Generating Multiple-Length Summaries via Reinforcement Learning for Unsupervised Sentence Summarization
Official implementation of EMNLP'22 paper
Summarization shortens given texts while maintaining core contents of the texts, and unsupervised approaches have been studied to summarize texts without ground-truth summaries.
We devise an abstractive model by formulating the summarization task as a reinforcement learning without ground-truth summaries.

The proposed model (MSRP) substantially outperforms both abstractive and extractive models, yet frequently generating new words not contained in input texts.

- Python=3.8
- Pytorch=1.1
- pythonrouge
- transformers=4.1
- numpy
- wandb (for logging)
We uploaded the trained models in HuggingFace library so that you can easily evaluate the uploaded models. It will automatically download the trained model and evaluate it on the data.
- anonsubms/msrp_length
- anonsubms/msrp_ratio
- anonsubms/msrp_length_sb
- anonsubms/msrp_ratio_sb
[Example with 0-th GPU]
python evaulate.py anonsubms/msrp_length 0You can compute the metrics for the output summaries in Gigaword and DUC2004 datasets. Thus, you can evaulate your outputs with the provided evaulation code. The code assumes four output files in 8, 10, 13, 50% lengths (see the files in outputs/msrp/).
python evaulate_outputs.py outputs/msrp 0-
Modify a file of PyTorch (i.e., grad_mode.py) to flow the gradient while generating summaries.
- This process is required as default code does not allow gradient flow through generate function used to generate summaries.
- Highly recommended to make a virtual environment (e.g., Anaconda environment)
- The file (grad_mode.py) can be found in the library path
~/ANACONDA_PATH/envs/ENV_NAME/lib/python3.6/site-packages/torch/autograd/grad_mode.py - Modify the code under decorate_context fnuction by referring grad_model_modification.png image.
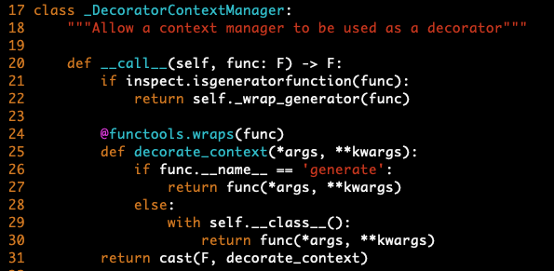
-
Train MSRP by using the following command line.
-
python train.py - The model will be automatically saved.
- It will take at least 5 hours on GeForce RTX 3090.
- For loging training procedure, you can use Weight & Bias (How to initialize it) by setting an argument.
-
python train.py --wandb online
-
-
Evaluate the trained model using evaluate.py.
- Change the model path from the model ID to the path of the trained model, trained_msrp/lb0.01_ap0.3.
-
python evaulate.py trained_msrp/lb0.01_ap0.3

- You can also perform the pretraining.
-
python pretrain_t5.py - If you want to use your pretrained model, then change init_path argument in train.py to the saved directory t5-pretrained/, and run the MSRP.
-
You can tune the hyperparameters of MSRP by using the uploaded sweep file of Weigth & Bias library. Please refer to the official document for more information.
wandb sweep sweep-msrp.yaml wandb agent SWEEP_ID- Update how to train
- Upload outputs
- Upload evaluation code based on output texts
- Update how to tune hyperparameters
If you use this repository for your work, please consider citing our paper:
@inproceedings{hyun-etal-2022-generating,
title = "Generating Multiple-Length Summaries via Reinforcement Learning for Unsupervised Sentence Summarization",
author = "Hyun, Dongmin and Wang, Xiting and Park, Chayoung and Xie, Xing and Yu, Hwanjo",
booktitle = "Findings of the Association for Computational Linguistics: EMNLP 2022",
month = dec, year = "2022",
address = "Abu Dhabi, United Arab Emirates",
publisher = "Association for Computational Linguistics",
url = "https://aclanthology.org/2022.findings-emnlp.214",
pages = "2939--2951",
}