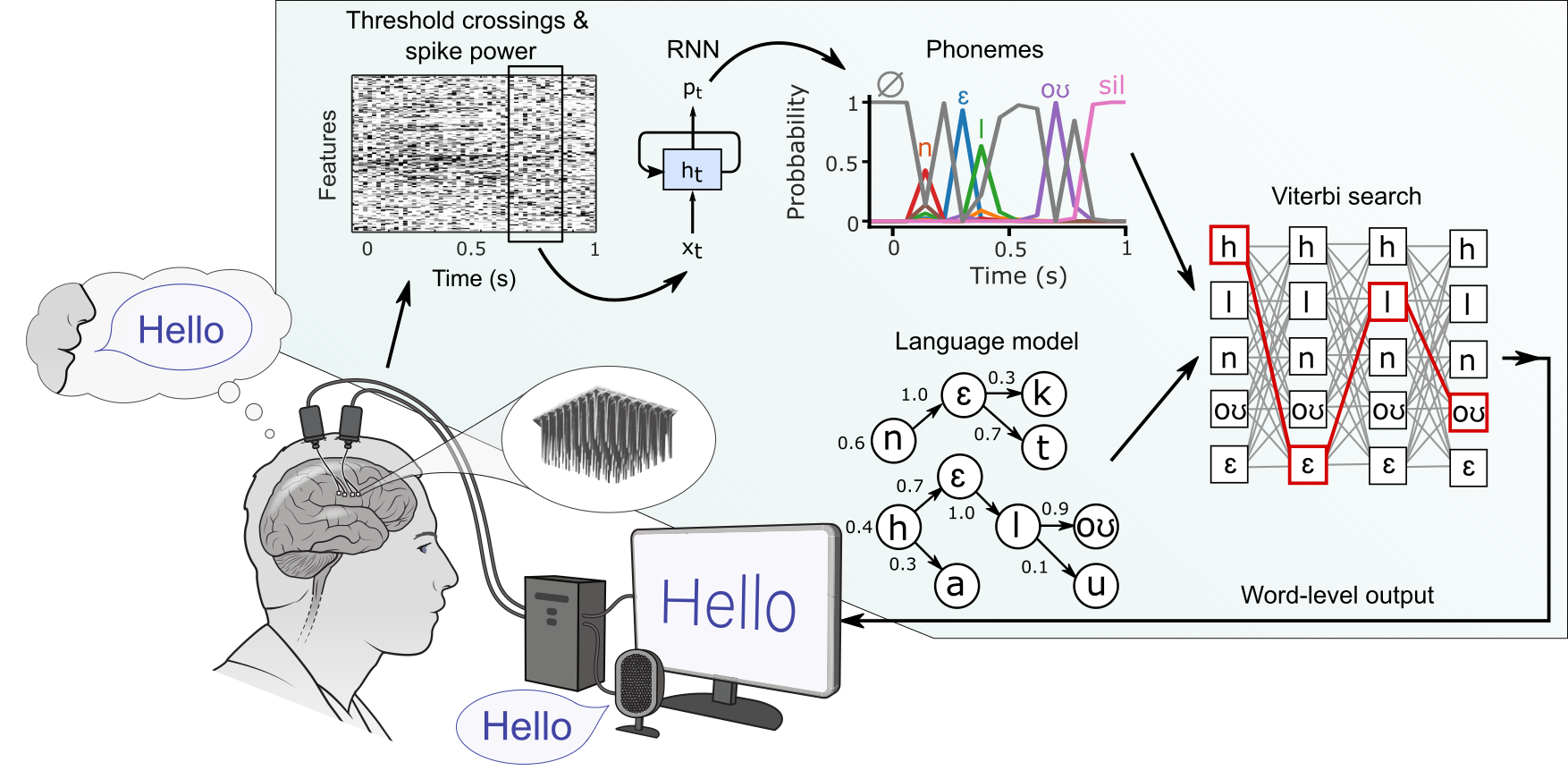
This repo is associated with this paper, dataset and machine learning competition. The code contains the RNN decoder (NeuralDecoder) and language model decoder (LanguageModelDecoder) used in the paper, and can be used to reproduce the core offline decoding results.
The jupyter notebooks in AnalysisExamples show how to prepare the data for decoder training, train the RNN decoder, and evaluate it using the language model. Intermediate results from these steps (.tfrecord files for training, RNN weights from my original run of this code) as well as the 3-gram and 5-gram language models we used are available here (in the languageModel.tar.gz, languageModel_5gram.tar.gz, and derived.tar.gz files).
Example neural tuning analyses (e.g., classification, PSTHs) are also included in the AnalysisExamples folder (classificationWindowSlide.ipynb, examplePSTH.ipynb,naiveBayesClassification.ipynb, tuningHeatmaps.ipynb, exampleSaliencyMaps.ipynb).
We have posted a new PyTorch implementation of this original TensorFlow RNN decoder here.
We have partitioned the data into a "train", "test" and "competitionHoldOut" partition (the partitioned data can be downloaded here as competitionData.tar.gz and has been formatted for machine learning). "test" contains the last block of each day (40 sentences), "competitionHoldOut" contains the first two (80 sentences), and "train" contains the rest.
The transcriptions for the "competitionHoldOut" partition are redacted. See baselineCompetitionSubmission.txt for an example submission file for the competition (which is generated by this notebook).
When trained on the "train" partition and evaluated on the "test" partition, our original run of the code achieved an 18.8% word error rate (RNN + 3-gram baseline) and a 13.7% word error rate (RNN + 5-gram + OPT baseline). For results on the "competitionHoldOut" partition, see the baseline word error rates here.
NeuralDecoder should be installed as a python package (pip install -e .) using Python 3.9. LanguageModelDecoder needs to be compiled first and then installed as a python package (see LanguageModelDecoder/README.md).