KorQuad-Open Baseline Code for KAIST CS492I 2020 Fall
Seonhoon Kim (Naver)
sh run_nsml.shsh run_local.shWe deal with a QA task with a single question and multiple contexts (i.e., paragraphs). One of the most important issues in this type of task is in which paragraph to pick the answer span. Current naive implementation is comparing the probability in a prediction and choosing the paragraph with the largest. Implement a strategy to pick the best answer.
See the codes:
- https://github.com/dongkwan-kim/korquad-open-cs492i/blob/master/open_squad_metrics.py#L412
- https://github.com/dongkwan-kim/korquad-open-cs492i/blob/master/open_squad_metrics.py#L639
- https://github.com/dongkwan-kim/korquad-open-cs492i/blob/master/run_squad.py#L358
NOTE: In the baseline, you can find the huge gap between validation and test performances (f1-score), since the f1-score for the validation is measured per paragraph, and the f1-score for the test is measured per question.
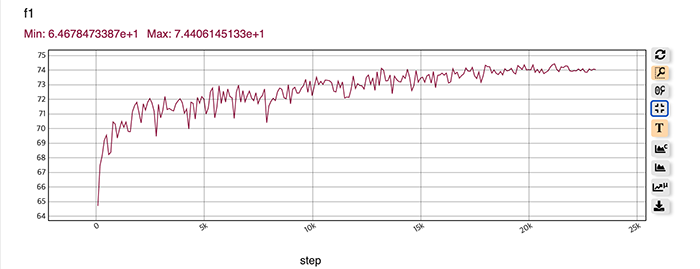
There are multiple contexts, but since there is a memory limit, we cannot include everything in training. The baseline is using first three samples in sequence. Which training samples should we choose to learn the best representation?
See the codes:
Do as much as you want.