###POT: Natural Language Search
Build Status

High Level Arch Diagram
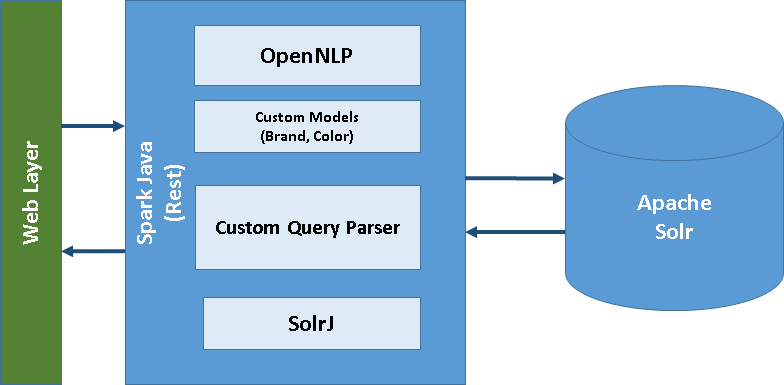
Sequence Diagram

###Creating Custom Model: Sample code is available in CreateBrandModel.java or CreateNERModel.java file
We need to provide the initial set of files with sentences ,known entities and blacklisted entities and then run below in Java code. The model builder library is available along with OpenNLP Libraries.
- Existing Models : http://opennlp.sourceforge.net/models-1.5/
- Model Creation Library : https://svn.apache.org/repos/asf/opennlp/addons/
DefaultModelBuilderUtil.generateModel(sentences, knownEntities,
blacklistedentities, theModel, annotatedSentences, "brand", 3);
###Training the Model:
Command to train the model file.
$ opennlp TokenNameFinderTrainer -model en-ner-money.bin -lang en -data en-ner-money.train -encoding UTF-8
Evaluation tool
$ opennlp TokenNameFinderEvaluator -model en-ner-money.bin -lang en -data en-ner-money.test -encoding UTF-8
Precision: 0.8005071889818507
Recall: 0.7450581122145297
F-Measure: 0.7717879983140168
Sample Training Data (file - en-ner-money.train)
Camera under <START:money> 20$ <END>
Camera under <START:money> $20 <END>
Watch above <START:money> $200 <END>
Watch above <START:money> 200$ <END>
T-Shirts less than <START:money> $30 <END>
T-Shirts less than <START:money> 30$ <END>
toys priced more than <START:money> 70$ <END>
toys priced more than <START:money> $70 <END>
###Custom Query Parser: A) As plugin
- Create a lib folder under solr/nls/solr
- Copy (custom code) opennlp-example-1.0-jar-with-dependencies under it
- Add the lib in classpath
<!-- adding custom jar for q parser plugin -->
<lib dir="../lib" regex=".*\.jar" />
- Add an entry for the custom parser
<queryParser name="customqparser" class="com.sagar.solr.custom.CustomQueryParserPlugin" />
Sample queries for testing
- http://localhost:8983/solr/nls/browse
- http://localhost:8983/solr/nls/select?q={!customqparser}entertainment
- http://localhost:8983/solr/nls/select?q={!customqparser}iPOD%20touch&fq=P_Color:pink&fl=*,score
- http://localhost:8983/solr/nls/select?q={!customqparser}blue%20sweater&fq=P_OfferPrice:[0%20TO%2010]
- http://localhost:8983/solr/nls/select?q={!customqparser}pink%20sweater&fq=P_OfferPrice:[40+TO+50]
B) At client side
User SolrCustomSearcher for client side implementation of NLP. It is been integrated with the web app as well. You can start ClientApp application and hit the http://localhost:4777/index.html for testing from web.
There are bunch of Junits are included in the code for testing each individual functions at different step.
###Running the webclient The webclient is made in angular js framework is deployed on spark java.
To start the webclient : Run the digicom.pot.solrnlp.web.ClientApp java (it will bring up the client which can be access over http://localhost:4777/index.html URL)
You also need to bring up the solr instance by running the command
<Solr Installed Dir>/nls> java -jar start.jar
###Screen shot of the webclient
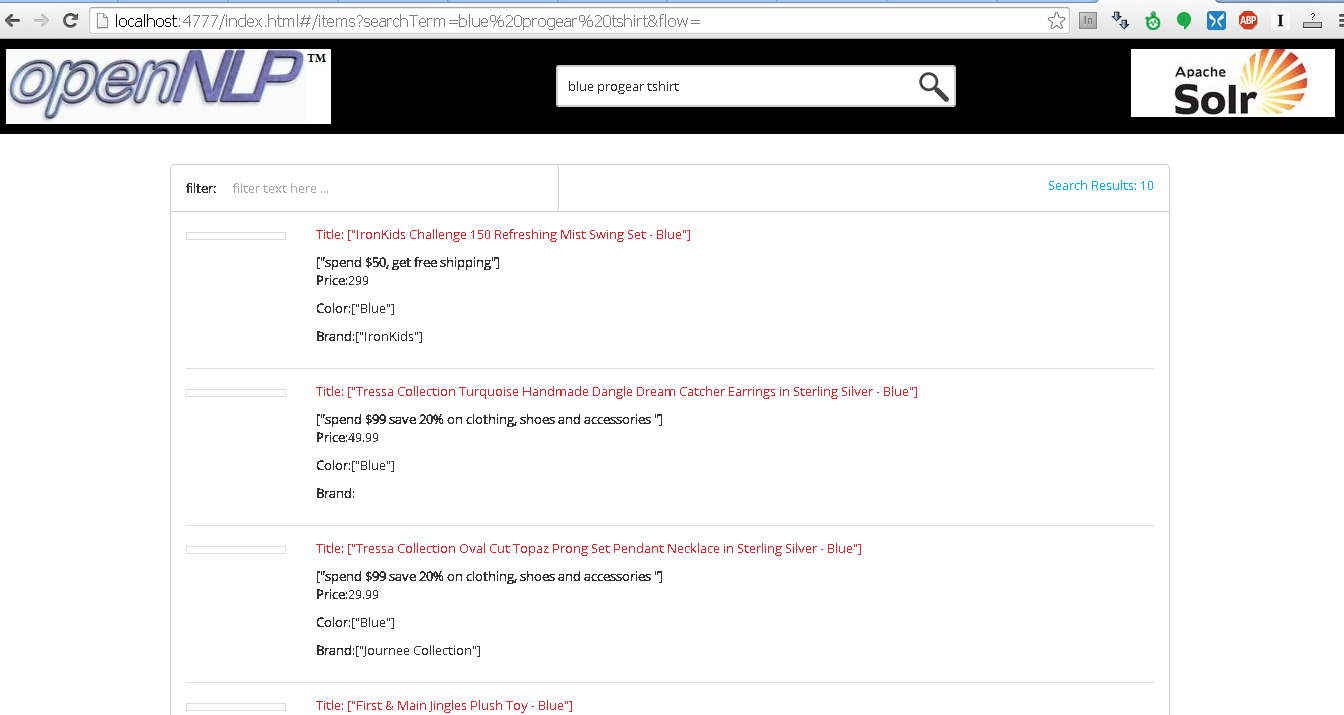
###Tech Stack Used:
- Apache Solr ( for the search engine and document indexing )
- OpenNLP ( for language processing and creating custom models )
- Spark Java ( for exposing the web interface )
- AngularJS (for lightweight UI to run the application)
- Download and extract Apache Solr from Mirror.
- cp -r example nls [create a copy of examples]
- mv nls/solr/collection1/ nls/solr/nls
- cp file core.properties and schema.xml to respective folder from github.
- Start and Verify the application :
cd nls
java -jar start.jar
http://localhost:8983/solr/#/nls
http://localhost:8983/solr/#/nls/query
###Data Indexing
- Copy SolrItemPayLoad.xml to \solr\nls\exampledocs folder and extract it
- Execute
java -Durl=http://localhost:8983/solr/nls/update -jar post.jar SolrItemPayLoad.xml
- Verify the rows index
http://localhost:8983/solr/nls/browse -
###Solr Installation (with NLP for index/query time usage):
- (http://wiki.apache.org/solr/OpenNLP)
- Download/SVN Checkout Latest Source of Apache SOLR (http://archive.apache.org/dist/lucene/solr/4.8.0/)
- Download OpenNLP Analysis capabilities as a module Patch (https://issues.apache.org/jira/browse/LUCENE-2899)
patch -p 0 -i <path to patch> [--dry-run] (to check the changes)
patch -p 0 < LUCENE-2899.patch (Patch using *NIX patch or SVN patch command)
- Do 'ant compile' in SOLR home folder
- CD solr/contrib/opennlp/src/test-files/training & run 'bin/trainall.sh'
- Download the OpenNLP distribution from http://opennlp.apache.org/cgi-bin/download.cgi
- Unpack this and copy the jar files from lib/ to solr/contrib/opennlp/lib
- Download the real models for OpenNLP project to your solr/cores/collection/conf/opennlp directory.
- The English-language models start with 'en'. (http://opennlp.sourceforge.net/models-1.5/)
- Go to trunk-dir/solr and run 'ant test-contrib'
- Add one NLP Field Type with NLP tokenizer and NLP filter in the schema.xml.
<fieldType name="text_opennlp_pos" class="solr.TextField" positionIncrementGap="100">
<analyzer>
<tokenizer class="solr.OpenNLPTokenizerFactory"
tokenizerModel="opennlp/en-token.bin"
/>
<filter class="solr.OpenNLPFilterFactory"
posTaggerModel="opennlp/en-pos-maxent.bin"
/>
</analyzer>
</fieldType>
Check if following config is there in solr.config file, if not add it
<lib dir="../../../contrib/opennlp/lib" regex=".*\.jar" />
<lib dir="../../../dist/" regex="solr-opennlp-\d.*\.jar" />
<lib dir="../../../contrib/opennlp/lucene-libs" regex=".*\.jar" />
###References:
- http://www.searchbox.com/named-entity-recognition-ner-in-solr/
- http://wiki.apache.org/solr/SolrUIMA
- http://johnmiedema.com/?p=744
- https://svn.apache.org/repos/asf/opennlp/addons/
- http://lucene.472066.n3.nabble.com/Adding-filter-in-custom-query-parser-td4162044.html
- https://code.google.com/p/spark-java/