本项目将加密流量分类里面常见方法做了统一的整理归纳,提供各个方法的执行入口。使用的时候只需要按照要求把自己的数据预处理一下,放在指定的一个目录然后再去运行相应的模型的入口main函数即可。本项目对科研人员做对比试验特别有帮助。现在我的一篇CCF-B类论文已中,于是把这个项目开源出来,分享给大家! 目前这个项目只集成了基于包长序列的相关模型,基于载荷的模型不在讨论之内!
https://github.com/jmhIcoding/traffic_classification_utils
目前本项目支持如下模型:
- FS-Net Liu, C., He, L., Xiong, G., Cao, Z., & Li, Z. (2019, April). Fs-net: A flow sequence network for encrypted traffic classification. In IEEE INFOCOM 2019-IEEE Conference On Computer Communications (pp. 1171-1179). IEEE.
- GraphDapp Shen, M., Zhang, J., Zhu, L., Xu, K., & Du, X. (2021). Accurate decentralized application identification via encrypted traffic analysis using graph neural networks. IEEE Transactions on Information Forensics and Security, 16, 2367-2380.
- Deep Fingerprinting Sirinam, P., Imani, M., Juarez, M., & Wright, M. (2018, October). Deep fingerprinting: Undermining website fingerprinting defenses with deep learning. In Proceedings of the 2018 ACM SIGSAC Conference on Computer and Communications Security (pp. 1928-1943).
- SDAE/LSTM/CNN Rimmer, V., Preuveneers, D., Juarez, M., Van Goethem, T., & Joosen, W. Automated Website Fingerprinting through Deep Learning.
- Beauty Schuster, R., Shmatikov, V., & Tromer, E. (2017). Beauty and the burst: Remote identification of encrypted video streams. In 26th USENIX Security Symposium (USENIX Security 17) (pp. 1357-1374).
一般经验来看,FS-Net在各个任务都是表现最好的。
- CUMUL Panchenko, A., Lanze, F., Pennekamp, J., Engel, T., Zinnen, A., Henze, M., & Wehrle, K. (2016, February). Website Fingerprinting at Internet Scale. In NDSS.
- AppScanner Taylor, V. F., Spolaor, R., Conti, M., & Martinovic, I. (2016, March). Appscanner: Automatic fingerprinting of smartphone apps from encrypted network traffic. In 2016 IEEE European Symposium on Security and Privacy (EuroS&P) (pp. 439-454). IEEE.
- BIND Al-Naami, K., Chandra, S., Mustafa, A., Khan, L., Lin, Z., Hamlen, K., & Thuraisingham, B. (2016, December). Adaptive encrypted traffic fingerprinting with bi-directional dependence. In Proceedings of the 32nd Annual Conference on Computer Security Applications (pp. 177-188).
- RDP Jiang, M., Gou, G., Shi, J., & Xiong, G. (2019, October). I know what you are doing with remote desktop. In 2019 IEEE 38th International Performance Computing and Communications Conference (IPCCC) (pp. 1-7). IEEE.
一般来说,不同任务下,CUMUL效果最好!
为了最大限度减少我们使用现有方法的工作量,对于一个新的加密流量分析任务,我们需要做两件事情:
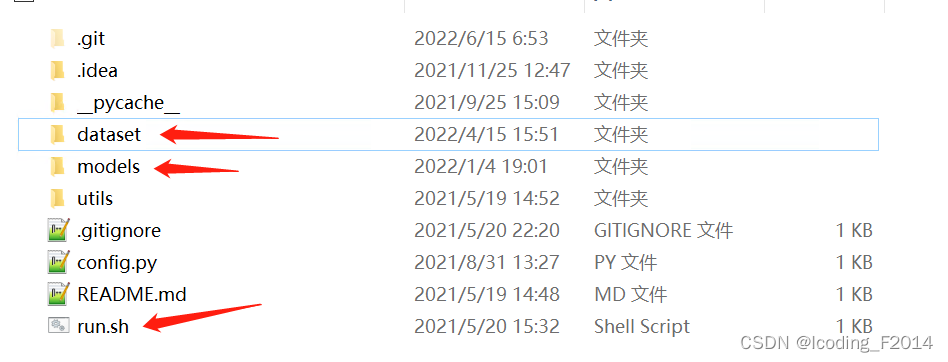
- 将你手上的数据集转换成一个统一的json格式的文件夹,也就是上面图里面显示得dataset目录,你们把自己的数据集转换后保存到这个目录即可。这个转换特别的简单,只要按照约定即可。手上不管是原始pcap文件流量,还是日志文件等等,都可以很方便加以转换。
- 跳转到相应的模型目录下就是上面图片里面models目录,修改xxx_main.py里面的数据集字段,使用run.sh去执行相应的xxx_main.py即可。
为什么需要把数据预先转换一下尼?为什么没有一键脚本。
答:因为每个人手上拿到的数据格式千奇百怪,有pcap的,有日志的,而且每个人自己的数据组织形式也有差异,因此我写不出来统一的数据转换脚本去统一所有人的情况。因此我把这个数据转换的任务交给使用者自己,因为只有数据持有者才最清楚自己的数据是什么形式的,我只是约定好转换后的目标格式。
为什么要使用run.sh脚本去执行xxx_main.py尼? 目前是需要使用run.sh的,里面有一些载入环境目录的过程。
为什么不使用统一的模型入口? 的确可以写个带parser的main入口,留待下一步吧。
因为本项目考虑的都是序列模型,因此只需要准备好数据流的包长序列、包方向序列等信息即可。
数据路径:dataset/{数据集名称}/{类别名}.json
dataset目录下,每个子目录都是一个任务的数据集,各个任务通过文件夹区分。比如目前有两个不同的数据集:app60,app320。

进入指定的数据集,每个类别的流量样本都统一放在一个相同的json文件内。因此这个目录下有m个不同的json,那么就会执行m分类,json的文件名也就是里面流量样本的ground-truth标签。
[
{//第一个样本
"packet_length": 包长序列,
"arrive_time_delta": 相邻数据包的到达时间间隔
},
{//第二个样本
"packet_length": 包长序列,
"arrive_time_delta": 相邻数据包的到达时间间隔
},
]主要的注意的有两点:
- json是一个大的list,list里面每个元素对应了一条网络流。如果list里面有n个元素,那么就表示这个类别下有n条流量样本。
- 每条流量都是一个dict, 里面有一个关键的字段:packet_length,包长序列。如果还需要使用BIND模型的话,arrive_time_delta字段也必不可少。其中包长序列是带正负号的,正负号表示数据包的方向。正号表示这个包是Client发给Server的,负号表示Sever发给Client的。之所以保留正负号是因为有的模型是需要这个信息的。
例子:下面的json包含了两个样本。
[
{
"packet_length": [
194,
-1424,
-32,
53,
86,
154,
-274,
-308,
38,
110,
-204
],
"arrive_time_delta": [
0,
0.0000030994415283203125,
0.00014519691467285156,
0.05950021743774414,
0.05950307846069336,
0.05950617790222168,
1.0571942329406738,
1.0572030544281006,
1.0572071075439453,
1.0572102069854736,
2.637423038482666
]
},
{
"packet_length": [
177,
-1424,
-1440,
-32,
-1448,
-99,
126,
852,
-258,
-317
],
"arrive_time_delta": [
0,
0.000030994415283203125,
0.0039768218994140625,
0.009712934494018555,
0.00972294807434082,
0.35946083068847656,
0.35947394371032715,
0.35948801040649414,
0.3595008850097656,
1.3806648254394531
]
}
]目前我把所有的模型都分别放在models目录下的不同文件夹内。 目录如下, 需要什么模型,cd到相应的目录下即可。
.
├─models
│ ├─dl
│ │ ├─awf_dataset_util
│ │ ├─beauty
│ │ ├─cnn
│ │ ├─df
│ │ ├─df_only_D
│ │ ├─fsnet
│ │ ├─graphDapp
│ │ ├─lstm
│ │ ├─sdae
│ │ ├─varcnn
│ ├─ml
│ │ ├─appscanner
│ │ ├─bind
│ │ ├─cumul
│ │ ├─rdp在每个模型的目录下,都有一个xxx_main_model.py的入口脚本,和一个data目录。例如appscanner模型下的目录结构:
appscanner
│ appscanner_main_model.py ###模型的入口
│ eval.py
│ feature_extractor.py
│ hyper_params.py
│ min_max.py
│ model.py
│ README
│ train.py
│ __init__.py
│ 【1】AppScanner.pdf
│
├─data ##训练好的历史模型
│ │ appscanner_app60_model
│ ├─appscanner_app60 ##已经划分好的训练集、测试集、验证集等
│ │ X_test.pkl
│ │ X_train.pkl
│ │ X_valid.pkl
│ │ y_test.pkl
│ │ y_train.pkl
│ │ y_valid.pkl
│ │appscanner_main_model.py是appscanner模型的入口,大家只需要修改里面的最后几行就可以:
if __name__ == '__main__':
appscanner = model('app60') ##指定任务所需的数据集名,项目的dataset目录需要有这个数据集目录。
#appscanner.parser_raw_data() ##重新解析dataset目录下的原始流量样本,重新转换为模型所需的特定数据格式。
appscanner.train() ###训练模型
appscanner.test() ###测试模型对于每个模型的class,在实例化的时候,需要指定所使用的数据集是什么。在初始化的时候,系统会自动检测历史是否处理过这个数据集(主要是去查看data目录下是否有相应的测试集、训练集和模型文件存在),如果没有处理过会把原始数据做一步格式转换,划分测试集、训练集。
这个过程是通过调用parser_raw_data()完成的!parser_raw_data() 一执行就会重新打乱数据,一般用于交叉验证的时候!
然后使用run.sh脚本执行这个appscanner_main_model.py就可以了,run.sh在整个项目的根。
./../../../run.sh appscanner_main_model.py