Web crawler and data analizer with web interface. Currently used to gather information about programmer vacancies.
Apparently this program uses mysql server
sudo apt-get install mysql-client mysql-server
How to use it:
- Download statistics info to vacancy database: ./bin/vacan.download
- Run web interface: ./bin/vacan.monitor
- Open http://localhost:8080 in your favorite browser and see results.
This is just fun site project for practicing some new programming techniques, do not expect too much.
- 2 views:
- for all dates and individual vacancies and for tag
- try out tornado
- fix playground
- working as a linux service
- make file support
- automatic deploy
- clean autonomous tests
- 100% test coverage
- web with bootstrap3
- delete old code in R
- delete old code for statistics
- documentation for information tables
- rewrite interface for web
- support of python docs
release date 2015.07.31 - fr
-
Tag system with support of
- mutiple keywords for tag
- X regexp for tag
- X groups of tags
- X separate group for languages, professions, web tech, database tech, personal traits, mobile development
- X Fix java vs javascript bug
-
Show only languages in web
-
Show rounded data
-
Get set of Processed vacancys by VacancyProcessor
-
Able to get subset of all vacancies with specific tags in notebook
-
Plot boxplots of subset in notebook
-
2 views:
- for individual date overall and for tag
- for all dates and individual vacancies and for tag - next rel
-
improve graphics
-
autocomplete for markdown
- invalid html result in no html saved
- if we have no db - show message
add recommender system
- Web interface
- filter by group of tags
- nicer plots
- top menu
- about menu
- statistics about collection
- Rewrite site parser
- Collect from sj.ru.
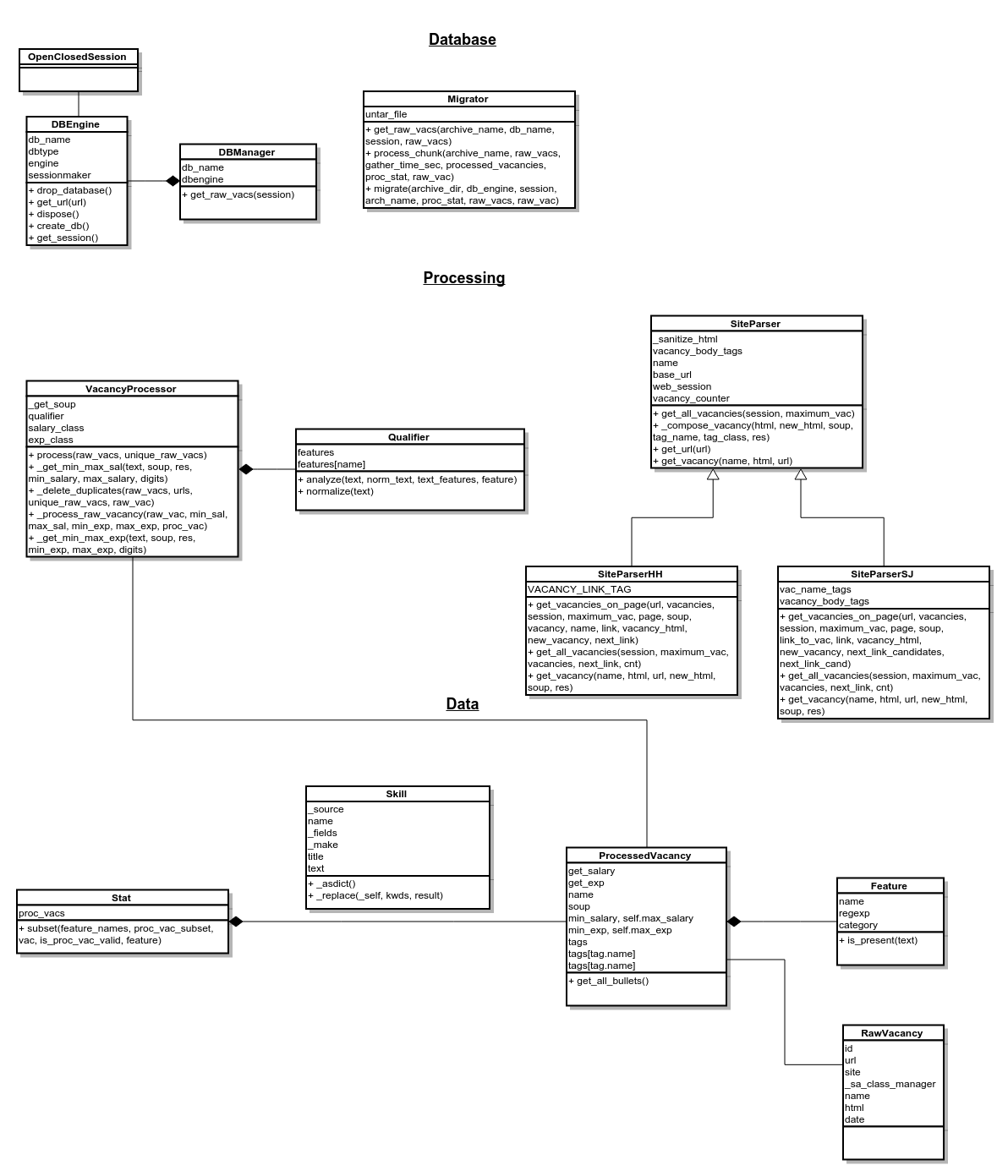
- Plot uml diagramm