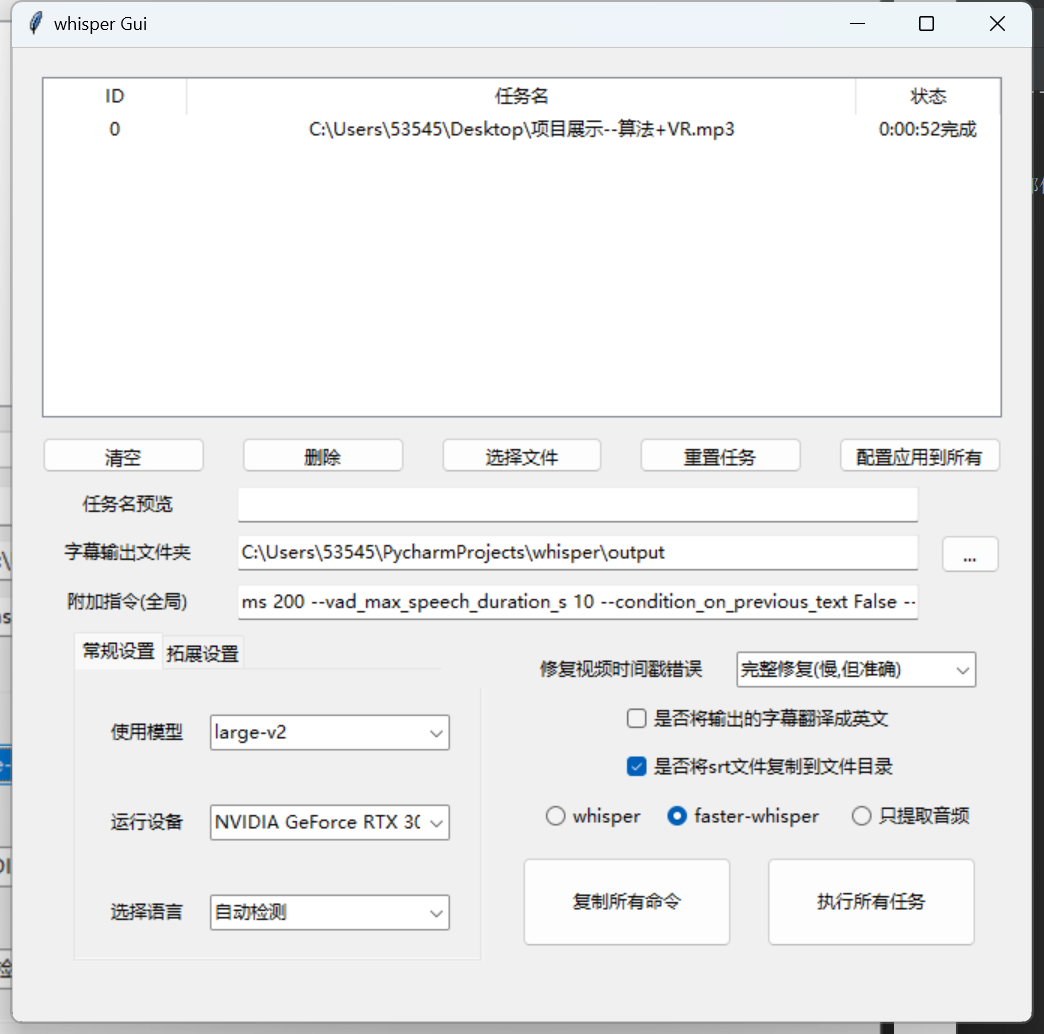
支持的操作如下
- 支持文件/文件夹拖入,或批量选择加载任务
- 显示每个任务的状态
- 可以对每一个文件任务单独设置不同的配置
- Gui界面支持自定义大小调整,自适应界面
- 对官方指令进行一定的修改,优化。改善长音频,语句重复的问题,识别错误的。
- 软件自带功能将视频转化为aac音频,并且转化过程中重建时间戳,提高转化成功率
- 可以选择指定的设备(CPU、显卡)
- 支持将生成的srt字幕文件,复制到同目录下,并编辑为相同的文件名
- 在支持whisper的前提下,增加支持faster-whisper,这个项目有更多的选项和拓展功能,详细请看相关目录。
- 支持任务完成时间统计
- 支持实时保存配置,开启软件自动读取上次配置
- 支持附加指令


需要自行安装Python 3,cuda,whisper/faster-whisper以及FFmpeg。
本工具只是提供方便操作的Gui界面,适合有一定基础的人使用。
fast-whisper是使用CTranslate2重新实现 OpenAI 的 Whisper 模型,CTranslate2 是 Transformer 模型的快速推理引擎。此实现速度比openai/whisper快 4 倍,并且使用更少的内存,但具有相同的精度。通过 CPU 和 GPU 上的 8 位量化,可以进一步提高效率。
Whisper-ctranslate2是一个基于faster-whisper的命令行客户端,与openai/whisper的原始客户端兼容。(Gui工具依赖这个项目去运行faster-whisper)
ffmpeg它还需要在您的系统上安装命令行工具,大多数包管理器都可以提供该工具:
# on Ubuntu or Debian
sudo apt update && sudo apt install ffmpeg
# on Arch Linux
sudo pacman -S ffmpeg
# on MacOS using Homebrew (https://brew.sh/)
brew install ffmpeg
# on Windows using Chocolatey (https://chocolatey.org/)
choco install ffmpeg
# on Windows using Scoop (https://scoop.sh/)
scoop install ffmpeg
GPU 执行需要在系统上安装 NVIDIA 库 cuBLAS 11.x 和 cuDNN 8.x。请参阅CTranslate2 文档。
python --version
ffmpeg -version
whisper-ctranslate2 --help
这样启动可以无窗口直接启动
有黑窗,但可以看到程序运行和输出

强烈推荐使用faster-whisper,比官方快好几个量级,而且要求的显存也会减少。之前我的3060(6G)只能跑medium模型,而且一般运行时间需要影片本身2倍左右的时间。
现在使用large-v2最大的模型,速度也只需要影片1/5的时间就可以的,准确性速度效率是之前的很多倍!
附加参数:
--vad_threshold 0.2 --vad_min_speech_duration_ms 200 --vad_min_silence_duration_ms 200 --vad_max_speech_duration_s 10 --condition_on_previous_text False --vad_filter False
在 Whisper(一个语音识别或自动语音识别(ASR)系统)或类似的工具中,你提到的这些命令行参数主要用于语音活动检测(VAD, Voice Activity Detection)和其他相关设置。下面是这些参数可能的含义:
- `--vad_threshold 0.2: VAD 阈值,通常是一个介于 0 到 1 之间的小数。这个参数用于确定什么样的声音应被认为是“活动”(通常是语音)和什么样的声音应该被忽略(通常是噪音或沉默)。0.1 是这个阈值,较低的值可能会捕获更多的噪音,而较高的值可能会忽略某些较安静的语音。
--vad_min_speech_duration_ms 200: 这是最短的语音活动持续时间(以毫秒为单位)。只有超过这个时长的声音才会被认为是有效的语音输入。--vad_min_silence_duration_ms 200: 这是最短的沉默持续时间(也是以毫秒为单位)。只有超过这个时长的沉默才会被认为是有效的沉默,通常用于分割不同的语音段。--vad_max_speech_duration_s 10: 这是单个语音段的最长持续时间(以秒为单位)。如果某个语音段超过这个时长,它可能会被截断或分割。--condition_on_previous_text False: 这个参数可能与模型的上下文有关。如果设置为True,ASR 模型可能会使用之前识别的文本来改善当前的语音识别准确性。False表示每个语音段都是独立处理的,不依赖于之前的文本。--vad_filter False: 如果设置为True,VAD 过滤器可能会用更复杂的算法(例如,使用机器学习模型)来确定何时开始和结束语音段,而不是仅仅使用基本的阈值和持续时间参数。
部分灵感来源于https://github.com/ADT109119/WhisperGUI
faster-whisper:https://github.com/guillaumekln/faster-whisper
whisper-ctranslate2:https://github.com/Softcatala/whisper-ctranslate2