


A C++ Implementation of YoloV8 using TensorRT
Supports object detection, semantic segmentation, and body pose estimation.
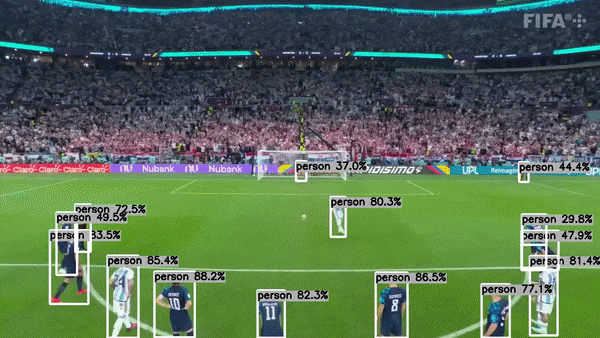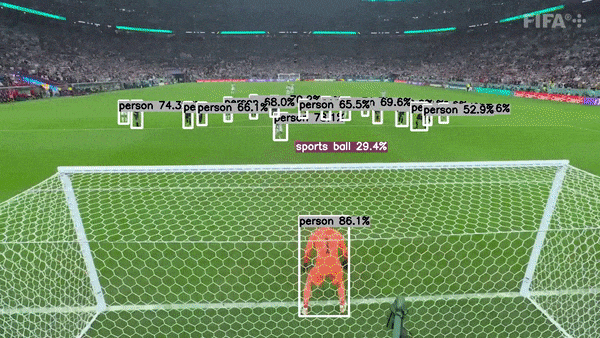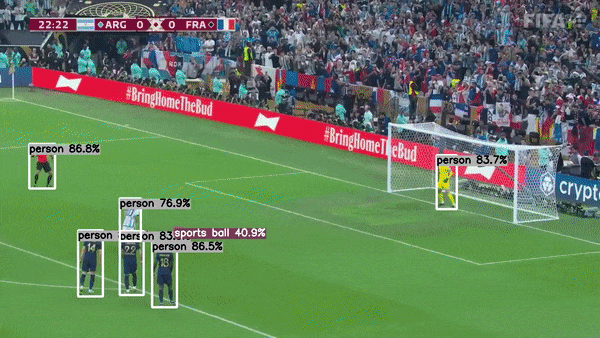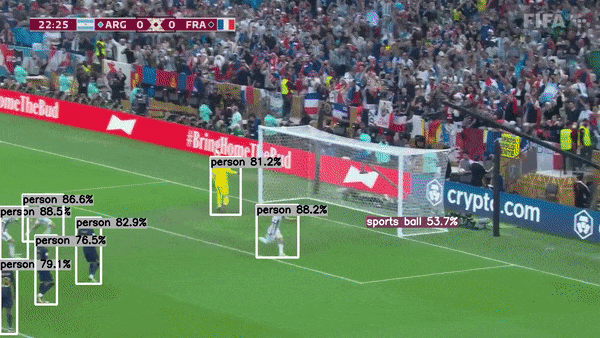

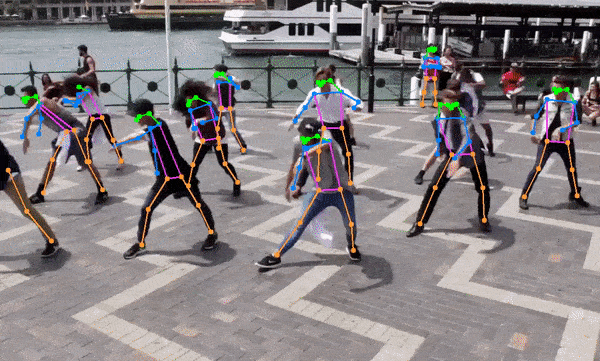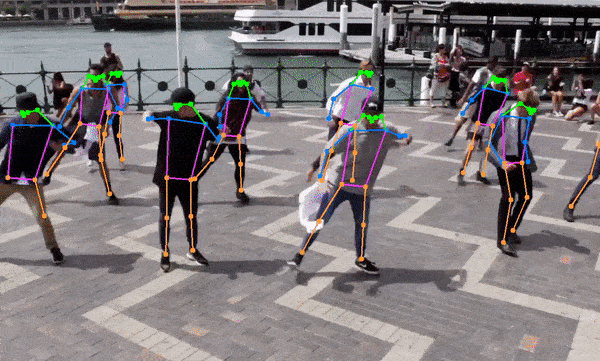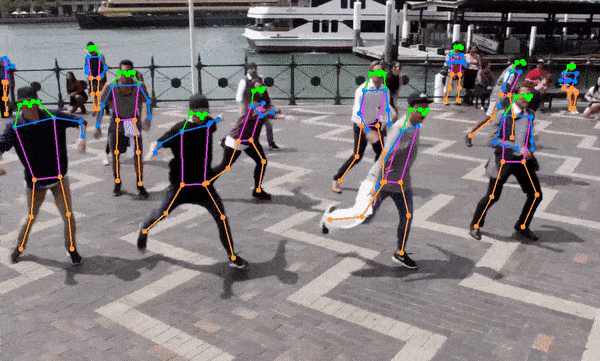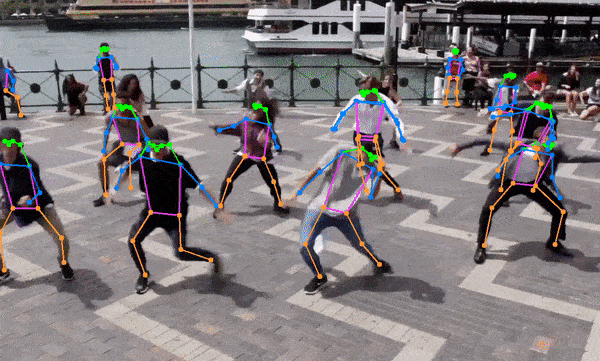
This project is actively seeking maintainers to help guide its growth and improvement. If you're passionate about this project and interested in contributing, I’d love to hear from you!
Please feel free to reach out via LinkedIn to discuss how you can get involved.
This project demonstrates how to use the TensorRT C++ API to run GPU inference for YoloV8. It makes use of my other project tensorrt-cpp-api to run inference behind the scene, so make sure you are familiar with that project.
- Tested and working on Ubuntu 20.04 & 22.04 (Windows is not supported at this time)
- Install CUDA, instructions here.
- Recommended >= 12.0
- Install cudnn, instructions here.
- Recommended >= 8
sudo apt install build-essentialsudo apt install python3-pippip3 install cmake- Install OpenCV with cuda support. To compile OpenCV from source, run the
build_opencv.shscript provided here.- Recommended >= 4.8
- Download TensorRT 10 from here.
- Required >= 10.0
- Extract, and then navigate to the
CMakeLists.txtfile and replace theTODOwith the path to your TensorRT installation.
git clone https://github.com/cyrusbehr/YOLOv8-TensorRT-CPP --recursive- Note: Be sure to use the
--recursiveflag as this repo makes use of git submodules.
- Navigate to the official YoloV8 repository and download your desired version of the model (ex. YOLOv8x).
- The code also supports semantic segmentation models out of the box (ex. YOLOv8x-seg) and pose estimation models (ex. yolov8x-pose.onnx).
pip3 install ultralytics- Navigate to the
scripts/directory and run the following: python3 pytorch2onnx.py --pt_path <path to your pt file>- After running this command, you should successfully have converted from PyTorch to ONNX.
- Note: If converting the model using a different script, be sure that
end2endis disabled. This flag will add bbox decoding and nms directly to the model, whereas my implementation does these steps external to the model using good old C++.
mkdir buildcd buildcmake ..make -j
- Note: the first time you run any of the scripts, it may take quite a long time (5 mins+) as TensorRT must generate an optimized TensorRT engine file from the onnx model. This is then saved to disk and loaded on subsequent runs.
- Note: The executables all work out of the box with Ultralytic's pretrained object detection, segmentation, and pose estimation models.
- To run the benchmarking script, run:
./benchmark --model /path/to/your/onnx/model.onnx --input /path/to/your/benchmark/image.png - To run inference on an image and save the annotated image to disk run:
./detect_object_image --model /path/to/your/onnx/model.onnx --input /path/to/your/image.jpg- You can use the images in the
images/directory for testing
- You can use the images in the
- To run inference using your webcam and display the results in real time, run:
./detect_object_video --model /path/to/your/onnx/model.onnx --input 0 - Note: You can also specify a TensorRT engine file by using the
--trt_modeloption if you have a pre-built TensorRT engine available. - For a full list of arguments, run any of the executables without providing any arguments.
Enabling INT8 precision can further speed up inference at the cost of accuracy reduction due to reduced dynamic range. For INT8 precision, calibration data must be supplied which is representative of real data the model will see. It is advised to use 1K+ calibration images. To enable INT8 inference with the YoloV8 sanity check model, the following steps must be taken:
- Download and extract the COCO validation dataset, or procure data representative of your inference data:
wget http://images.cocodataset.org/zips/val2017.zip - Provide the additional command line arguments when running the executables:
--precision INT8 --calibration-data /path/to/your/calibration/data - If you get an "out of memory in function allocate" error, then you must reduce
Options.calibrationBatchSizeso that the entire batch can fit in your GPU memory.
- Before running benchmarks, ensure your GPU is unloaded.
- Run the executable
benchmarkusing the/images/640_640.jpgimage. - If you'd like to benchmark each component (
preprocess,inference,postprocess), recompile setting theENABLE_BENCHMARKSflag toON:cmake -DENABLE_BENCHMARKS=ON ...- You can then rerun the executable
Benchmarks run on NVIDIA GeForce RTX 3080 Laptop GPU, Intel(R) Core(TM) i7-10870H CPU @ 2.20GHz using 640x640 BGR image in GPU memory and FP16 precision.
| Model | Total Time | Preprocess Time | Inference Time | Postprocess Time |
|---|---|---|---|---|
| yolov8n | 3.613 ms | 0.081 ms | 1.703 ms | 1.829 ms |
| yolov8n-pose | 2.107 ms | 0.091 ms | 1.609 ms | 0.407 ms |
| yolov8n-seg | 15.194 ms | 0.109 ms | 2.732 ms | 12.353 ms |
| Model | Precision | Total Time | Preprocess Time | Inference Time | Postprocess Time |
|---|---|---|---|---|---|
| yolov8x | FP32 | 25.819 ms | 0.103 ms | 23.763 ms | 1.953 ms |
| yolov8x | FP16 | 10.147 ms | 0.083 ms | 7.677 ms | 2.387 ms |
| yolov8x | INT8 | 7.32 ms | 0.103 ms | 4.698 ms | 2.519 ms |
TODO: Need to improve postprocessing time using CUDA kernel.
- If you have issues creating the TensorRT engine file from the onnx model, navigate to
libs/tensorrt-cpp-api/src/engine.cppand change the log level by changing the severity level tokVERBOSEand rebuild and rerun. This should give you more information on where exactly the build process is failing.
If this project was helpful to you, I would appreicate if you could give it a star. That will encourage me to ensure it's up to date and solve issues quickly.
 z3lx 💻 |
 Loic Tetrel 💻 |
 Shubham 💻 |
 Amirhosein Vedadi 💻 |