This solution accelerator notebook is also available at https://github.com/databricks-industry-solutions/hls-patient-risk
Patient-Level Risk Scoring Based on Condition History
Longitudinal health records contain a wealth of information regarding a patient's risk factors. For instance, standard machine learning techniques can be employed to examine the correlation between a patient's health history and specific outcomes, such as heart attacks (refer to this review article). In this case, we utilize a patient's medical condition history, medications taken, and demographic information as inputs. We then analyze a patient's encounter history to identify individuals diagnosed with a particular condition (CHF in this example) and train a machine learning model to predict the risk of an adverse outcome (emergency room admission) within a specified timeframe. In this solution accelerator, we assume that the patient data are already stored in an OMOP 5.3 CDM on Delta Lake. We use OHDSI's patient-level risk prediction methodology to train a classifier that predicts the risk.
Workflow overview
In this solution accelerator, we cover:
- Ingesting simulated clinical data from 100,000 patients prepared in OMOP 5.3 CDM and creating an OMOP data schema.
- Creating cohorts and cohort attributes.
- Generating features based on a patient's history.
- Training a classifier to predict outcomes using AutoML.

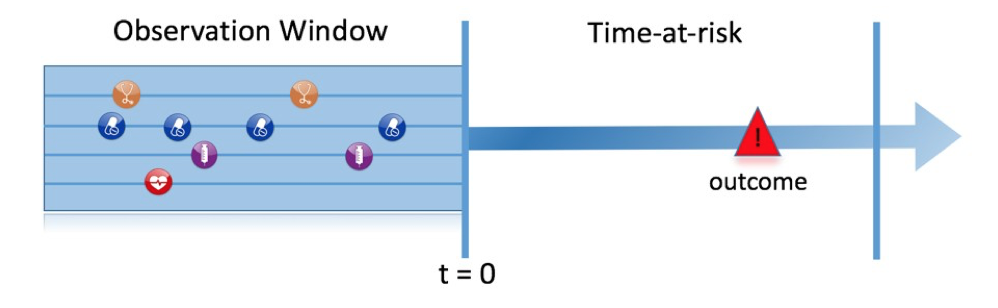
Experiment Design
In this section we outline the terminology used in this solution accelerator, based on on the experiment design outlined in the Book of OHDSI
| Choice | Description |
|---|---|
| Target cohort | How do we define the cohort of persons for whom we wish to predict? |
| Outcome cohort | How do we define the outcome we want to predict? |
| Time-at-risk | In which time window relative to t=0 do we want to make the prediction? |
| Model | What algorithms do we want to use, and which potential predictor variables do we include? |
Washout Period: days (int):
The minimum amount of observation time required before the start of the target cohort. This choice could depend on the available patient time in the training data, but also on the time we expect to be available in the data sources we want to apply the model on in the future. The longer the minimum observation time, the more baseline history time is available for each person to use for feature extraction, but the fewer patients will qualify for analysis. Moreover, there could be clinical reasons to choose a short or longer look-back period. For our example, we will use a 365-day prior history as look-back period (washout period)
Allowed in cohort multiple times? (boolean):
Can patients enter the target cohort multiple times? In the target cohort definition, a person may qualify for the cohort multiple times during different spans of time, for example if they had different episodes of a disease or separate periods of exposure to a medical product. The cohort definition does not necessarily apply a restriction to only let the patients enter once, but in the context of a particular patient-level prediction problem we may want to restrict the cohort to the first qualifying episode. In our example, a person can only enter the target cohort once, i.e. patients who have been diagnosed with CHF most recently.
Inlcude if they have experienced the outcome before? (boolean):
Do we allow persons to enter the cohort if they experienced the outcome before? Do we allow persons to enter the target cohort if they experienced the outcome before qualifying for the target cohort? Depending on the particular patient-level prediction problem, there may be a desire to predict incident first occurrence of an outcome, in which case patients who have previously experienced the outcome are not at risk for having a first occurrence and therefore should be excluded from the target cohort. In other circumstances, there may be a desire to predict prevalent episodes, whereby patients with prior outcomes can be included in the analysis and the prior outcome itself can be a predictor of future outcomes. For our prediction example, we allow all patients who have experienced the outcome - emergency room visits - to be allowed in the target cohort.
time at risk period (start,end), start should be greater or equal than the target cohort start date**:
How do we define the period in which we will predict our outcome relative to the target cohort start? We have to make two decisions to answer this question. First, does the time-at-risk window start at the date of the start of the target cohort or later? Arguments to make it start later could be that we want to avoid outcomes that were entered late in the record that actually occurred before the start of the target cohort or we want to leave a gap where interventions to prevent the outcome could theoretically be implemented. Second, we need to define the time-at-risk by setting the risk window end, as some specification of days offset relative to the target cohort start or end dates. For our problem we will predict in a time-at-risk window starting 7 days after the start of the target cohort (
min_time_at_risk=7) up to 365 days later (max_time_at_risk = 365)
Parameter descriptions
| parameter name | description | default value |
|---|---|---|
target_condition_concept_id |
qualifying condition to enter the target cohort | 4229440 (CHF) |
outcome_concept_id |
outcome to predict | 9203 (Emergency Room Visit) |
drug1_concept_id |
concept id for drug exposure history | 40163554 (Warfarin) |
drug2_concept_id |
concept id for drug exposure history | 40221901 (Acetaminophen) |
cond_history_years |
years of patient history to look up | 5 |
max_n_commorbidities |
max number of commorbid conditions to use for the prediction probelm | 5 |
min_observation_period |
whashout period in days | 1095 |
min_time_at_risk |
days since target cohort start to start the time at risk | 7 |
max_time_at_risk |
days since target cohort start to end time at risk window | 365 |
Model Training
To train the classifier, we employ Databricks AutoML, which selects the best model based on the provided training dataset. AutoML takes the process a step further by generating a notebook containing pre-loaded code outlining all the necessary steps for model training. This not only saves time but also ensures consistency throughout the process.
In addition, the code incorporates feature importance analysis, allowing for the assessment of each feature's significance in the model. This analysis offers valuable insights into the factors influencing the model's predictions and can aid in enhancing the model's overall performance. Leveraging AutoML's advanced capabilities enables users to efficiently create high-performing models while minimizing the time and effort required for training and feature analysis.

Copyright / License info of the notebook. Copyright Databricks, Inc. [2023]. The source in this notebook is provided subject to the Databricks License. All included or referenced third party libraries are subject to the licenses set forth below.
| Library Name | Library License | Library License URL | Library Source URL |
|---|---|---|---|
| Smolder | Apache-2.0 License | https://github.com/databrickslabs/smolder | https://github.com/databrickslabs/smolder/blob/master/LICENSE |
| Synthea | Apache License 2.0 | https://github.com/synthetichealth/synthea/blob/master/LICENSE | https://github.com/synthetichealth/synthea |
| OHDSI/CommonDataModel | Apache License 2.0 | https://github.com/OHDSI/CommonDataModel/blob/master/LICENSE | https://github.com/OHDSI/CommonDataModel |
| OHDSI/ETL-Synthea | Apache License 2.0 | https://github.com/OHDSI/ETL-Synthea/blob/master/LICENSE | https://github.com/OHDSI/ETL-Synthea |
| OHDSI/OMOP-Queries | https://github.com/OHDSI/OMOP-Queries | ||
| The Book of OHDSI | Creative Commons Zero v1.0 Universal license. | https://ohdsi.github.io/TheBookOfOhdsi/index.html#license | https://ohdsi.github.io/TheBookOfOhdsi/ |