Replication Processor
Motivation
This projects leverages Kafka Streams and Kafka Connect to offer an opinionated control pane to declare replication pipelines between two external data sources. This control plane currently interfaces as a Web Service.
This application takes your declarative Replication Definition manifest and instanciates the underlying Kafka Connectors as well as the required Streams Processor to transform the source data to a format expected by the destination supported datasources. Avro is required as it guarantees the right mapping between the sources and sinks.
The amount of configurable options is intented to serve simplicity over flexibility.
Ultimately, the goal of this project is to offer a simplified DSL to manage the flow of realtime ETL pipelines which constrats with the current requirement of configuring Kafka Connectors manually and writing custom Kafka Streams applications.
The vision of this project aims to offer a DSL with different clients, enabling a a tooling ecosystem can be built to help designing and testing data integration pipelines.
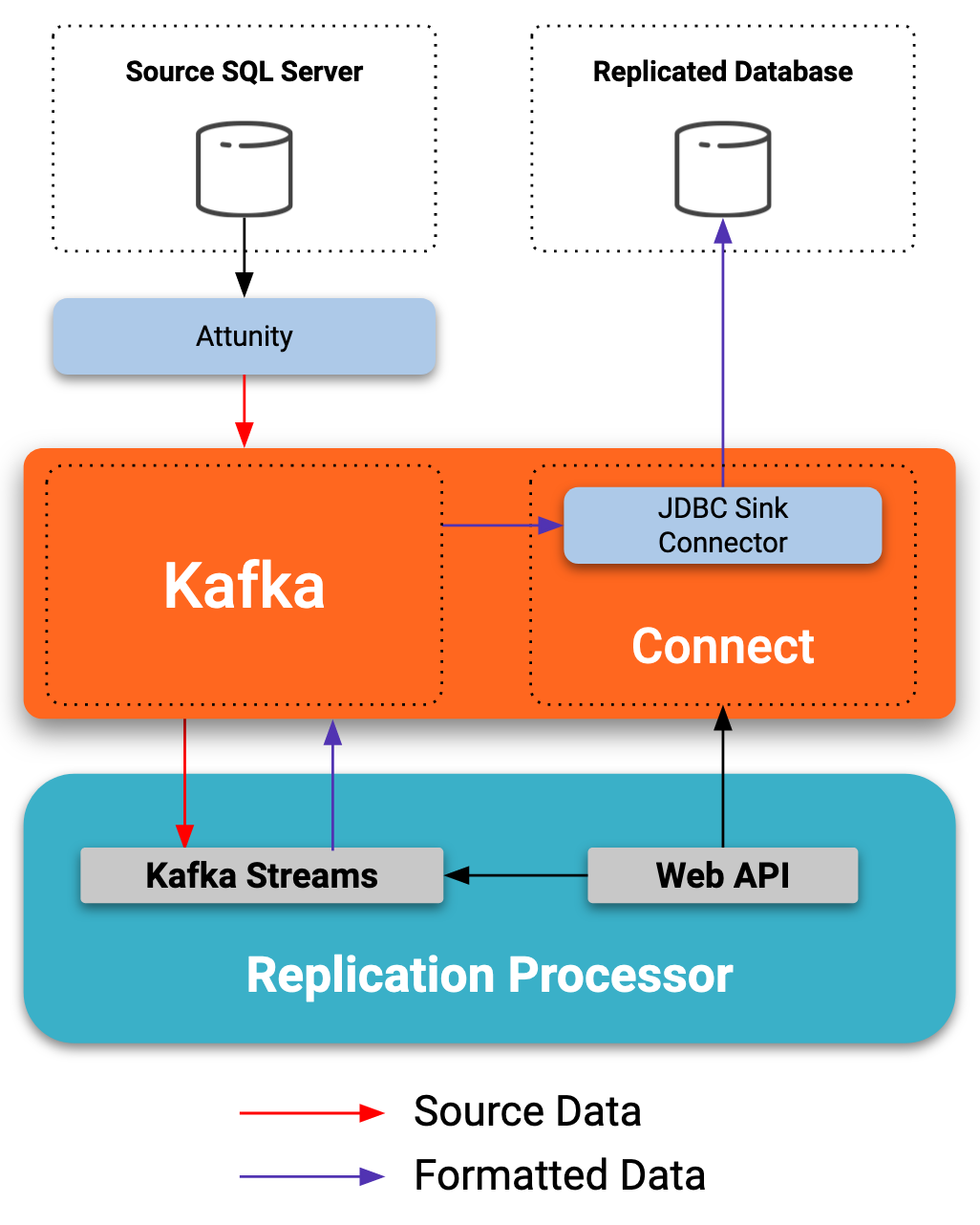
The supported sources are:
- Debezium CDC for SQL Server
- Debezium CDC for MySQL
- Any topic fed by Attunity
The supported destinations are:
- SqlServer
- MySQL
Upcoming improvements
- Sources:
- Debezium CDC for PostgreSQL
- Debezium CDC for Cassandra
- MongoDB
- Sinks
- PostgreSQL
- Oracle
- SQLite
- MongoDB
- Cassandra
- Management UI (Maybe?)