![]()
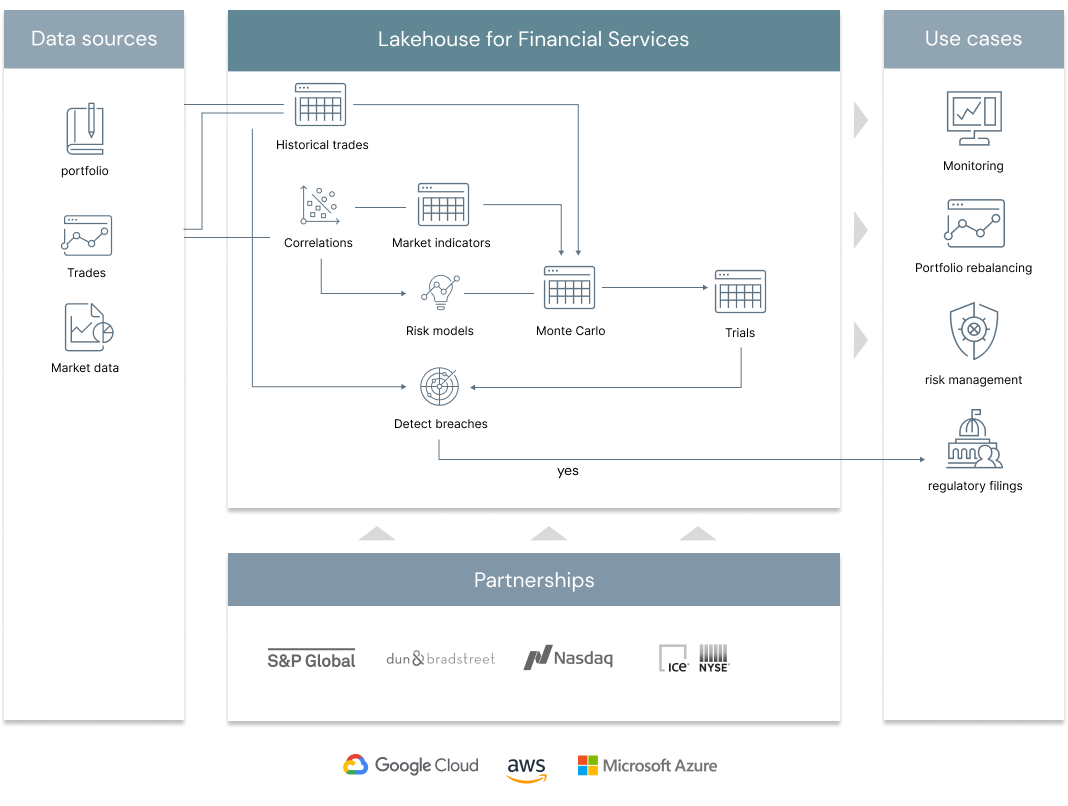
This solution has two parts. First, it shows how Delta Lake and MLflow can be used for value-at-risk calculations – showing how banks can modernize their risk management practices by back-testing, aggregating and scaling simulations by using a unified approach to data analytics with the Lakehouse. Secondly. the solution uses alternative data to move towards a more holistic, agile and forward looking approach to risk management and investments.
© 2022 Databricks, Inc. All rights reserved. The source in this notebook is provided subject to the Databricks License [https://databricks.com/db-license-source]. All included or referenced third party libraries are subject to the licenses set forth below.
| library | description | license | source |
|---|---|---|---|
| Yfinance | Yahoo finance | Apache2 | https://github.com/ranaroussi/yfinance |
| tempo | Timeseries library | Databricks | https://github.com/databrickslabs/tempo |
| PyYAML | Reading Yaml files | MIT | https://github.com/yaml/pyyaml |
To run this accelerator, clone this repo into a Databricks workspace. Switch to the web-sync branch if you would like to run the version of notebooks currently published on the Databricks website. Attach the RUNME notebook to any cluster running a DBR 11.0 or later runtime, and execute the notebook via Run-All. A multi-step-job describing the accelerator pipeline will be created, and the link will be provided. Execute the multi-step-job to see how the pipeline runs. The job configuration is written in the RUNME notebook in json format. The cost associated with running the accelerator is the user's responsibility.