UYRW SWAT+ project: NWP integration
Herbie-based python scripts for handling weather forecast data.
see: https://github.com/blaylockbk/Herbie
This repo is my first attempt at integrating numerical weather prediction (NWP) forecasts from the National Weather Service (NWS) into the SWAT+ workflow.
NWS data are mostly in GRIB2 format, which is a bit difficult to work with in Python/R. The scripts in this directory are for downloading the appropriate GRIBs and converting them to a more usable format.
For now I am working through an example with the National Blended Model (NBM). These are ensemble forecasts (the combination of multiple independent models) at relatively high resolution (3km). They are released hourly, and extend up to 10 days into the future (forecast hours 1-264).
There are a few other NWS products in the Big Data Program that we should look at after this (HRRR, RAP, GFS, etc.)
The herbie_nbm_test.py script builds an archive of the 1-hour forecasts for a subset of 5 variables (needed for SWAT+), saving the results as a netCDF file with three coordinates (x, y, and time). For now I just show a short example with two dates but we can access data from the AWS bucket going back to Jan 1, 2021.
This is a work in progress, and the next thing to add is a function that appends to this file the latest 2-260 hour forecasts (extending the time dimension). We could use this function in an automated script a daily schedule to maintain an up-to-date record of historical forecasts + future forecasts up to 10 days.
Once the data are in this format (time dimension defined appropriately) it's very easy for me to extract a time series that can be passed on to SWAT+. It should also be quite easy to save a ZARR version, once you've decided how best to chunk things.
I'm using the Herbie package to download and manage the GRIB files, which it does very well for the most part. It organizes the GRIB files sensibly and checks for local copies before attempting a download.
However there are problems currently with Herbie that prevent me using it to open the NBM data. I think this is related to a Herbie dependency, cfgrib, running into an unexpected variable naming scheme.
helpers.py includes functions for processing GRIB data downloaded by Herbie. It also loads the files in a different way, preserving more of their attributes. This is working well with NBM right now and I think it will be useful more generally with any kind of GRIB
Different forecast predictions hours are released at different times throughout the day. This can get a bit confusing, so I wrote a script to compile a table of all available forecasts by date/time of publication. See list_available_nbm_forecasts.py.
Here is an example of what this looks like over a typical two-day window (blue indicates the forecast time is available for download):
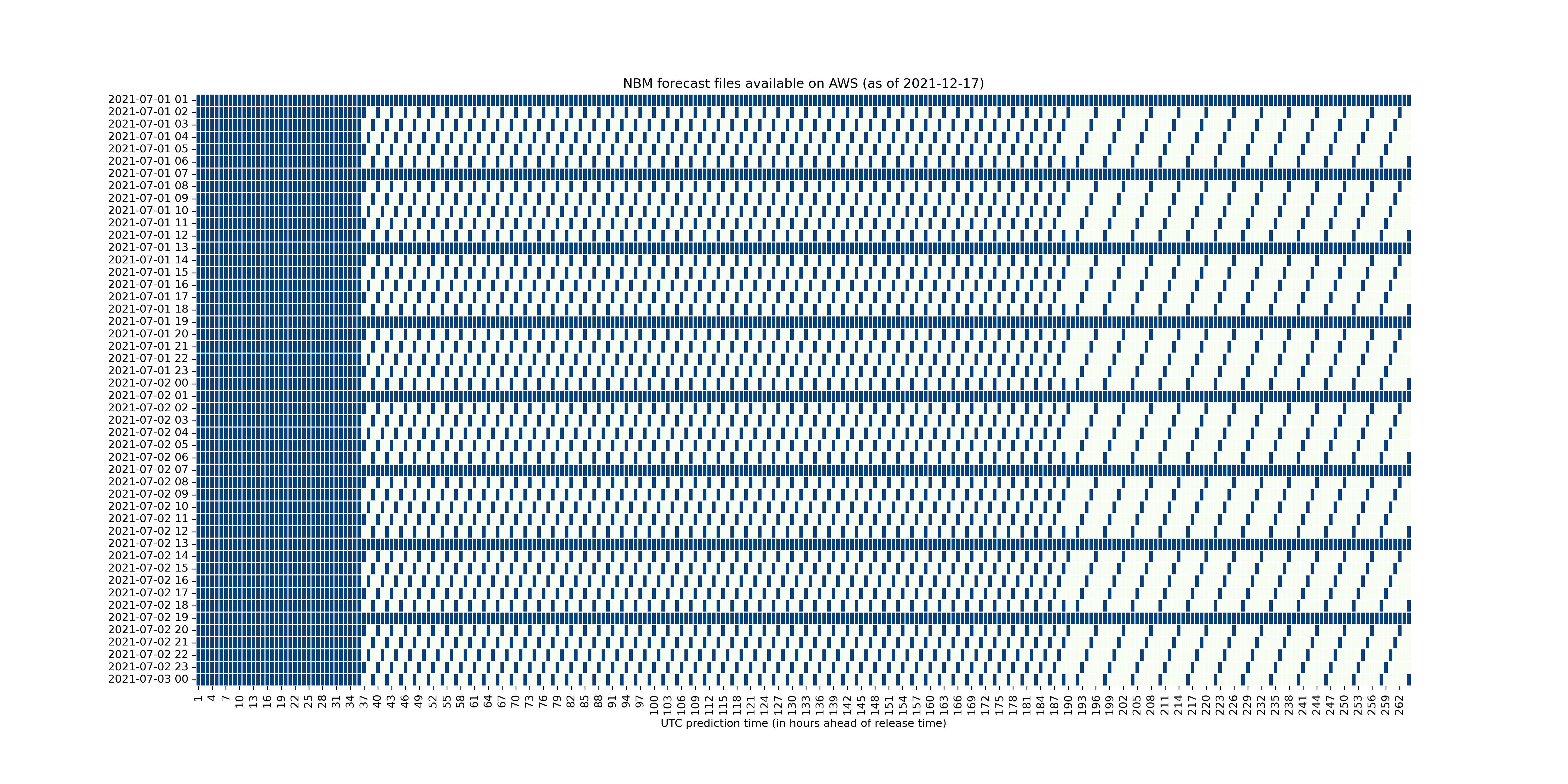
Each hour a new batch of forecast files is released, comprising hourly predictions for at least the next 36 hours (the solid block of blue on the left). Every 6 hours (starting at 1am UTC), a full 264 hour long (11 day) batch of hourly predictions are generated (horizontal bands of blue). At the other hours of the day, the forecast intervals become more sparse beyond the 36 hour point (every 3 hours, then every 6 hours).
-
GRIB2 files are tricky. They include a massive amount of attributes, but no layer names, which makes it difficult to refer to specific variables. Users need to do some homework to figure out what variables are available and how they are described in the files.
-
GRIB2 file metadata is all coded, requiring external libraries to decode. And no central authority maintaining/distributing these tables! I think this is why support for GRIBs is so bad in python and R. Most of the advice I'm seeing is along the lines of "step 1: convert the grib to netcdf". My implementation uses two python libraries to get the files loaded properly into xarray, but it may be better to just use an external utility like degrib or wgrib2 to convert the files before loading them in python.
-
Ultimately we want daily data, whereas forecast data like this come in sub-daily intervals. Often there will be several versions of a variable corresponding to different temporal levels (and also vertical heights). It's important to understand why the data are parcelled out like that, and which variables we need to reconstruct a daily time series. Again, some homework is needed to figure this stuff out because it's unlikely to be clear from the file on its own.