欢迎加入AIGC技术交流群,与AI领域专家和各行各业的AIGC爱好者一起交流技术理论与行业信息!不管你是学术界还是工业界实践者或爱好者,都欢迎加入!
| 交流群二维码 | 拉你入群(备注AIGC-github) |
|---|---|
 |
 |
| Model_A | Model_B | Blog |
|---|---|---|
| 360智脑 | 讯飞星火 | 对比效果 |
| 阿里通义千问 | 讯飞星火 | 对比效果 |
| Bard | Bing_VS_ChatGPT | 对比效果 |
| baichuan-53B | ChatGLM-6B | 对比效果 |
| 文心一言 | Bard | 对比效果 |
| 文心一言 | Baize-7B | 对比效果 |
| 文心一言 | OpenAssistant | 对比效果 |
| 文心一言 | ChatGLM-6B | 对比效果 |
| 文心一言 | GPT-4 | 对比效果 |
| 文心一言 | GPT-4实测 | 对比效果 |
| 文心一言 | 讯飞星火 | 对比效果 |
| GPT4 | ChatGPT | 对比效果 |
| GPT4 | Claude2 | 对比效果1,对比效果2 |
这里整理了主流大模型baichuan、ChatGLM和LLaMA及其扩展模型的一些细节,并且会对目前主流的LLM按照功能和应用领域进行分类整理,更多请参考【Model List】。
dair-ai同样也整理了很多关于LLM和经典论文,感兴趣的读者可以参考:【ML Papers Explained】
这里整理了LLM预训练、微调使用的部分数据集,更多请参考【DataSet】
随着ChatGPT的发布,标志着大模型时代已来临,然而通用领域的大模型在企业垂直领域中未必会表现的好,因此会对通用领域大模型进行微调来适配垂直领域知识。
大模型的微调技术,从不同的方面,有不同的分类:
从参数规模来说,可以简单分为全参数微调和高效参数微调。前者一般是用预训练模型作为初始化权重,在特定数据集上继续训练,全部参数都更新的方法。而后者则是期望用更少的资源完成模型参数的更新,包括只更新一部分参数或者说通过对参数进行某种结构化约束,例如稀疏化或低秩近似来降低微调的参数数量。
如果按照在模型哪个阶段使用微调,或者根据模型微调的目标来区分,也可以从提示微调、指令微调、有监督微调的方式来。 高效微调技术可以粗略分为以下三大类:
- 增加额外参数(Addition-Based)
- 选取一部分参数更新(Selection-Based)
- 引入重参数化(Reparametrization-Based)
而在增加额外参数这类方法中,又主要分为类适配器(Adapter-like)方法和软提示(Soft prompts)两个小类。 增加额外参数 Addition-Based,如:Prefix Tuning、Prompt Tuning、Adapter Tuning及其变体 选取一部分参数更新 Selection-Based,如:BitFit 引入重参数化 Reparametrization-Based,如:LoRA、AdaLoRA、QLoRA 混合高效微调,如:MAM Adapter、UniPELT
下图是目前主流PEFT技术的总结:
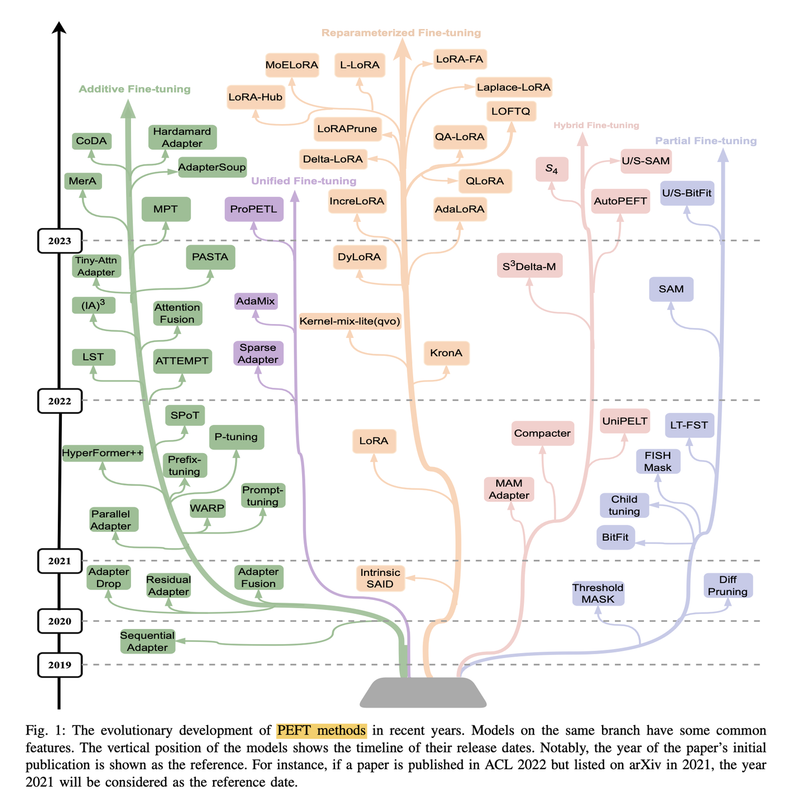
PEFT仓库是一个用于微调大模型的工具库,提供了多种高效微调技术的实现。
下面按照LoRA及其扩展模型和其他微调方法分别进行总结:
| Peft | Description | Paper | Code | Blog |
|---|---|---|---|---|
| LoRA | 1)Transformer的权重矩阵包括Attention模块里用于计算query, key, value的Wq,Wk,Wv以及多头attention的Wo,以及MLP层的权重矩阵,LoRA只应用于Attention模块中的4种权重矩阵,而且通过消融实验发现同时调整 Wq 和 Wv 会产生最佳结果。2)实验还发现,保证权重矩阵的种类的数量比起增加隐藏层维度r更为重要,增加r并不一定能覆盖更加有意义的子空间。3)关于秩的选择,通常情况下,rank为4,8,16即可。4)实验也发现,在众多数据集上LoRA在只训练极少量参数的前提下,最终在性能上能和全量微调匹配,甚至在某些任务上优于全量微调。 | LoRA: Low-Rank Adaptation of Large Language Models | LoRA Code | |
| AdaLoRA | AdaLoRA是对LoRA的一种改进,它根据重要性评分动态分配参数预算给权重矩阵。具体做法如下:1)调整增量矩分配。AdaLoRA将关键的增量矩阵分配高秩以捕捉更精细和任务特定的信息,而将较不重要的矩阵的秩降低,以防止过拟合并节省计算预算。2)以奇异值分解的形式对增量更新进行参数化,并根据重要性指标裁剪掉不重要的奇异值,同时保留奇异向量。由于对一个大矩阵进行精确SVD分解的计算消耗非常大,这种方法通过减少它们的参数预算来加速计算,同时,保留未来恢复的可能性并稳定训练。3)在训练损失中添加了额外的惩罚项,以规范奇异矩阵P和Q的正交性,从而避免SVD的大量计算并稳定训练。 | AdaLoRA: Adaptive Budget Allocation for Parameter-Efficient Fine-Tuning | AdaLoRA Code | |
| QLoRA | QLoRA使用一种新颖的高精度技术将预训练模型量化为 4 bit,然后添加一小组可学习的低秩适配器权重,这些权重通过量化权重的反向传播梯度进行微调。QLORA 有一种低精度存储数据类型(4 bit),还有一种计算数据类型(BFloat16)。实际上,这意味着无论何时使用 QLoRA 权重张量,我们都会将张量反量化为 BFloat16,然后执行 16 位矩阵乘法。QLoRA提出了两种技术实现高保真 4 bit微调——4 bit NormalFloat(NF4) 量化和双量化。此外,还引入了分页优化器,以防止梯度检查点期间的内存峰值,从而导致内存不足的错误,这些错误在过去使得大型模型难以在单台机器上进行微调。 | QLoRA: Efficient Finetuning of Quantized LLMs | QLoRA Code | |
| DoRA | DoRA(Weight-Decomposed Low-Rank Adaptation:权重分解低阶适应)是由NVIDIA最新提出的一种新的参数高效的微调(PEFT)方法。DoRA旨在通过分解预训练权重为幅度(magnitude)和方向(direction)两个组成部分然后分别微调,来提高微调的学习能力和训练稳定性,同时避免额外的推理开销,它特别适用于与LoRA(Low-Rank Adaptation)结合使用。 | DoRA: Weight-Decomposed Low-Rank Adaptation | DoRA Code | |
| PiSSA方法 | 仅修改Lora初始化方式显著提高模型微调效果 | PiSSA: Principal Singular Values and Singular Vectors Adaptation of Large Language Models | PiSSA Code | PiSSA Blog |
| MOELora | MOELoRA 的核心**是将 MOE 和 LoRA 结合起来,以实现多任务学习和参数高效微调。MOELoRA 由两个主要组件组成:MOE 和 LoRA。MOE 用于多任务学习,LoRA 用于参数高效微调。MOELoRA 通过 MOE 的多任务学习能力,有效地利用了有限的数据和计算资源,同时通过 LoRA 的参数高效微调能力,有效地提高了多任务医学应用的性能。 | MOELoRA: An MOE-based Parameter Efficient Fine-Tuning Method for Multi-task Medical Applications | MOELora Code |
| Peft | Description | Paper | Code | Blog |
|---|---|---|---|---|
| Instruction Tuning | 指令微调可以被视为有监督微调(Supervised Fine-Tuning,SFT)的一种特殊形式。但是,它们的目标依然有差别。SFT是一种使用标记数据对预训练模型进行微调的过程,以便模型能够更好地执行特定任务。而指令微调是一种通过在包括(指令,输出)对的数据集上进一步训练大型语言模型(LLMs)的过程,以增强LLMs的能力和可控性。 | nstruction Tuning for Large Language Models: A Survey | Instruction Tuning Code | |
| BitFit | BitFit是一种稀疏的微调方法,它训练时只更新bias的参数或者部分bias参数 | BitFit: Simple Parameter-efficient Fine-tuning for Transformer-based Masked Language-models | BitFit Code | |
| Prefix Tuning | Prefix Tuning提出固定预训练LM,为LM添加可训练,任务特定的前缀,这样就可以为不同任务保存不同的前缀,微调成本也小;同时,这种Prefix实际就是连续可微的Virtual Token(Soft Prompt/Continuous Prompt),相比离散的Token,更好优化,效果更好。 | Prefix-Tuning: Optimizing Continuous Prompts for Generation | Prefix Tuning Code | |
| Prompt Tuning | Prompt Tuning,该方法可以看作是Prefix Tuning的简化版本,它给每个任务定义了自己的Prompt,然后拼接到数据上作为输入,但只在输入层加入prompt tokens,并且不需要加入 MLP 进行调整来解决难训练的问题。 | The Power of Scale for Parameter-Efficient Prompt Tuning | Prompt Tuning Code | |
| P-Tuning | P-Tuning,设计了一种连续可微的virtual token(同Prefix-Tuning类似)。将Prompt转换为可以学习的Embedding层,并用MLP+LSTM的方式来对Prompt Embedding进行一层处理。借助P-tuning,GPT在SuperGLUE上的成绩首次超过了同等级别的BERT模型,这颠覆了一直以来“GPT不擅长NLU”的结论,也是该论文命名的缘由。 | GPT Understands, Too | P-Tuning Code | |
| P-Tuning V2 | P-Tuning 的问题是在小参数量模型上表现差。 相比 Prompt Tuning 和 P-tuning 的方法, P-tuning v2 方法在每一层加入了 Prompts tokens 作为输入。与P-Tuning相比,做了如下改变:1)移除重参数化的编码器;2)针对不同任务采用不同的提示长度;3)引入多任务学习;4)回归传统的分类标签范式,而不是映射器 | P-Tuning v2: Prompt Tuning Can Be Comparable to Fine-tuning Universally Across Scales and Tasks | P-Tuning-V2 Code | |
| Adapter Tuning | Adapter 在预训练模型每层中插入用于下游任务的参数(针对每个下游任务,仅增加3.6%的参数),在微调时将模型主体冻结,仅训练特定于任务的参数,从而减少了训练时的算力开销。Adapter Tuning 设计了Adapter结构,并将其嵌入Transformer的结构里面,针对每一个Transformer层,增加了两个Adapter结构,分别是多头注意力的投影之后和第二个feed-forward层之后。在训练时,固定住原来预训练模型的参数不变,只对新增的 Adapter 结构和 Layer Norm 层进行微调,从而保证了训练的高效性。 | Parameter-Efficient Transfer Learning for NLP | Adapter Tuning Code | |
| AdapterFusion | Adapter Fusion,一种融合多任务信息的Adapter的变体,在 Adapter 的基础上进行优化,通过将学习过程分为两阶段来提升下游任务表现。1)知识提取阶段:在不同任务下引入各自的Adapter模块,用于学习特定任务的信息。2)知识组合阶段:将预训练模型参数与特定任务的Adapter参数固定,引入新参数(AdapterFusion)来学习组合多个Adapter中的知识,以提高模型在目标任务中的表现。 | AdapterFusion: Non-Destructive Task Composition for Transfer Learning | ||
| AdapterDrop | 作者通过对Adapter的计算效率进行分析,发现与全量微调相比,Adapter在训练时快60%,但是在推理时慢4%-6%。基于此,作者提出了AdapterDrop方法缓解该问题。AdapterDrop 在不影响任务性能的情况下,对Adapter动态高效的移除,尽可能的减少模型的参数量,提高模型在反向传播(训练)和正向传播(推理)时的效率。 | AdapterDrop: On the Efficiency of Adapters in Transformers | ||
| MAM Adapter | MAM Adapter,一个在Adapter、Prefix Tuning和LoRA之间建立联系的统一方法。模型 MAM Adapter 是用 FFN 层的并行Adapter和软提示的组合。 | Towards a Unified View of Parameter-Efficient Transfer Learning | MAM Adapter Code | |
| UniPELT | UniPELT方法将不同的PELT方法作为子模块,并通过门控机制学习激活最适合当前数据或任务的方法。 | UniPELT: A Unified Framework for Parameter-Efficient Language Model Tuning | UniPELT Code |
这里整理关于LLM微调的脚本以及开源工具或者平台的使用案例,更多请参考【Fine Tune】
| Description | Paper | Code | Blog |
|---|---|---|---|
| BentoML | BentoML Code | ||
| CLIP-API-service | |||
| CTranslate2 | |||
| DeepSpeed-MII | |||
| FastLLM | |||
| Huggingface | |||
| JittorLLM | |||
| LightLLM | |||
| LMDeploy | |||
| MLC LLM | |||
| OneDiffusion | |||
| OpenLLM | |||
| Ray Serve |
【LLM大语言模型之Generate/Inference(生成/推理)中参数与解码策略原理及其代码实现】【blog】
| Description | Paper | Code | Blog |
|---|---|---|---|
| ColossalAI | ColossalAI Code | ||
| DeepSpeed | |||
| Megatron-LM |
RAG实战与理论相关资料,更多请参考【LangChain】
RAG实战主要分为LangChain框架实现和LlamaIndex框架实现,分别可以参考LangChain_RAG和LlamaIndex_RAG
| VectorDB | Paper | Code | Blog |
|---|---|---|---|
| Chroma | |||
| DingoDB | dingo,dingo-store | DingoDB官网 | |
| LanceDB | |||
| Milvus | |||
| Pinecone | |||
| QDrant | |||
| Weaviate | |||
| Zilliz |
| RAG_OpenSoure_Tool | Code | Blog |
|---|---|---|
| AnythingLLM | AnythingLLM Code | AnythingLLM官网 |
| QAnything | QAnything Code |
| Model | Description | Code | Paper/Blog |
|---|---|---|---|
| Agents | Agent Code | Agents: An Open-source Framework for Autonomous Language Agents,Agent 官网,blog | |
| AgentGPT | AgentGPT Code | AgentGPT Chat,AgentGPT docs | |
| AgentVerse | |||
| AI Legion | AI Legion Chat | ||
| AutoGen | 微软在向 OpenAI 注资 130 亿美元并使 Bing 变得更智能后,现在成为人工智能领域的主要参与者。其 AutoGen 是一个用于开发和部署多个代理的开源框架,这些代理可以共同工作以自主实现目标。AutoGen 试图促进和简化代理之间的通信,减少错误,并最大化 LLMs 的性能。它还具有广泛的定制功能,允许您选择首选模型,通过人类反馈改进输出,并利用额外的工具。 | AutoGen blog | |
| AutoGPT | 创始人托兰·布鲁斯·理查兹开发,AutoGPT 是早期代理之一,于 2023 年 3 月发布,是根据中岛的论文开发的。它也是今天在 GitHub 上最受欢迎的代理存储库。 AutoGPT 的理念很简单 - 它是一个完整的工具包,用于构建和运行各种项目的定制 AI 代理。该工具使用 OpenAI 的 GPT-4 和 GPT-3.5 大型语言模型(LLM),并允许您为各种个人和商业项目构建代理。 | AutoGPT Code | AutoGPT docs ,AutoGPT blog |
| BabyAGI | BabyAGI 是中山的任务驱动自主代理的简化版本。这个 Python 脚本只有 140 个代码字,并且根据官方 GitHub 仓库,“使用 OpenAI 和矢量数据库,如 Chroma 或 Weaviate,来创建、优先处理和执行任务”。 | BabyAGI Code | BabyAGI docs |
| Camel | 该框架利用 LLM 的力量动态分配角色给代理人,指定和开发复杂任务,并安排角色扮演场景,以促进代理人之间的协作。这就像是为人工智能设计的戏剧。 | CAMEL Code | CAMEL Chat,CAMEL docs |
| ChatDev | CoPilot、Bard、ChatGPT 等等都是强大的编码助手。但是像 ChatDev 这样的项目可能很快就会让它们望尘莫及。ChatDev 被打造成“一个虚拟软件公司”,它不仅使用一个,而是多个代理人来扮演传统开发组织中的不同角色。 代理人 - 每个都被分配了一个独特的角色 - 可以合作处理各种任务,从设计软件到编写代码和文档。雄心勃勃?当然。ChatDev 仍然更多地是一个代理人互动的测试平台,但如果你自己是开发人员,它是值得一看的。 | ChatDev Code | |
| crewAI | crewAI Code | crewAI Blog | |
| CogAgent | |||
| Do Anything Machine | Do Anything Machine Chat | ||
| Generative Agents | GPTRPG Code | Generative Agents: Interactive Simulacra of Human Behavior | |
| Gentopia | |||
| Godmode | Godmode Chat | ||
| GPT-Engineer | GPT-Engineer Code | ||
| HuggingGPT | HuggingGPT Code | HuggingGPT Chat | |
| JARVIS | JARVIS 远不及托尼·斯塔克标志性的人工智能助手(还有同样标志性的保罗·贝坦尼的声音),但它有一些小技巧。以 ChatGPT 作为其“决策引擎”,JARVIS 处理任务规划、模型选择、任务执行和内容生成。拥有对 HuggingFace 平台上数十种专门模型的访问权限,JARVIS 利用 ChatGPT 的推理能力来应用最佳模型到给定的任务上。这使得它对各种任务具有相当迷人的灵活性,从简单的摘要到目标检测都能胜任。 | JARVIS Code | --- |
| LoopGPT | LoopGPT 是 Toran Bruce Richards 的 AutoGPT 的一个迭代版本。除了一个合适的 Python 实现,该框架还带来了对 GPT-3.5 的改进支持,集成和自定义代理能力。它还消耗更少的 API 令牌,因此运行成本更低。LoopGPT 可以基本上自主运行,或者与人类一起运行,以最小化模型的幻觉。有趣的是,该框架不需要访问向量数据库或外部存储来保存数据。它可以将代理状态写入文件或 Python 项目。 | LoopGPT Code | |
| MetaGPT | MetaGPT 是另一个开源 AI 代理框架,试图模仿传统软件公司的结构。与 ChatDev 类似,代理被分配为产品经理、项目经理和工程师的角色,并协作完成用户定义的编码任务。到目前为止,MetaGPT 只能处理中等难度的任务 - 比如编写贪吃蛇游戏或构建简单的实用应用程序 - 但它是一个有前途的工具,可能在未来迅速发展。使用 OpenAI API 费用,生成一个完整的项目大约需要 2 美元。 | MetaGPT Code | |
| NexusGPT | NexusGPT Chat | ||
| OpenAGI | OpenAGI 是一个开源的 AGI(人工通用智能)研究平台,结合了小型专家模型 - 专门针对情感分析或图像去模糊等任务的模型 - 以及来自任务反馈的强化学习(RLTF)来改进它们的输出。 在幕后,OpenAGI 与其他自主开源 AI 框架并没有太大的不同。它汇集了像 ChatGPT、LLMs(如 LLaMa2)和其他专业模型等流行平台,并根据任务的上下文动态选择合适的工具。 | OpenAGI Code | |
| RecurrentGPT | |||
| RestGPT | RestGPT Code | RestGPT blog,RestGPT: Connecting Large Language Models with Real-World RESTful APIs | |
| RoboGen | RoboGen Code | 项目主页,blog,RoboGen: Towards Unleashing Infinite Data for Automated Robot Learning via Generative Simulation | |
| ShortGPT | AI 模型在生成内容方面表现出色。但直到最近,视频格式一直受到较少关注。ShortGPT 是一个框架,它允许您使用大型语言模型来简化诸如视频创作、语音合成和编辑等复杂任务。 ShortGPT 可以处理大多数典型的与视频相关的任务,如撰写视频脚本,生成配音,选择背景音乐,撰写标题和描述,甚至编辑视频。该工具适用于短视频和长视频内容,无论平台如何。 | ShortGPT Code | |
| SuperAGI | SuperAGI 是 AutoGPT 的更灵活、用户友好的替代品。把它想象成一个开源 AI 代理的发射台,它包含了构建、维护和运行自己代理所需的一切。这还包括插件和一个云版本,您可以在其中测试各种功能。该框架具有多个人工智能模型,图形用户界面,与向量数据库的集成(用于存储/检索数据),以及性能洞察。还有一个市场,其中有工具包,可以让您将其连接到流行的应用程序和服务,如 Google Analytics。 | SuperAGI Code | |
| Toolformer | Toolformer blog,Toolformer: Language Models Can Teach Themselves to Use Tools | ||
| XAgent | XAgent Code | XAgent官网,XAgent Blog | |
| Xlang |
整理关于LangChain的相关笔记和课程,更多请参考【LangChain】
整理关于LlamaIndex的相关笔记和课程,更多请参考【LlamaIndex】
整理关于TaskingAI的相关笔记和课程,更多请参考【TaskingAI】
更多请参考【Prompt Engineering】
| Description | Paper | Code | Blog |
|---|---|---|---|
| 复现RLHF:通过开源项目 trl 搭建一个通过强化学习算法(PPO)来更新语言模型(GPT-2) | code | blog | |
| 详解大模型RLHF过程(配代码解读) | blog | ||
| 想训练ChatGPT?得先弄明白Reward Model怎么训(附源码) | blog | ||
| 直接偏好优化算法(Direct Preference Optimization,DPO) | Direct Preference Optimization: Your Language Model is Secretly a Reward Model | DPO Code | DPO Code |
【LLM大模型之基于SentencePiece扩充LLaMa中文词表实践】【blog】
| Description | Paper | Code | Blog |
|---|---|---|---|
| Transformer升级之路:一种全局长度外推的新思路 | blog | ||
| ChatGPT能写长篇小说了,ETH提出RecurrentGPT实现交互式超长文本生成 | paper | code | blog,demo1,demo2 |
| 语言大模型100K上下文窗口的秘诀 | blog | ||
| RoPE可能是LLM时代的Resnet | blog | ||
| 图解RoPE旋转位置编码及其特性 | blog | ||
| 详解基于调整RoPE旋转角度的大模型长度外推方法 | blog | ||
| 无需微调的自扩展大模型上下文窗口 | LLM Maybe LongLM: Self-Extend LLM Context Window Without Tuning | --- | --- |
| 大模型长文本评估方案CLongEval | CLongEval: A Chinese Benchmark for Evaluating Long-Context Large Language Models | CLongEval Code | CLongEval Blog |
解决幻觉常用的两种方法:1)不断增加模型的数据规模、提升数据质量;2)通过调用搜索等外部工具让模型能够获取实时信息。
| Description | Paper | Code | Blog |
|---|---|---|---|
| 腾讯AILab等《大型语言模型中的幻觉》,全面阐述检测、解释和减轻幻觉 | Siren's Song in the AI Ocean: A Survey on Hallucination in Large Language Models | code | blog |
| LLM幻觉的解决方案及其应用 | Cognitive Mirage: A Review of Hallucinations in Large Language Models | code | blog |
| Description | Paper | Code | Blog |
|---|---|---|---|
| 微软提出Control-GPT:用GPT-4实现可控文本到图像生成! | paper | blog | |
| AIGC如何安全可控?中山大学等最新《AIGC中对隐私和安全的挑战及其补救措施:探索隐私计算、区块链潜在应用》全面阐述 | paper | blog | |
| ControlVideo: 可控的Training-free的文本生成视频 | paper | code | blog |
| 大模型切脑后变身PoisonGPT,虚假信息案例 | code | blog | |
| ChatGPT羊驼家族全沦陷!CMU博士击破LLM护栏,人类毁灭计划脱口而出 | paper | code | blog |
| Description | Paper | Code | Blog |
|---|---|---|---|
| 美国麻省大学&谷歌研究院:改写文本可以避开AI生成文本的检测器,但检索则是一种有效的防御 | paper | code | |
| 人工智能生成的文本能被可靠地检测出来吗? | paper | blog | |
| DetectGPT(斯坦福大学):利用概率曲率检测文本是否大模型生成 | paper | code&data | blog |
| Detecting LLM-Generated-Text综述 | paper | blog | |
| 一个专为教育者打造的全新 AI 检测模型 | blog | ||
| OpenAI重磅发布官方「ChatGPT检测器」 | blog | ||
| 斯坦福最新研究:不要过度依赖GPT生成内容,其检测器可能存在不利于非母语英语写作者的偏见 | paper | ||
| TUM发布最新《检测ChatGPT生成文本现状》综述 | paper |
【👬🏻】欢迎Star ⭐️⭐️⭐️⭐️⭐️ && 提交 Pull requests 👏🏻👏🏻👏🏻
个人主页:wshzd.github.io
微信公众号:

以上部分资料来自网络整理,供大家学习参考,如有侵权,麻烦联系我删除!
WeChat:h18821656387