ScraXBRL
SEC Edgar Scraper and XBRL Parser/Renderer
To use:
- Install requirements from requirements.txt
- Change settings.py to fit your needs. Raw scraped data will be stored in data/raw_data and
extracted data will be stored in data/extracted_data by default. - Run python main.py. This will begin the scrape and extract process.
- To view data in terminal (data must have already been scraped from the SEC EDGAR website):
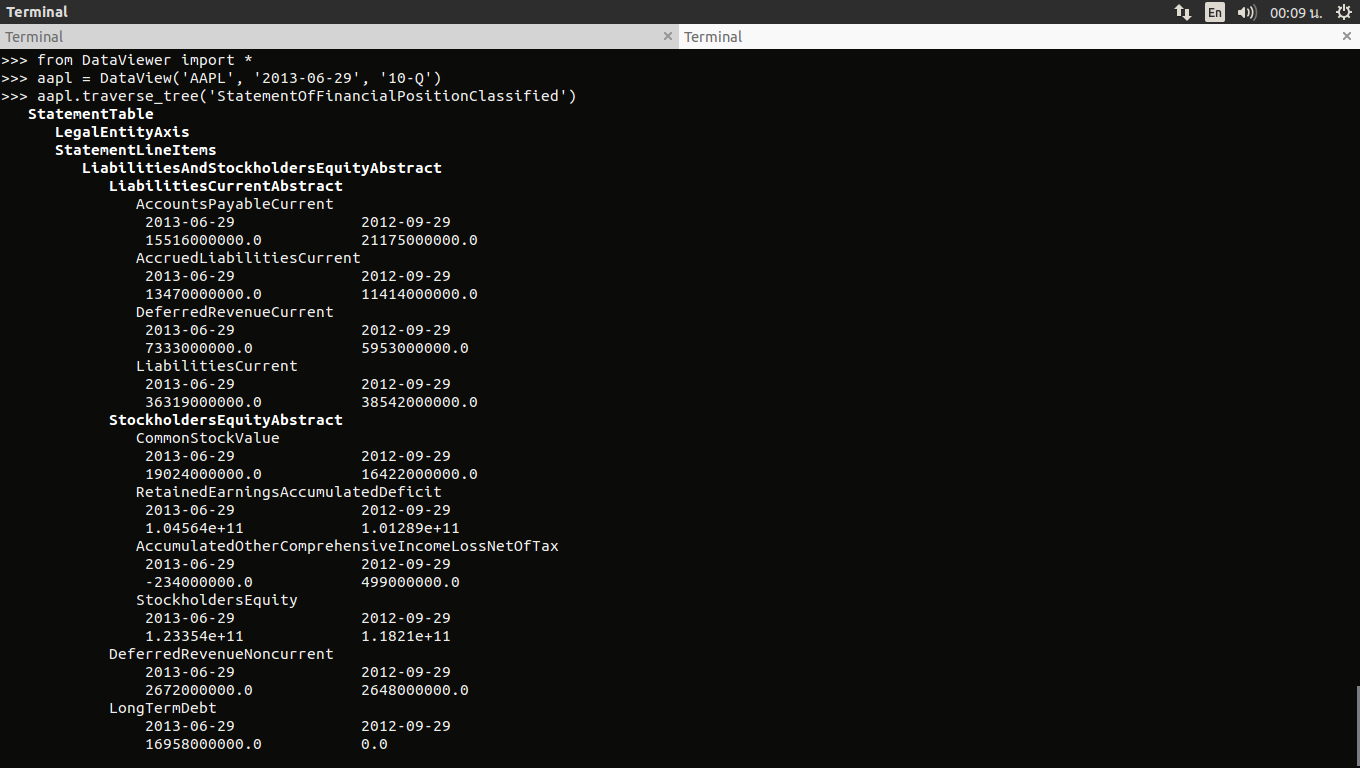 Data is stored in a pickle file. To use DataViewer, create instance of DataView class and enter
Data is stored in a pickle file. To use DataViewer, create instance of DataView class and enter
the necessary parameters (ticker_symbol, filing_date, filing_type). The data will then be stored in
[instance name].data, and it is an OrderedDict.