Replica of results from the paper that introduces Posterior Sampling for Reinforcement Learning (PSRL) algorithm.
Osband, I., Russo, D., & Van Roy, B. (2013). (More) efficient reinforcement learning via posterior sampling. Advances in Neural Information Processing Systems, 26.
The current codebase supports the following RL environemnts:
- Random MDP
- RiverSwim
- TwoRoom gridworld
- FourRoom gridworld

- Create conda environment
cd psrl/
conda create --name psrl python=3.9
conda activate psrl- Install requirements
pip install -r requirements.txt
pip install -e .To replicate all plots first run the optimization process for each agent and environment
python scripts/generate_data.py --config configs/riverswim_psrl.yaml --seed 0This script will produce files agent.pkl and trajectories.pkl which store
the trained parameters of the optimized agent and the trajectories taken in the
environment throughout the execution of the program. Choose between any of the
configuration files in config folder to generate data specific for each
experiment.
The most straightforward way to obtain all data necessary for plots is to just run the following script
. run_parallel.shwhich launches all combinations of environments (riverswim, tworoom, fourroom),
agents (psrl, ucrl, kl_ucrl), and seeds (10 in total, starting at 0) using
screen.
After all runs come to an end, you can obtain regret plots by running
python scripts/plot_regret.py --config configs/regret_riverswim.yamlSwitch between the following configs to obtain a regret plot for each environment:
- configs/regret_riverswim.yaml
- configs/regret_tworoom.yaml
- configs/regret_fourroom.yaml
With configs/regret_riverswim.yaml you should expect the following plot

Likewise, with a single run you can obtain agent-specific plots for gridworld environments by running
python scripts/plot_agent.py --config configs/tworoom_klucrl.yamlChoose the right configuration to obtain a set of plots for any particular run. You should obtain all the following plots:
- Action-value function
- Empirical state visitation
- Empirical total reward
- Expected reward
- Policy
- State-value function
For configs/tworoom_klucrl.yaml (after setting no_goal=False)
you should expect the following
- Action-value function
- Empirical state visitations
- Empirical total reward
- Expected reward
- Policy
- State-value function







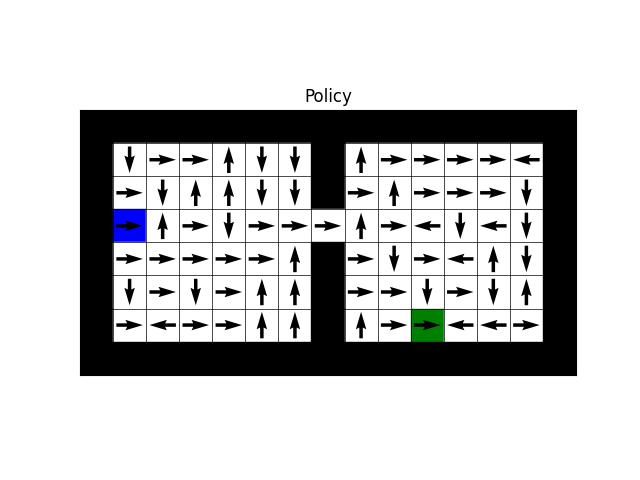
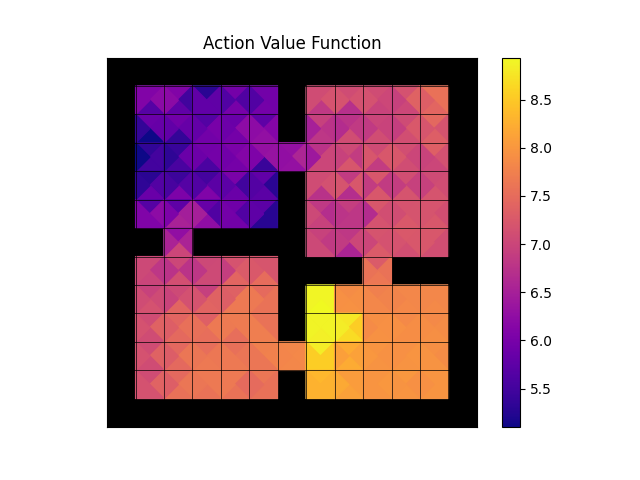
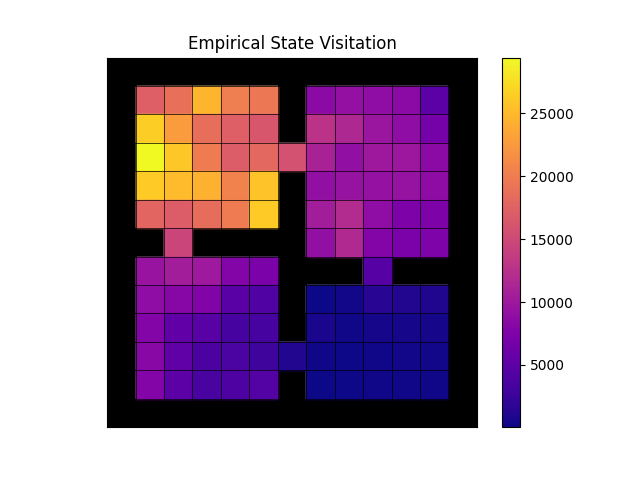
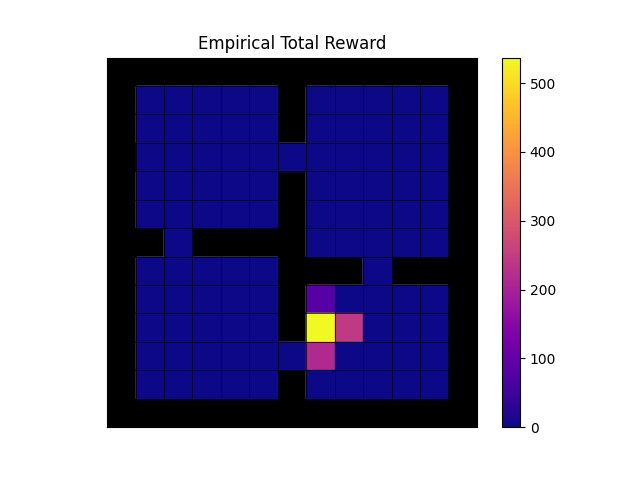
For configs/fourroom_klucrl.yaml (after setting no_goal=False)
you should expect the following
- Action-value function
- Empirical state visitations
- Empirical total reward
- Expected reward
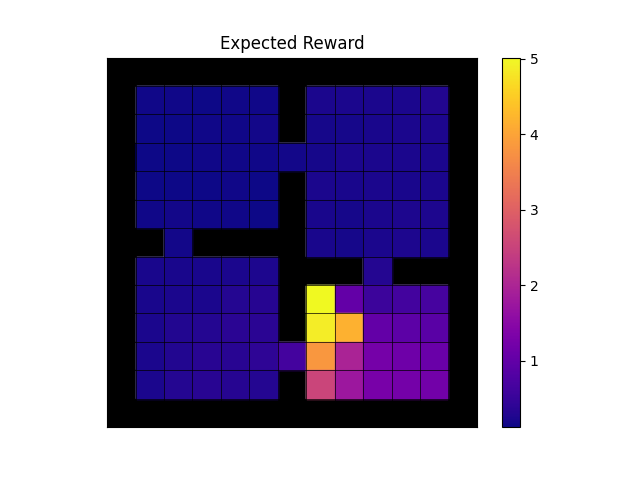
- Policy

- State-value function
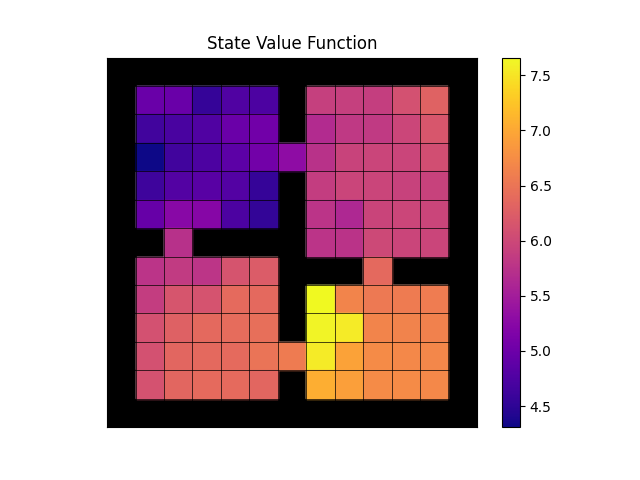






This project includes multiple other scripts that are undocumented. These were meant for a research project that was left unfinished, so they do not directly connect to the original paper. Likewise, there is no guarantee that results obtained from them produce any meaningful output yet.