使用 CNN 进行中文 NLP 分类
我的知乎专栏:机器养成攻略
- 生成字典
- 模型准备
- 构建网络
- 训练样本
- 测试
- 结果分析
- 反思总结
将训练数据的新闻样本逐条分词;并将分好的词打包集合,等待下一步处理。
- 此处假想数据包特别大,采用 fileinput 模块读取文件。fileinput 只在内存中加载当前行,故节省内存。 相关拓展:python 读取文件的正确方式
- 使用清华大学的 THULAC 进行中文分词。官网及安装方式在这:THULAC:一个高效的中文词法分析工具包
lex = Counter()
with fileinput.input(files=TRAIN_DATA_DIC, openhook=fileinput.hook_encoded('UTF-8')) as f:
for line in f:
count += 1
if count % 500 == 0:
print('处理进度:', count / total_line_num * 100, '%')
words = thu1.cut(line[3:], True).split(' ')
lex.update(words)优化词包,去掉高频词和低频词。
高频词包括停用词「的」、「地」等无意义,还包括「今天」这样的词,没有让机器学习的必要。低频词因出现频率太低,权重值得不到充分优化,影响机器判断。去掉这些词后,词包大大缩小,学习速度也会更快 。
# WORD_FREQUENCY_LOW 和 WORD_FREQUENCY_HIGH 分别是低频词和高频词的阈值,本例使用了1000和3500
for word in lex:
if WORD_FREQUENCY_LOW < lex[word] < WORD_FREQUENCY_HIGH:
dic.append(word)第一次处理时,可以把词包输出,按频率排序后自行判断阈值。
with open(CHICK_DICT_DIC, "w", encoding='utf-8') as f:
for word in lex:
f.write(word + ',' + str(lex[word]) + '\n')把词包保存在 list 中,就得到了字典。
- 因为字典生成起来并不快,故可以将其存在文件中,下次训练时直接取用。
- 保存和读取字典,这里使用了 python 的 pickle 包
# 保存文件
with open(DICTIONARY_DIC, 'wb') as f:
pickle.dump(dic, f)
# 读取文件
if os.path.isfile(DICTIONARY_DIC):
with open(DICTIONARY_DIC, "rb") as f:
dic = pickle.load(f)整体上,使用 CNN + Full NN + softmax 的结构。
其中 CNN 在处理文本时,我们将每个样本的每个词都看做是词向量,这样,1 维的句子就拓展成了 2 维。

图中为 6 维词向量示例
上图中的黄色部分,就是神经网络的输入。
关于词向量,我有一个通俗的比方。
用词向量表示词,就是把字典中的每个词,都拓展成 n 维。
可以这样通俗理解: 将每个词表示为 n 维,其实意味着这 n 维中的每个维,都单独表示了词的一个属性, 例如第 0 维代表动名词性,第 1 维代表男女词性, 第 2 维代表褒贬词性…… 这些各不相关的属性两两正交,便可以,以给不同的维度赋予不同的权重的形式,表示出每个词。
假如我们给词设置三个维度,[冷暖、方圆、大小] 那么太阳就应该表示为 [9999,0,9999999] 苹果 [4,0,5] 色子 [-2,6,2] 如果又来了一个铅球,我们衡量了一下各个权重,认为铅球也应该使用 [4,0,5] 表示,但是这就跟苹果一样了。为什么呢,这代表我们的维度设置小了。此时就考虑到,本应该使用 4 个维度来表示词,少了个「重量」。
实际上,机器学习训练出的词向量并不一定是与人类逻辑能够理解的维度一一对应,更常见的情况下,每个维度是代表上下文词的情况,但总体是这个意思。
应该设置多少维,这是我们需要调试的超参数。每个词在各个维上应该填充多大的数值,这是机器自动学习的。
词向量可以自行在样本训练中学习,也可以使用前人预训练好的。Google、Facebook 都提供了优质的英文词向量。中文目前成熟的不多,我这里采用了北京师范大学中文信息处理研究所与**人民大学 DBIIR 实验室的研究者开源的 Chinese Word Vectors (官方 Github 在这),选用了基于百度百科预料库,使用 SGNS 方法训练的 Word 词向量。
设计词向量维度时,一般不建议设置太小,常见的有128维、256维。前人使用大语料预训练好的词向量以300维居多。我在本题目中,使用不同的维度做了个测试。


32 维的表现始终不如 300 维,但是都和使用预训练好的词向量差距悬殊。因此,在做 NLP 任务中,尽量采用预训练好的词向量,任务质量会提高很多。
通过查找的方式,用预训练好的词向量一一替换掉我们自己生成的词向量。
def get_word2vec(dic, # 之前归纳好的字典
pha, # 词向量
file): # 已预训练好的词向量文件地址
"""采用预训练好的部分词向量。仅使用部分,是为了节省内存。
1. 遍历已训练好的词向量文件
2. 替换掉本例词典中存在词的词向量
"""
print("正在加载预训练词向量……")
if os.path.isfile(file):
with fileinput.input(files=(WORD2VEC_DIC), openhook=fileinput.hook_encoded('UTF-8')) as f:
for line in f:
word_and_vec = line.split(' ')
word = word_and_vec[0]
vec = word_and_vec[1:301]
if word in dic:
pha[DICTIONARY.index(word)] = vec
print("预训练词向量加载完毕。")因为训练数据包很大,无法全部加载进内存。因此需要考虑如何随机抽样,以及何时预处理数据。本例的方式是,在向神经网络中传输数据时,从数据包中抽取需要条数的样本 ,并做预处理。同时,为保证抽样概率一致,使用蓄水池采样算法。相关拓展:蓄水池采样算法(Reservoir Sampling)
def get_some_date(file_name='input/cnews.train.txt',
num=100):
"""取出数据包中的n条数据,处理成需要的格式,并返回。
1. 使用蓄水池采样算法,取出数据包中的 num 条数据。
2. 分词
3. 参照字典把输入转换成序列,把输出转换成 One-hot 格式
4. 输入和输出分别放入 x_batch 和 y_batch 中返回
"""
x_batch = []
y_batch = []
getlines = []
i = 0
# 此种读取算法,可保存每行被取到的概率相同
with fileinput.input(files=file_name, openhook=fileinput.hook_encoded('UTF-8')) as f:
# fileinput 节省内存
for line in f:
i += 1
if len(getlines) <= num:
getlines.append(line)
else:
random_num = random.randint(0, i)
if random_num <= num:
random_line = random.randint(0, num)
getlines[random_line] = line
# 将数据处理成期望的格式
for line in getlines:
label = str(line.split('\t')[0])
text = str(line.split('\t')[1:])
# 将 label 转换成 One-hot 格式
label_transl = np.zeros(len(CLASSES))
for i in range(len(CLASSES)):
if CLASSES[i] == label:
label_transl[i] = 1
# 将输入转换成序列 list
text_separate = thu1.cut(text, True).split(' ')
text_transl = np.zeros(SEQUENCE_LENGTH)
for index, word in enumerate(text_separate[:SEQUENCE_LENGTH]):
if word in DICTIONARY:
text_transl[index] = DICTIONARY.index(word)
x_batch.append(text_transl)
y_batch.append(label_transl)
return [x_batch, y_batch]使用 CNN 处理 NLP ,有一个问题绕不过:CNN 后接全连接层,由于全连接层输入尺寸固定,即要求 CNN 输出尺寸不能变,而 CNN 的输出尺寸又依赖于样本输入。以前 CNN 处理图片时图片可以放缩,任何样本都能在放缩后达到同等尺寸输入进 CNN,从而保证 CNN 输出尺寸的固定。但 CNN 处理自然语言则不然,不管是按句、按段或是按篇送入 CNN,除非截断 / 补齐,否则传统 CNN 无法保证每次输出都是同等尺寸。
Yoon Kim(其论文《Convolutional Neural Networks for Sentence Classification》原文/译文)将 CNN 稍做变化,巧妙的解决了这个问题。
CNN 在池化层上采用 1-max pooling,这样一来,不管输入有多长,经过池化层时,都将变为 [1,1] 。同时,为保证特征提取的多样,网络还使用大小不同的卷积核分别卷积样本,并都经过 1-max pooling ,各生成一个 [1,1] ,最后将这些 [1,1] 按列组合为 [n,1] ,输入给全连接层。

CNN 处理 NLP 模型(CNN 部分)
由此一来,全连接层的输入尺寸不再绑定于样本,而是和构建的网络结构有关,CNN 需保持同等尺寸输出的问题得到解决。
上篇提到将词向量引入后,样本数据中每个完整行都是该词的全部词向量。

词向量构成的输入
刚才模型中的关键点还有一个没提,就是 “使用大小不同的卷积核分别卷积样本” 中的 “不同的卷积核”。
CNN 处理图片时,卷积核从左到右、从上到下顺次滚动。但当把这种方式作用于 NLP,便使得在从左向右的滚动中,词向量被截断处理,这仅从逻辑上就会带来困惑,当然论文实验也证明了这样不利于机器学习。
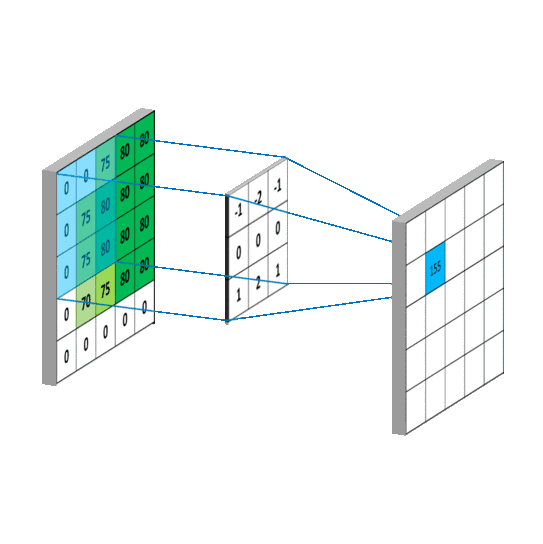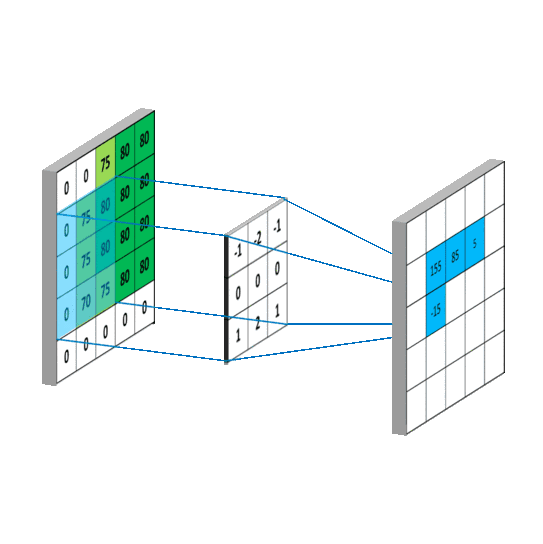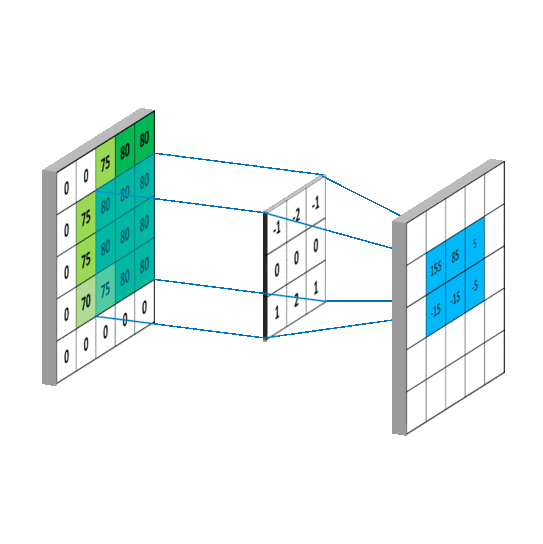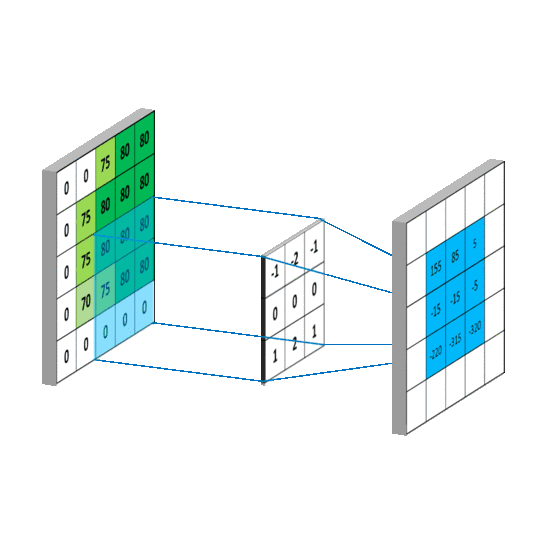
CNN 处理图片(卷积部分)图片来自 白雪峰《机器学习算法与自然语言处理》
Yoon Kim 将卷积核做了修改,令卷积核列数与词向量列数保持一致,这样一来,从左向右的卷积过程就不存在了,每次卷积都变成了整行卷积,从而保证了词向量不会被截断。另外卷积核的行数经过实验分别取 2、3、4,代表着每次卷积时考虑到之后的 2、3、4 行 / 个词
WORD2VEC_DIC = 'input/sgns.target.word-word.dynwin5.thr10.neg5.dim300.iter5' # Chinese Word Vectors提供的预训练词向量
DICTIONARY = pretreat.pretreatment_date() # 读取利用train数据包归纳出的字典
CLASSES = ['体育', '娱乐', '家居', '房产', '教育', '时尚', '时政', '游戏', '科技', '财经'] # 所有输出
SEQUENCE_LENGTH = 50 # 句子最长含词量。为了训练速度,超过后,多余的词截断
INPUT_SIZE = SEQUENCE_LENGTH # 神经网络输入尺寸
OUTPUT_SIZE = len(CLASSES) # 神经网络输出尺寸
HIDDEN_DIM = 512 # 隐藏层神经元数
EMBEDDING_SIZE = 300 # 每个词的词向量维度
NUM_FILTERS = 256 # 每个核卷积后输出的维度
BATCH_SIZE = 50 # 每批次样本数量
FILTERS = [2, 3, 4] # 卷积核尺寸
USE_L2 = False # 是否启用L2正则化
L2_LAMBDA = 0
x = tf.placeholder(tf.int32, [None, INPUT_SIZE])
y_ = tf.placeholder(tf.float32, [None, OUTPUT_SIZE])
dropout_keep_prob = tf.placeholder(tf.float32)
thu1 = thulac.thulac(seg_only=True) # 只分词,不需要标注词性
# 1. 生成[词向量个数, 300维]的随机均匀分布
word2vec_random = np.random.uniform(-1.0, 1.0, [len(DICTIONARY), EMBEDDING_SIZE])
# 2. 使用预训练好的词向量替换掉随机生成的分布
get_word2vec(DICTIONARY, word2vec_random, WORD2VEC_DIC)
# 3. 使用此分布创建Tensor对象
phalanx = tf.Variable(initial_value=word2vec_random, dtype=tf.float32)
embedded_chars = tf.nn.embedding_lookup(phalanx, x)
embedded_expanded = tf.expand_dims(embedded_chars, -1)
pooled_out = []
for filter_window in FILTERS:
# conv2d
filter = tf.Variable(tf.random_normal([filter_window, EMBEDDING_SIZE, 1, NUM_FILTERS], stddev=0.1))
conv = tf.nn.conv2d(embedded_expanded,
filter,
strides=[1, 1, 1, 1],
padding="VALID")
b1 = tf.Variable(tf.constant(0.1, shape=[NUM_FILTERS]))
l = tf.nn.relu(tf.nn.bias_add(conv, b1))
# maxpooling
pooled = tf.nn.max_pool(
l,
ksize=[1, INPUT_SIZE-filter_window+1, 1, 1],
strides=[1, 1, 1, 1],
padding='VALID'
)
pooled_out.append(pooled)
# 拼合3个pooling的结果,准备输出给全连接层
pooled_out_sum = tf.concat( pooled_out, 3)
cnn_out = tf.reshape(pooled_out_sum, [-1, NUM_FILTERS*len(FILTERS)])这一部分为普通的全连接层写法。只是为了防止过拟合,增加了 dropout 层和 L2 正则化。
# dropout
cnn_out = tf.nn.dropout(cnn_out, dropout_keep_prob)
# 添加3个全连接层
w1 = tf.get_variable('w1', shape=[NUM_FILTERS*len(FILTERS), HIDDEN_DIM],
initializer=tf.contrib.layers.xavier_initializer())
if USE_L2:
tf.add_to_collection('losses', tf.contrib.layers.l2_regularizer(L2_LAMBDA)(w1))
b1 = tf.Variable(tf.constant(0.1, shape=[HIDDEN_DIM]))
wb1 = tf.matmul(cnn_out, w1)+b1
l1 = tf.nn.relu(wb1)
w2 = tf.get_variable('w2', shape=[HIDDEN_DIM, HIDDEN_DIM],
initializer=tf.contrib.layers.xavier_initializer())
if USE_L2:
tf.add_to_collection('losses', tf.contrib.layers.l2_regularizer(L2_LAMBDA)(w2))
b2 = tf.Variable(tf.constant(0.1, shape=[HIDDEN_DIM]))
wb2 = tf.matmul(l1, w2) + b2
l2 = tf.nn.relu(wb2)
w3 = tf.get_variable('w3', shape=[HIDDEN_DIM, OUTPUT_SIZE],
initializer=tf.contrib.layers.xavier_initializer())
if USE_L2:
tf.add_to_collection('losses', tf.contrib.layers.l2_regularizer(L2_LAMBDA)(w3))
b3 = tf.Variable(tf.constant(0.1, shape=[OUTPUT_SIZE]))
y = tf.matmul(l2, w3) + b3因为是多分类问题,故而使用 softmax 求 loss ,使用 Adam 梯度下降。
loss = tf.reduce_mean(tf.nn.softmax_cross_entropy_with_logits(labels=y_, logits=y))
tf.add_to_collection('losses', loss)
total_loss = tf.add_n(tf.get_collection('losses'))
optimizer = tf.train.AdamOptimizer(1e-3).minimize(total_loss)以及通过比对求正确率。
correct = tf.equal(tf.argmax(y, 1), tf.argmax(y_, 1))
acc = tf.reduce_mean(tf.cast(correct, tf.float32))将测试集训练过程中的损失和正确率输出至文本,并每隔一段时间使用验证集验证,若在验证集表现不错,则保存模型,否则继续训练。
同时,当检测到验证集正确率久不提高时,则证明到了本模型的瓶颈期,停止训练。
import model
SAVER_DIC = 'output/model.ckpt' # 保存学习到的参数
TRAIN_DIC = 'input/cnews.train.txt' # 训练集存放地址
VALID_DIC = 'input/cnews.val.txt' # 验证集存放地址
TRAIN_LOG = 'output/log_train.txt' # 保存loss和正确率
VALID_LOG = 'output/log_valid.txt' # 保存loss和正确率
CLASSES = model.CLASSES # 输出的所有类别
TOTAL_ITERATIONS = 20000 # 总迭代次数
VALID_ITERATION = 100 # 每多少轮验证一次
DELAY_NUM = 20 # 经过多少次验证后正确率还不提升,则停止
model.USE_L2 = True # 启用L2正则化
model.L2_LAMBDA = 0.04 # 正则化参数
def train_network(file = 'input/cnews.train.txt'):
"""训练部分
"""
acc_value = 0.0 # 验证集正确率
iterations = 0 # 迭代次数
loss, optimizer, acc = model.create_cnn()
# 用来保存进度
saver = tf.train.Saver()
init = tf.global_variables_initializer()
sess = tf.Session()
sess.run(init)
# 若有上次的进度,则加载
if os.path.isfile(SAVER_DIC+'.index'):
saver.restore(sess, SAVER_DIC)
for i in range(TOTAL_ITERATIONS):
view_bar('训练进度:', i, TOTAL_ITERATIONS)
x_data, y_data = model.get_some_date(file, model.BATCH_SIZE) # 取批次数据
feed_dict = {model.x: x_data, model.y_: y_data, model.dropout_keep_prob: 0.5}
_, loss_test_value, acc_test_value = sess.run([optimizer, loss, acc], feed_dict=feed_dict)
# 输出 train 的 loss 和正确率
with open(TRAIN_LOG, 'a') as f:
f.write(str(i) + ',' + str(loss_test_value) + ',' + str(acc_test_value) + '\n')
# 在验证集中测试
if i%VALID_ITERATION == 0:
model.USE_L2 = False # 关闭L2正则化
x_valid_data, y_valid_data = model.get_some_date(VALID_DIC, model.BATCH_SIZE)
feed_dict = {model.x: x_valid_data, model.y_: y_valid_data, model.dropout_keep_prob: 1}
_, loss_valid_value, acc_valid_value = sess.run([optimizer, loss, acc], feed_dict=feed_dict)
if acc_valid_value > acc_value:
acc_value = acc_valid_value
saver.save(sess, SAVER_DIC)
iterations = 0
# 输出 valid的 loss 和正确率
with open(VALID_LOG, 'a') as f:
f.write(str(i) + ',' + str(loss_valid_value) + ',' + str(acc_valid_value) + '\n')
else:
iterations += 1
# 正确率久不提升,则停止
if iterations >= DELAY_NUM:
break
model.USE_L2 = True # 启用L2正则化import model
SAVER_DIC = 'output/model.ckpt' # 保存学习到的参数
TEST_LOG = 'output/log_test.txt' # 保存loss和正确率
TEST_DIC = 'input/cnews.test.txt' # 测试数据存放的地址
CLASSES = model.CLASSES # 输出的所有类别
ITERATIONS = 100 # 迭代次数
model.BATCH_SIZE = 50 # 每批次数量
SEQUENCE_LENGTH = 50 # 句子最长含词量。为了训练速度,超过后,多余的词截断
INPUT_SIZE = SEQUENCE_LENGTH # 神经网络输入尺寸
OUTPUT_SIZE = len(CLASSES) # 神经网络输出尺寸
def test(file='input/cnews.test.txt'):
"""测试部分
"""
loss, optimizer, acc = model.create_cnn()
# 用来读取参数
saver = tf.train.Saver()
init = tf.global_variables_initializer()
sess = tf.Session()
sess.run(init)
# 若进度存在,则读取学习到的参数
if os.path.isfile(SAVER_DIC + '.index'):
saver.restore(sess, SAVER_DIC)
for i in range(ITERATIONS):
view_bar('测试进度:', i, ITERATIONS)
x_test_data, y_test_data = model.get_some_date(file, model.BATCH_SIZE)
feed_dict = {model.x: x_test_data, model.y_: y_test_data, model.dropout_keep_prob: 1}
loss_test_value, acc_test_value = sess.run([loss, acc], feed_dict=feed_dict)
# 输出 test loss 和正确率
with open(TEST_LOG, 'a') as f:
f.write(str(i) + ',' + str(loss_test_value) + ',' + str(acc_test_value) + '\n')经过 5000 次训练,在测试集上的表现如下:

- 由于启用了 L2 正则,初期 loss 下降更平缓了。
- 训练至第 600 次左右时,训练集正确率抬升至 75%,训练速度明显放缓。
- 训练至第 3000 次左右,此后 loss 以极慢的速度下降, 正确率几乎不再提升。 摘取部分训练数据,整理如下:

在几个记录点分别使用验证集和测试集测试正确率,情况如下:

在训练过程中,程序每经过 100 轮训练,就使用验证集验证 1 次,若验证结果比上一次验证正确率高,则保存训练进度。
记录显示,程序最后一次进度保存是在第 3000 轮时,当时验证集正确率为 86.27%,此后又经过长达 2000 轮的训练,验证结果再也没有提升,自动结束训练。最终拿测试集检测,正确率为 81.18%
本次使用 CNN 做 NLP 分类,在模型刚写完的一段时间,训练集正确率始终封顶在 22%。调整全连接层数、隐藏层神经元数,效果并不明显;尝试修改词向量维度、卷积核数等超参数,也仅有微小提升。故判断原因可能有两个:
- 样本数太少
- 模型编程有问题 于是去掉 dropout,放在服务器上跑了一夜,试图让其出现过拟合。若过拟合,则证明问题源自样本过少。
一早起来,看到程序跑了 50000 次,正确率仅提升至 30%,断定编程有问题。梳理代码逻辑,并阅读网络上相关 CNN 处理 NLP 的理论文章后,找到了原因。原来 “词向量化的样本要预处理成什么样子” 这一步,我在理解上出了偏差。修正了这个问题后,正确率一下提高到了 60%。
接下来引入 thulac 预训练好的词向量,理论上正确率会有较大提升。这时笔记本提示内存不足,训练无法正常跑起来,于是做了些优化:边读边处理 thulac 词向量、样本含词量超过 50 个后截断。笔记本这才跑得起来。
跑了 1000 轮后,训练集正确率达到了 90%,测试集正确率仅为 71%,出现了过拟合。便引入 L2 正则,并不断拿验证集检测正确率,待正确率久不提升时 “早停”。
最初采用 THUCNews 提供的验证集,运行一段时间后发现验证集正确率似乎与测试集差距过大,倒是与训练集更接近,于是从测试集中抽取出一部分数据作为验证集,才使得验证集更能体现其价值。
目前达到的 81% 正确率仍有提高空间。由于输入样本采用抽取方式生成,肯定会有某一样本被多次抽取的情况。按本代码中每次抽取 50 个计算,训练 1000 次抽取的样本数已经和训练集总样本数相当了,况且训练到最后模型跑了 5000 次,重复抽取率 500%,因样本量不足导致的过拟合现象肯定是存在的。若要在仅此 5 万个样本量的基础再提升正确率,就要考虑:
- 更换预训练词向量
- 改用 RNN
欢迎讨论与指正。 我的知乎专栏:机器养成攻略