![]()
OpenSource solution that defines and manages the complete lifecycle of resources used and provisioned into a cloud!
Explore the docs »
Table of Contents
SLD helps to accelerate deployment, weighting and making IaaC reusable, generating dynamic forms and maintaining different variables in each environment with the same code. With SLD you can schedule infrastructure deployments like its destruction, manage users by roles and separate stacks by squad and environment
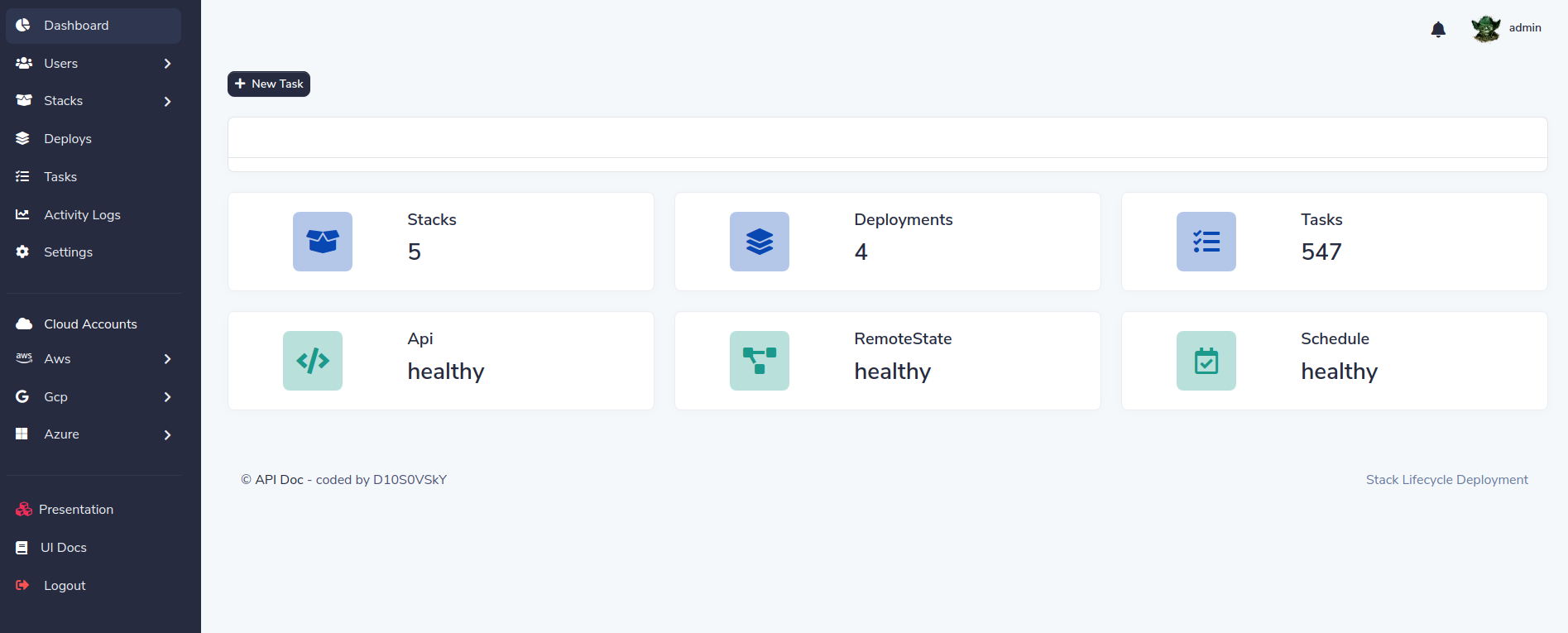

Main features:
- Fast API async
- Dashboard / UI
- Distributed tasks routing by squad
- Infrastructure as code (IaC) based in terraform code
- Dynamic html form from terraform variables
- Re-deploy infrastructure keeping the above parameters
- Distributed architecture based microservices
- Task decouple and event driven pattern
- Resilient, rollback deployment and retry if failure
SLD is the easy way to use your terrafrom code!
You need docker and docker-compse or kind ( recomended ).
-
Clone the SLD repo
git clone https://github.com/D10S0VSkY-OSS/Stack-Lifecycle-Deployment.git
-
Deploy SLD in k8s with kind
cd Stack-Lifecycle-Deployment/play-with-sld/kubernetes sh kplay.sh startResult:
Starting SLD for play Creating cluster "kind" ... ✓ Ensuring node image (kindest/node:v1.20.2) 🖼 ✓ Preparing nodes 📦 📦 ✓ Writing configuration 📜 ✓ Starting control-plane 🕹️ ✓ Installing CNI 🔌 ✓ Installing StorageClass 💾 ✓ Joining worker nodes 🚜 Set kubectl context to "kind-kind" You can now use your cluster with: kubectl cluster-info --context kind-kind
-
Create init user
sh kplay.sh init
Result:
kind ok docker ok kubectl ok jq ok curl ok init SLD ################################################# # Now, you can play with SLD 🕹️ # ################################################# API: http://localhost:5000/docs DASHBOARD: http://localhost:5000/ --------------------------------------------- username: admin password: Password08@ ---------------------------------------------
List endopints
sh kplay.sh list
Result:
kind ok docker ok kubectl ok List endpoints API: http://localhost:8000/docs DASHBOARD: http://localhost:5000/
-
Sign-in to DASHBOARD:

Click the dashboard link:

-
Add Cloud account
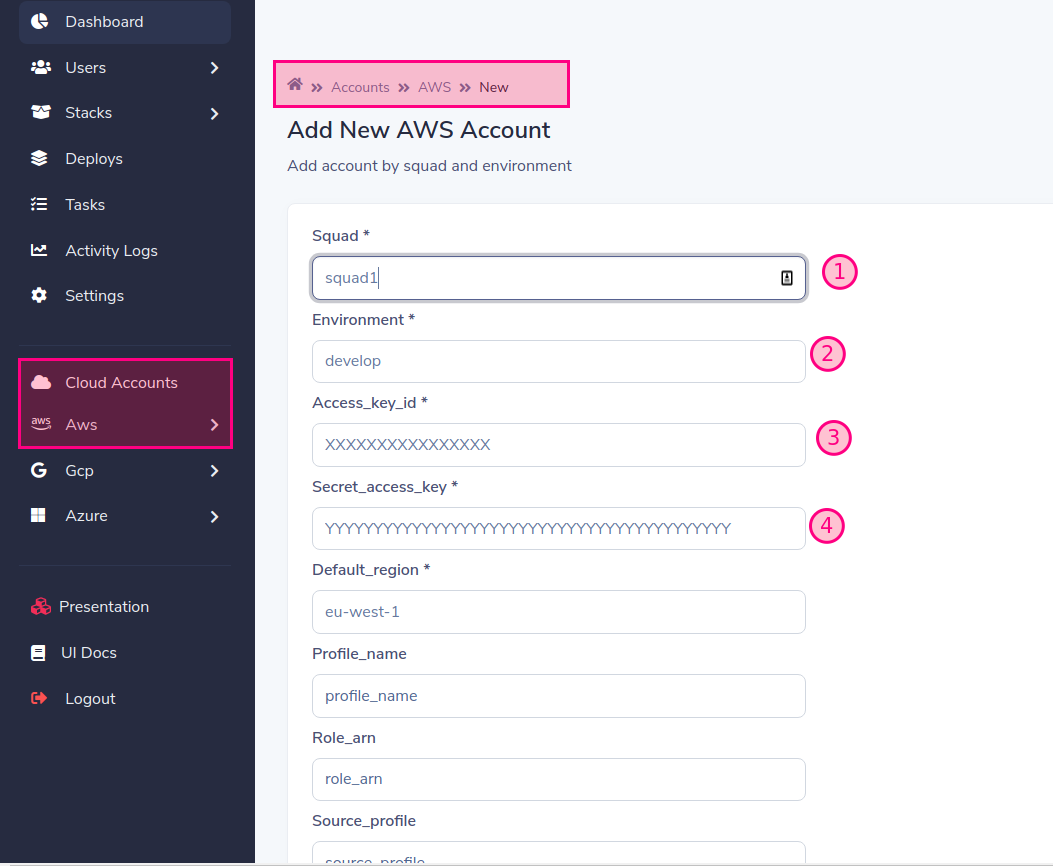
fill in the form with the required data. in our example we will use
- Squad: squad1
- Environment: develop
by default workers are running as squad1 and squad2 for play purpose, but you can change it and scale when you want
When you add an account to a provider ( aws, gcp, azure ) one squad is created, you must create a worker for the name of the created squad, if you don't do it the deployment will remain in a "PENDING" state Read Workers
finally add:
- Access_key_id
- Secret_access_key
- Default_region ( default eu-west-1) In case you use assume role, fill in the rest of the data.
-
Add terraform module or stack
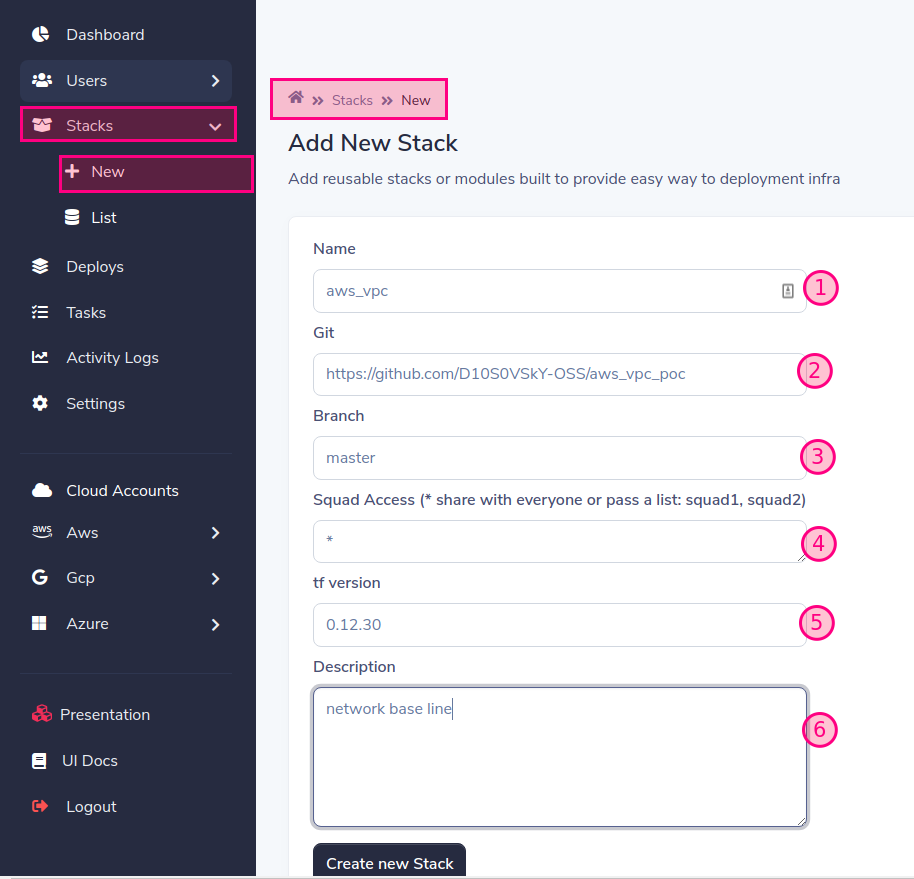
- Name: Add the name with a valid prefix according to the cloud provider.
Prefixs supported: aws_ , gcp_, azure_
- git: Add a valid git repository, like github, gitlab, bitbucket, etc. in our case to play we use (https://github.com/D10S0VSkY-OSS/aws_vpc_poc)
You can pass user and password as https://username:password@github.com/aws_vpc For ssh you can pass it as a secret in the deployment to the user sld
- Branch: Add the branch you want to deploy by default is master
- Squad Access: Assign who you want to have access to this stack by squad
'*' = gives access to all, you can allow access to one or many squads separated by commas: squad1,squad2
- tf version: indicates the version of terraform required by the module or stack
- Description: Describe the module or stack to help others during implementation.
-
Deploy your first stack!!!
List stacks for deploy

Choose deploy

SLD will generate a dynamic form based on the stack variables, fill in the form and press the Deploy button
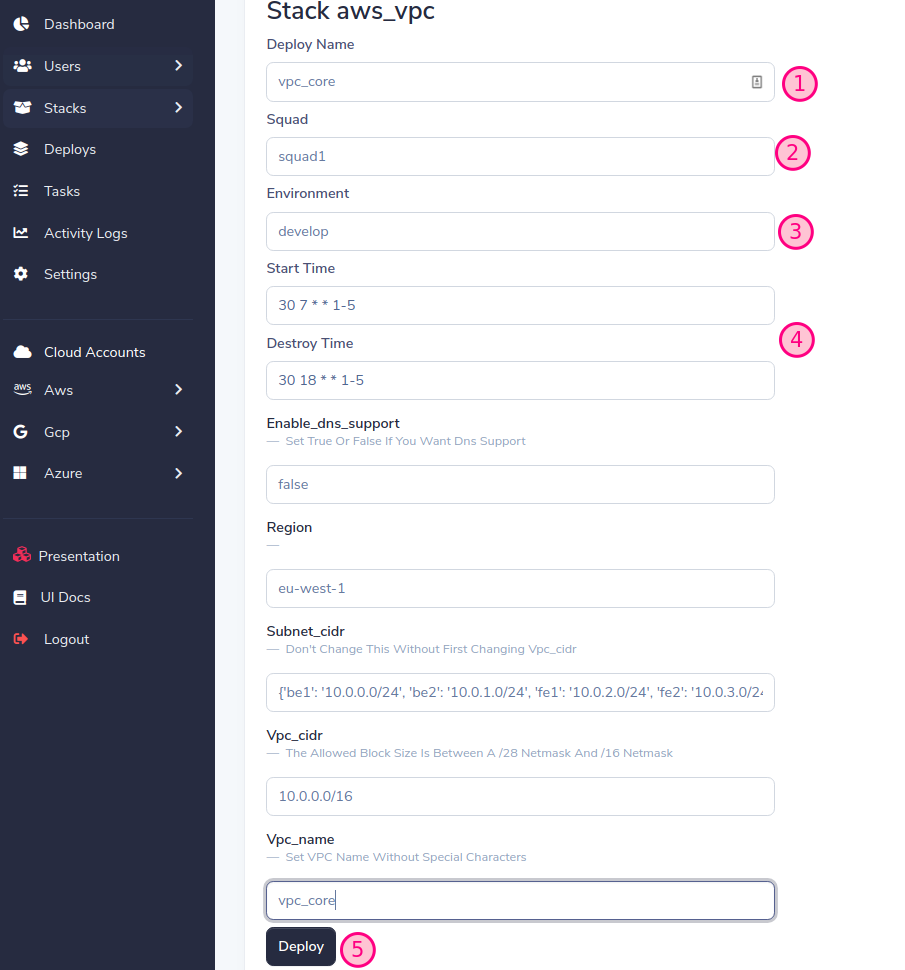
Important! assign the same squad and environment that we previously created when adding the account (See Add Cloud account)
Now, the status of the task will change as the deployment progresses.
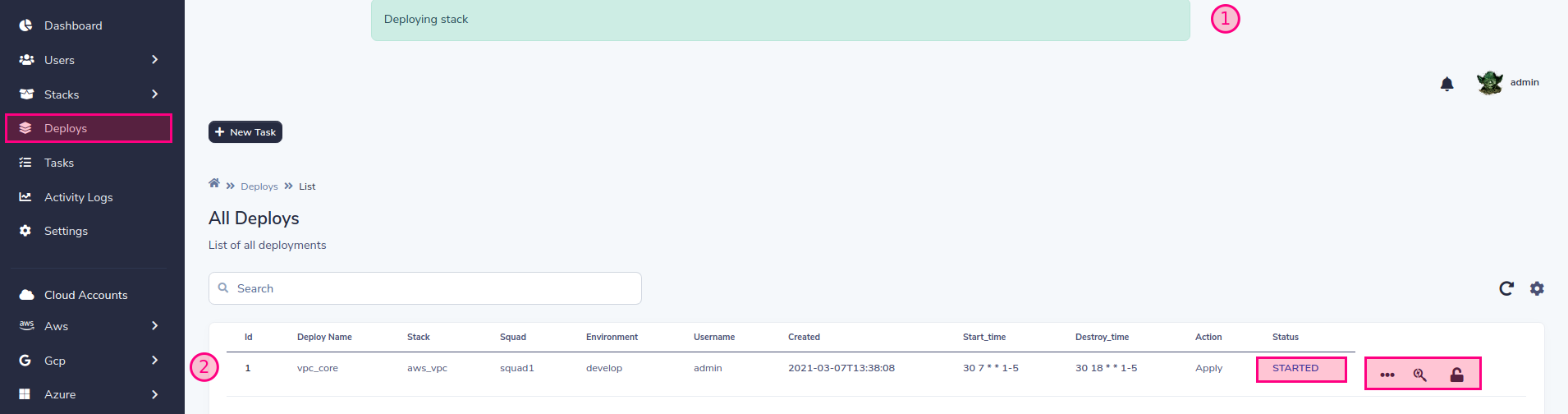
You can control the implementation life cycle
 You can destroy, re-implement that SLD will keep the old values or you can also edit those values at will.
You can destroy, re-implement that SLD will keep the old values or you can also edit those values at will.
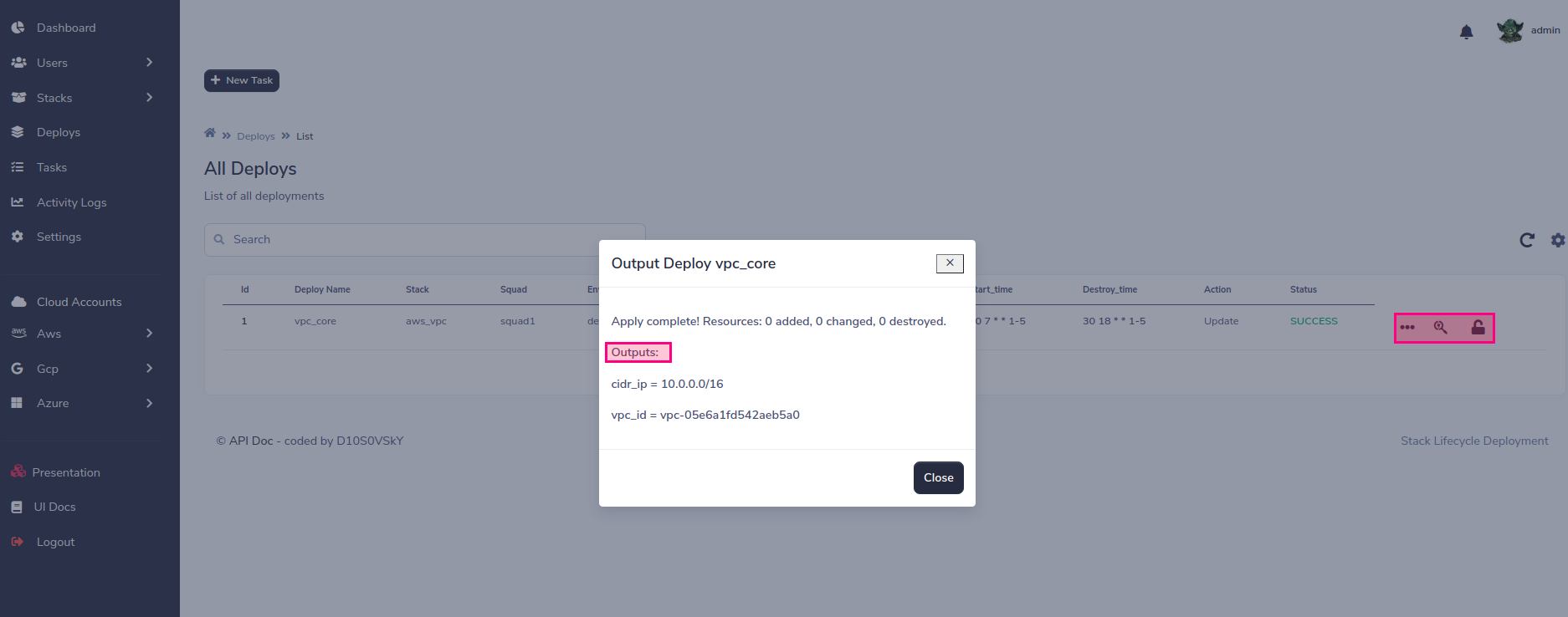 And finally you can manage the life cycle programmatically, handle the destruction / creation of the infrastructure, a good practice for the savings plan!!!
And finally you can manage the life cycle programmatically, handle the destruction / creation of the infrastructure, a good practice for the savings plan!!!
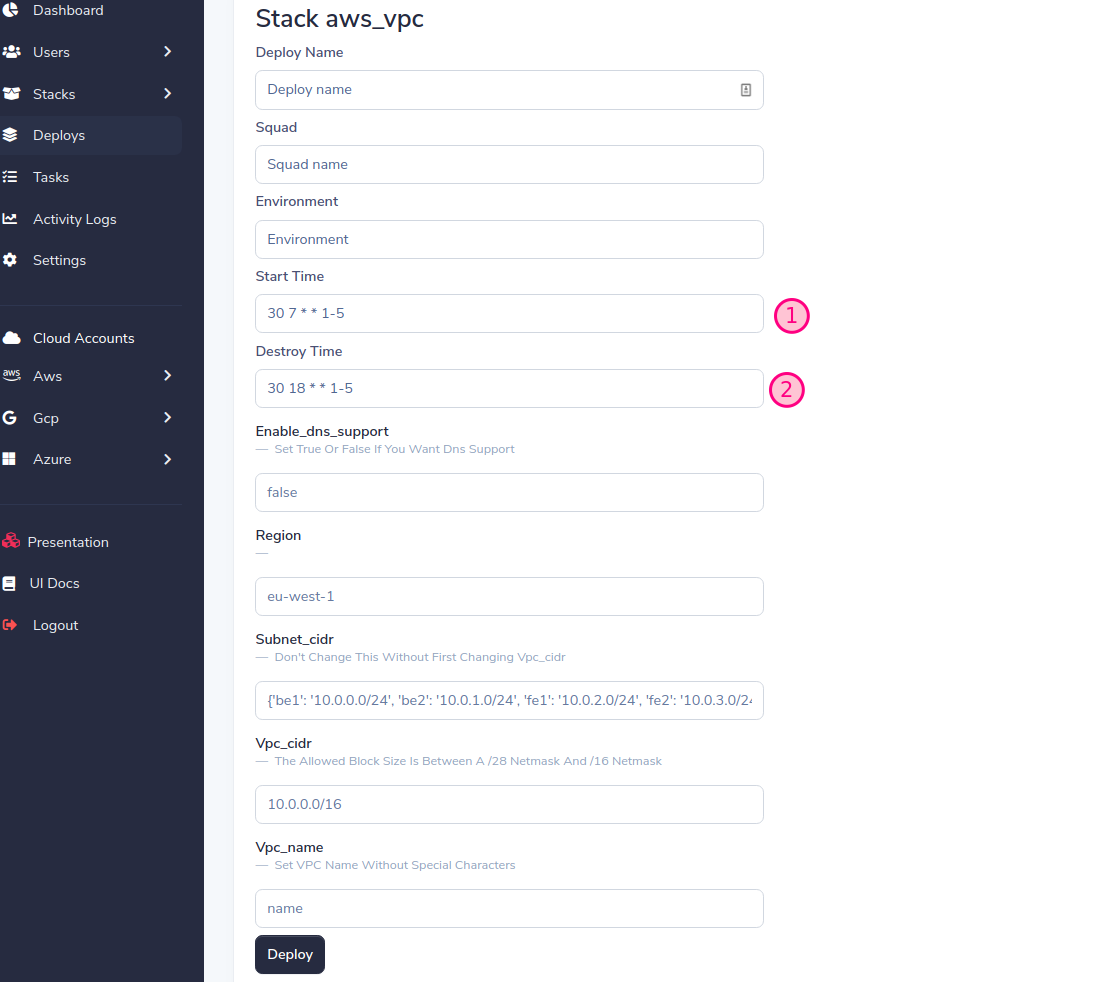











SLD uses its own remote backend, so you don't need to configure any backend in terraform. The following example shows a backend config
terraform {
backend "http" {
address = "http://remote-state:8080/terraform_state/aws_vpc-squad1-develop-vpc_core"
lock_address = "http://remote-state:8080/terraform_lock/aws_vpc-squad1-develop-vpc_core"
lock_method = "PUT"
unlock_address = "http://remote-state:8080/terraform_lock/aws_vpc-squad1-develop-vpc_core"
unlock_method = "DELETE"
}
}
At the moment SLD supports MongoDB, S3 and local backend (for testing purposes only) To configure MongoDB as a backend, you must pass the following variables as parameters to the remote-state service:
# docker-compose.yaml
environment:
SLD_STORE: mongodb
SLD_MONGODB_URL: "mongodb:27017/"
MONGODB_USER: admin
MONGODB_PASSWD: admin
# k8s yaml
env:
- name: SLD_STORE
value: mongodb
- name: SLD_MONGODB_URL
value: "mongodb:27017/"
- name: MONGODB_USER
value: admin
- name: MONGODB_PASSWD
value: admin
To configure S3 you can pass the access and secret keys of aws, in case SLD is running in AWS it is recommended to use roles
env:
- name: SLD_STORE
value: "S3"
- name: SLD_BUCKET
value: "s3-sld-backend-cloud-tf-state"
- name: AWS_ACCESS_KEY
value: ""
- name: AWS_SECRET_ACCESS_KEY
value: ""
For Azure env you need set the next env
env:
- name: SLD_STORE
value: azure
- name: AZURE_STORAGE_CONNECTION_STRING
value: "DefaultEndpointsProtocol=https;AccountName=<YOUR ACCOUNT>;AccountKey=<YOUR ACCESS KEY>;EndpointSuffix=core.windows.net"
See azure-storage-configure-connection-string
For google cloud storage set:
SLD_STORE=gcp
export GOOGLE_APPLICATION_CREDENTIALS="/app/sld-gcp-credentials.json"
Import google service account key to k8s secret
kubectl create secret generic gcp-storage --from-file=~/Downloads/storage.json
Modify sld-remote-state.yml set gcp storage cloud backend and mount secret:
apiVersion: apps/v1
kind: Deployment
metadata:
name: remote-state
labels:
name: remote-state
spec:
replicas: 1
selector:
matchLabels:
name: remote-state
template:
metadata:
labels:
name: remote-state
spec:
subdomain: primary
containers:
- name: remote-state
image: d10s0vsky/sld-remote-state:latest
volumeMounts:
- name: gcp
mountPath: "/app/gcp"
readOnly: true
env:
- name: SLD_STORE
value: gcp
- name: GOOGLE_APPLICATION_CREDENTIALS
value: "/app/gcp/storage.json"
resources:
limits:
memory: 600Mi
cpu: 1
requests:
memory: 300Mi
cpu: 500m
imagePullPolicy: Always
command: ["python3", "-m", "uvicorn", "main:app", "--host", "0.0.0.0", "--port", "8080", "--workers", "1"]
ports:
- containerPort: 8080
livenessProbe:
httpGet:
path: /
port: 8080
httpHeaders:
- name: status
value: healthy
initialDelaySeconds: 60
periodSeconds: 60
volumes:
- name: gcp
secret:
secretName: gcp-storage
To be able to use the outputs of other stacks you can configure it as follows the key alwys is the same like "Task Name"
| stack-name | squad account | env | deploy name |
|---|---|---|---|
| aws_vpc | squad1 | develop | vpc_core |
data "terraform_remote_state" "vpc_core" {
backend = "http"
config = {
address = "http://remote-state:8080/terraform_state/aws_vpc-squad1-develop-vpc_core"
}
}
Test example:
echo "data.terraform_remote_state.vpc_core.outputs"|terraform console
The workers in sld are responsible for executing the infrastructure deployment. You can use one or more workers for each account or several accounts at the same time. It all depends on the degree of parallelism and segregation that you consider
# Example k8s worker for account squad1, change this for each of your accounts
# Stack-Lifecycle-Deployment/play-with-sld/kubernetes/k8s/sld-worker-squad1.yml
# Add replicas for increment paralelism
# Add more squad accounts if you want to group accounts in the same worker:
# command: ["celery", "--app", "tasks.celery_worker", "worker", "--loglevel=info", "-c", "1", "-E", "-Q", "squad1,"another_squad_account"]
apiVersion: apps/v1
kind: Deployment
metadata:
name: stack-deploy-worker-squad1
labels:
name: stack-deploy-worker-squad1
spec:
replicas: 1
selector:
matchLabels:
name: stack-deploy-worker-squad1
template:
metadata:
labels:
name: stack-deploy-worker-squad1
spec:
subdomain: primary
containers:
- name: stack-deploy-worker-squad1
image: d10s0vsky/sld-api:latest
imagePullPolicy: Always
env:
- name: TF_WARN_OUTPUT_ERRORS
value: "1"
resources:
limits:
memory: 600Mi
cpu: 1
requests:
memory: 300Mi
cpu: 500m
command: ["celery", "--app", "tasks.celery_worker", "worker", "--loglevel=info", "-c", "1", "-E", "-Q", "squad1"]
# Example docker-compose worker for account squad1, change this for each of your accounts
# Stack-Lifecycle-Deployment/play-with-sld/docker/docker-compose.yml
worker:
image: d10s0vsky/sld-api:latest
entrypoint: ["celery", "--app", "tasks.celery_worker", "worker", "--loglevel=info", "-c", "1", "-E", "-Q", "squad1"]
environment:
BROKER_USER: admin
BROKER_PASSWD: admin
depends_on:
- rabbit
- redis
- db
- remote-state
SLD has three preconfigured roles for users to easily manage this.
| roles | scope | description |
|---|---|---|
| yoda | global | Global scope, can see all squads and are full admin |
| darth_vader | one or many squad | Limit the scope of the squad, can see the assigned squads and you are a full manager of only those squads |
| stormtrooper | one or many squad | Limits squad range, can see assigned squads and can only deploy assigned deployment on belong squad |
| R2-D2 | all, one or many squad | This role is only for identification and must be associated with the previous ones, its use case is for bot users who access the api |

- LDAP and SSO authentication
- Slack integration
- FluenD / elasticSearch integration
- InfluxDB integration
- Prometheus
- Estimate pricing by stack
- Anomaly detection
- Advance metrics and logs
- Resource size recommendation based on metrics
- Shift Left Security deployment
- Multi tenancy
- Topology graphs
- Mutal TLS
- Added workers automatically by squad
- Onboarding resources
- Add more cloud and on-prem providers
Contributions are what makes the open source community such an amazing place to be learn, inspire, and create. Any contributions you make are greatly appreciated.
- Fork the Project
- Create your Feature Branch (
git checkout -b feature/AmazingFeature) - Commit your Changes (
git commit -m 'Add some AmazingFeature') - Push to the Branch (
git push origin feature/AmazingFeature) - Open a Pull Request
Distributed under the MIT License. See LICENSE for more information.