该项目是为了解决医疗行业中的病历文件信息抽取问题,主要包括病历文件的解析和信息抽取两个部分。

├── AI-病历文件提取.py # 前端展示
├── file_parsing.py # 文件解析
├── tempDir # 暂存文件夹
├── static
│ ├── ocr_files # 保存上传的文件
streamlit run AI-病历文件提取.py
- 前端展示地址:http://ip:8501
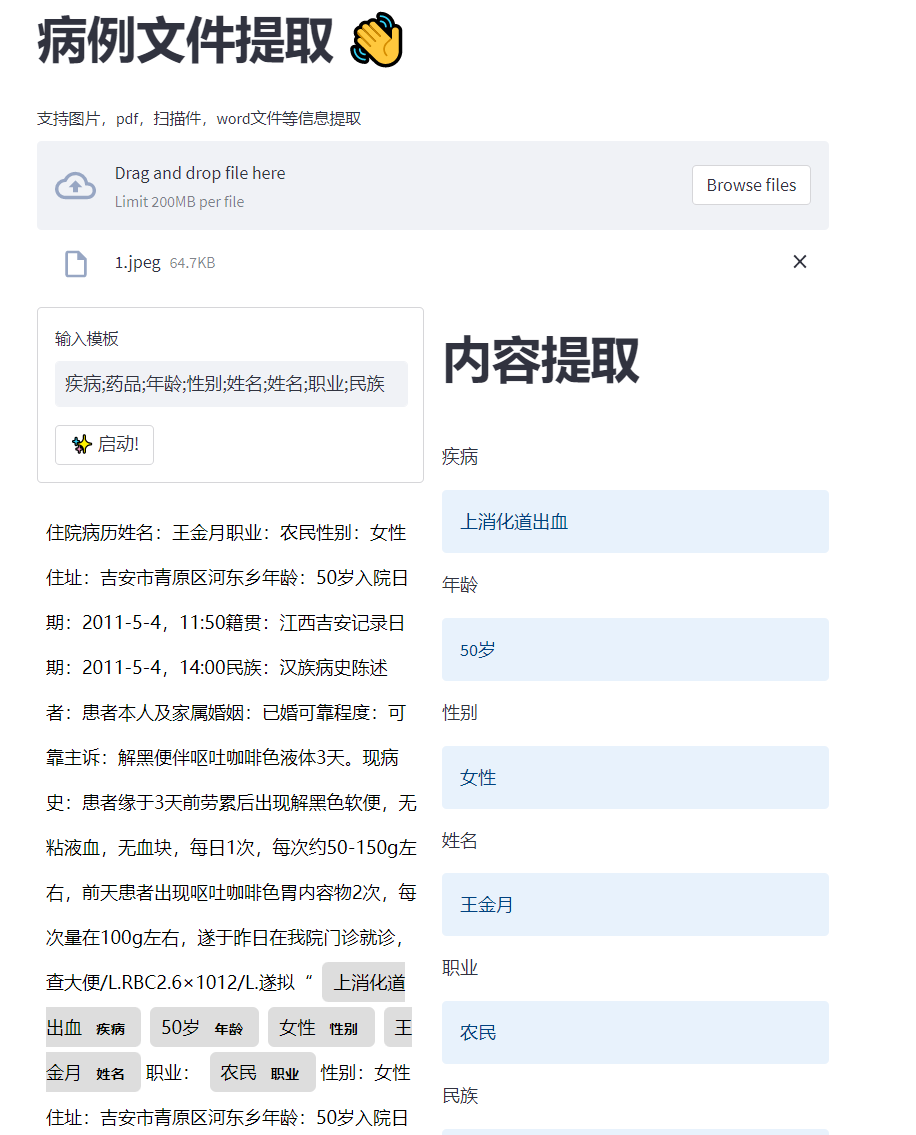
该项目主要是抽取病历文件中的一些关键信息。并将抽取的内容进行streamlit前端的展示。目前支持的文件类型:图片,pdf文件,word文件
Python
该项目是为了解决医疗行业中的病历文件信息抽取问题,主要包括病历文件的解析和信息抽取两个部分。
├── AI-病历文件提取.py # 前端展示
├── file_parsing.py # 文件解析
├── tempDir # 暂存文件夹
├── static
│ ├── ocr_files # 保存上传的文件
streamlit run AI-病历文件提取.py
