- /shanes_work - shanes stuff (private work-folder)
- /colins_work - colins stuff (private work-folder)
- /base_implementation - fixed receiver, transmitter
- /decentralized_implementation - decentralized approach
- /plots - archive for cool gifs and plots to be used in the future
-
Introduction
Applying learning algorithms to classic radio tasks -
Related Work
- Foerster - multi-agent but centralized learning
- OpenAI - multi-agents learning comms but differentiable
- Google Brain - Learning coding, mutual information, but shared gradients, adverserial setting
- some papers on network parameter tuning with RL
- ...?
-
Background Information
- Low Level Wireless Communication
Complex signals, modulation, classic modulation schemes, Gray coding, perfomance plots - Reinforcement Learning
Markov Decision Process, optimization problem, policy gradients, vanilla score function gradient estimator
- Low Level Wireless Communication
-
Preliminary Analysis (Data driven approaches to classic radio tasks)
- Modulation Recognition
Eb/N0 Plots over #training samples -> Result: receiving is easy, so keep it easy - Symbol Timing Recovery (How to evaluate?)
- Equalization
- Training a single agent
Only transmitter, since receiver is easy
- Modulation Recognition
-
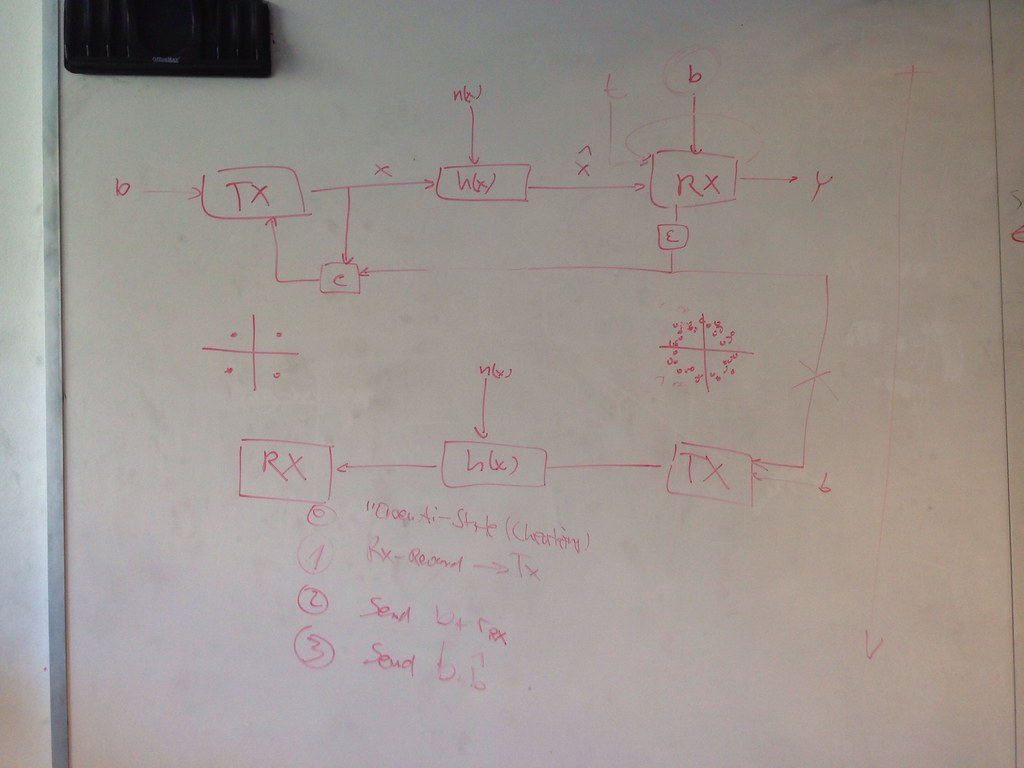
Problem formulation
Decentralized, multi-agent learning of modulation -
Problem setup
Two agents, shared preamble, transmitter and receiver architecture, echoing, no other shared information -
Results
Two evaluation methods:- loss plot: L1 difference between b^^ and b over training
- performance plot: BER over EbN0 after training
- Unrestricted power during learning
- preamble BER during training (loss-plot)
- BER over Eb/N0 after learning (performance plot)
- development of Eb
- Restricted power during learning
- preamble BER during testin (loss-plot)
- BER of Eb_N0 after learning (performance plot)
4/11: fixed Tx/Rx 4/17: one page description due at beginning of class 5/8: 5-8 page report
look at apsk, bpsk, qpsk, 16-quam do we want to whether we want to paramaterize output of transmitter as cartesian or polar?
fixed Tx, learn Rx:
⋅⋅⋅input x,y of complex, softmax output + eps greedy / boltzman exploration
tasks:
-
reward shaping for transmitter (need to restrict power and maximize distance between points. former must be stronger than latter to prevent outer points from flying away)
-
Tx -> Rx and Rx gives reward back to Tx. Rx provides k-nn guess for each datasample back to Tx
-
Tx on both sides, Rx on both sides.
-
OpenAI style
https://www.sharelatex.com/project/58fe82f296da09b1289caec3