![]()

This is a sandbox project for exploring the basic functionality and latest features of dbt. This is part of a three project mesh with a finance project and a platform project that contains the upstream dependencies.
-
Click the green "Use this template" button at the top of the page to create a new repository from this template.
-
Follow the steps to create a new repository.

- Set up a dbt Cloud account and follow Step 4 in the Quickstart instructions for your data platform, to connect your platform to dbt Cloud.
- Choose the repo you created in Step 1 as the repository for your dbt Project code.
- Click
Developin the top nav, you should be prompted to run adbt deps, which you should do.
-
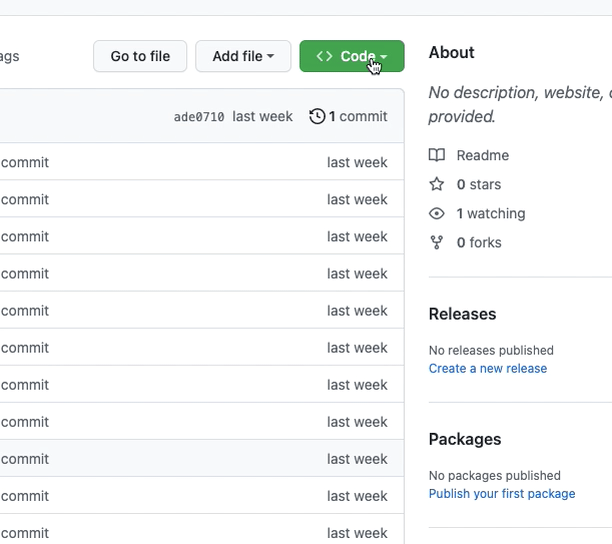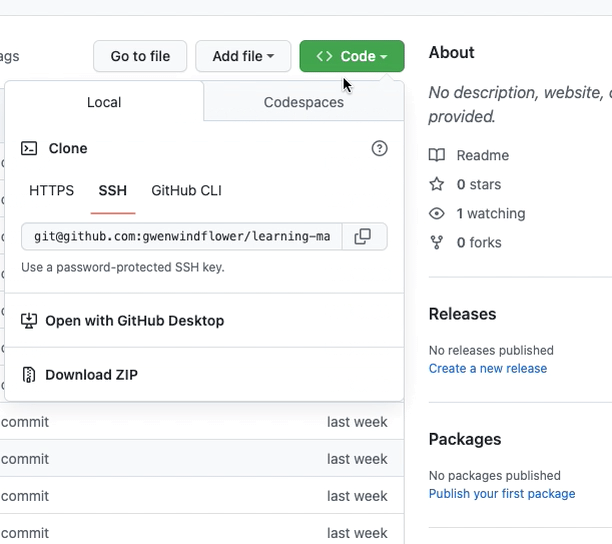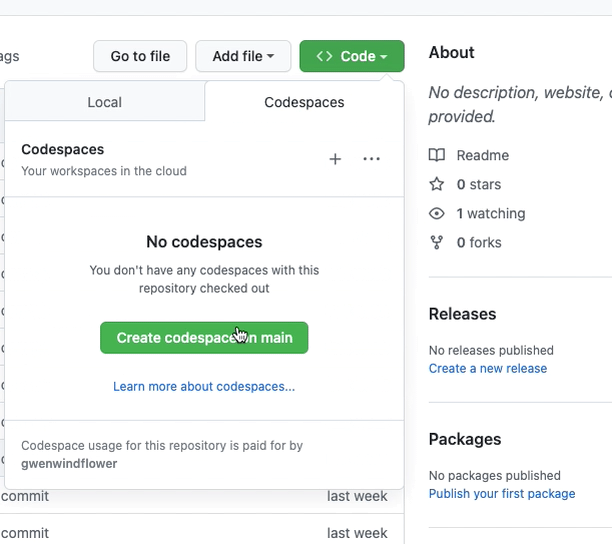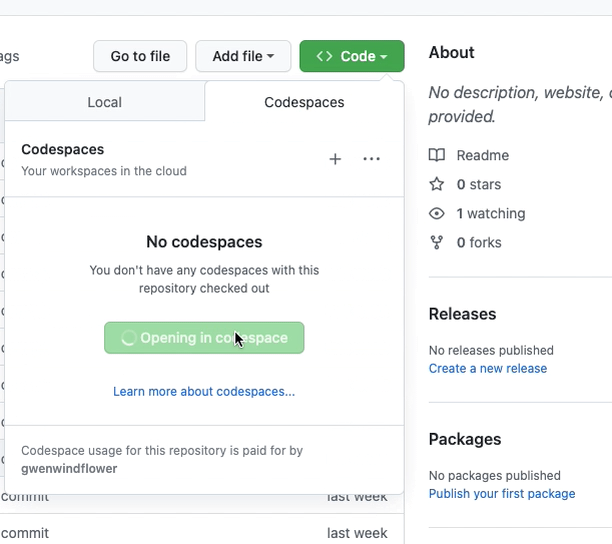
In the new repository, click the green "Code" button and select "Open with Codespaces" from the dropdown. If possible, open in VSCode locally rather than the web version, performance is significantly better. You can also click the 'Open in Codespaces' badge at the top of the README, the 'Open in Gitpod' badge for a more expansive devcontainer experience.
-
Install the recommend extensions when prompted unless you have set preferences here.
-
Run
task install1 in the integrated terminal.

- If you have a preferred local development setup, clone the repo locally.
- Run
task venv.2 - Run
source .venv/bin/activate.3 - Run
task install.1 - Run
exec $SHELL4
Once your project is set up, use the following steps to get the project ready for whatever you'd like to do with it.
- Run
dbt seedto load the sample data into your raw schema. - Delete the
jaffle-datadirectory now that the raw data is loaded into the warehouse.
- If you'd like to use pre-commit, run
pre-commit installin your virtual environment or devcontainer, after thetask installstep.
Footnotes
-
This will install the dbt Cloud CLI [currently in beta] as well as the python packages necessary for running MetricFlow queries, linting your code, and other tasks. ↩ ↩2
-
This will create a virtual environment called
.venv. ↩ -
This will activate the virtual environment you just created. It's a long story, but because
taskruns commands in a subshell, we need to activate the virtual environment in the main shell manually so we can't put this in a task, sorry! ↩ -
This will reload your shell and ensure the new dependencies are available. ↩
-
This will run a
dbt seedthenmv jaffle-data jaffle-data-loaded, moving the sample data out of theseed-pathnow that it's loaded into your raw schema. The raw schema is meant to be accessed by all developers and production jobs as a raw database would, so once you'vedbt seed'd it, you don't need it again, but we'll keep it around in thejaffle-data-loadedfolder just in case. Should you ever need to load it again just ensure you've dropped the raw schema andmv jaffle-data-loaded jaffle-dataand thendbt seedagain. ↩