Text classification with naive Bayes.
To get the movie-reviews data, type:
cd data
./get-data.shFor the original 5-class movie-reviews, type:
./main.py --data data/classesFor the binarised reviews, use:
./main.py --data data/binaryYou can add the following arguments:
--remove 10 # Remove 10 most frequent words that are in all classes.
--no-punct # Remove punctuation (except ! and ?) from data.
--no-stop # Remove stop-words from data.Surprisingly, accuracy is best when both stop-words and punctuation are left as is. We illustrate below with cleaned text, however.
On the binarized movie reviews, the results are (with some highest conditional probabilities):
class 0 (0.478)
bad 0.00471
would 0.00347
plot 0.00280
? 0.00276
nothing 0.00269
really 0.00258
could 0.00255
action 0.00244
enough 0.00234
every 0.00234
script 0.00223
better 0.00223
minutes 0.00223
feels 0.00219
something 0.00219
made 0.00216
long 0.00205
movies 0.00205
makes 0.00198
seems 0.00198
class 1 (0.522)
love 0.00338
best 0.00329
us 0.00307
life 0.00292
makes 0.00289
may 0.00273
performances 0.00264
drama 0.00255
enough 0.00239
well 0.00236
new 0.00233
movies 0.00227
fun 0.00224
look 0.00220
films 0.00211
also 0.00208
great 0.00202
cast 0.00202
still 0.00199
performance 0.00199
label accuracy
0 69.86
1 78.60
For the 5-way classes, the results are:
class 0 (0.128)
bad 0.00695
comedy 0.00379
time 0.00369
characters 0.00358
would 0.00337
way 0.00326
nothing 0.00305
plot 0.00295
script 0.00295
minutes 0.00284
worst 0.00284
director 0.00274
could 0.00274
dull 0.00274
little 0.00263
makes 0.00263
thing 0.00263
really 0.00242
made 0.00232
make 0.00232
class 1 (0.260)
characters 0.00368
bad 0.00342
time 0.00342
little 0.00337
would 0.00337
never 0.00327
? 0.00307
comedy 0.00302
better 0.00276
action 0.00261
plot 0.00261
really 0.00256
enough 0.00256
make 0.00245
nothing 0.00240
way 0.00240
could 0.00235
every 0.00235
feels 0.00230
something 0.00230
class 2 (0.190)
? 0.00420
may 0.00312
time 0.00312
would 0.00297
never 0.00290
little 0.00290
comedy 0.00283
make 0.00275
characters 0.00268
enough 0.00261
funny 0.00254
way 0.00246
made 0.00232
! 0.00225
best 0.00225
many 0.00225
though 0.00217
could 0.00217
movies 0.00210
yet 0.00210
class 3 (0.272)
way 0.00320
funny 0.00320
love 0.00297
little 0.00297
us 0.00292
comedy 0.00288
director 0.00283
may 0.00283
makes 0.00278
time 0.00278
characters 0.00274
life 0.00269
enough 0.00269
make 0.00260
work 0.00260
look 0.00251
drama 0.00246
still 0.00227
new 0.00213
without 0.00204
class 4 (0.151)
best 0.00595
funny 0.00517
comedy 0.00474
love 0.00388
performances 0.00379
work 0.00353
performance 0.00319
well 0.00319
life 0.00310
us 0.00310
characters 0.00293
movies 0.00293
ever 0.00284
makes 0.00284
entertaining 0.00276
year 0.00276
make 0.00267
never 0.00267
films 0.00267
fun 0.00259
label accuracy
0 33.09
1 39.45
2 22.71
3 39.78
4 38.18
We can plot confusion matrices for the classes:
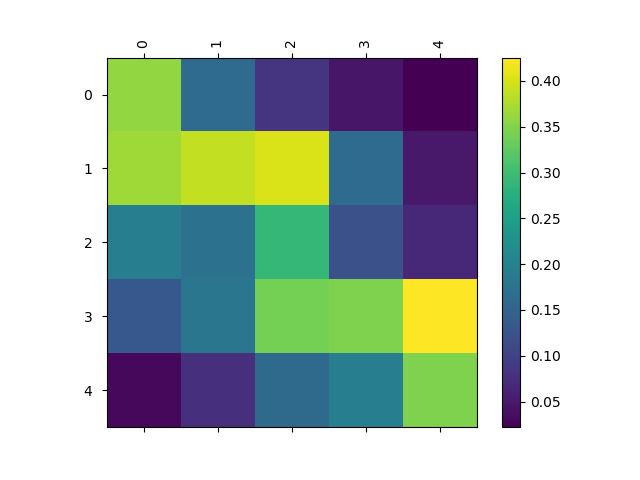
- Maybe we can do something a little more fancy, see Baselines and Bigrams: Simple, Good Sentiment and Topic Classification and this repository for ideas.
- Bayesian formulation with Gibbs sampling, see Gibbs sampling for the uninitiated.