The code is written in python, and all networks are implemented using Caffe.
- VRD
- sVG: subset of Visual Genome
- Link
- Images can be downloaded from the website of Visual Genome
- Remarks: eventually I found no time to further clean it. This subset has a manually cleaned list for relationship predicates. The list for objects may need further cleaning, although Faster-RCNN can get a recall@20 around 50%.
- Using our method, you can get the corresponding results reported in the paper on this dataset.
This repo contains three kinds of networks. And all of them get the raw response for predicate based on both appearance cues and spatial cues, followed by a refinement according to responses of the subject, the object and the predicate. The networks are designed for the task of predicate recognition, where ground-truth labels of the subject and the object are provided as inputs. Therefore, in these networks, responses of the subject and the object are replaced with indicator vectors, and only response of the predicate will be refined.
In these networks, the subnet for appearance cues is VGG16, and the subnet for spatial cues consists of three conv layers. And outputs of both subnets are combined via a customized concatenate layer, followed by two fc layers to generate raw response for the predicate.
The customized concatenate layer is used for combining the output of a fc layer and channels of the output of a conv layer, which can be replaced with caffe's Concat layer if the last conv layer in spatial subnet (conv3_p) is equivalently replaced with a fc layer.
The details of these networks are
-
drnet_8units_softmax: it has 8 inference units with softmax function as the activation function.
-
drnet_8units_linear_shareweight: it has 8 inference units with no activation function, and the weights are shared across units.
-
drnet_8units_relu_shareweight: it has 8 inference units with relu function as the activation function, and the weights are shared across units.
The training procedure is component-by-component. Specifically, a network usually contains three components, namely the subnet for appearance (A), the subnet for spatial cues (S), and the drnet for statistical dependencies (D). In training, we train the network as follow:
- train A in isolation
- train S in isolation
- train A + S in isolation, with weights initialized from previous steps
- train A + S + D jointly, with weights initialized from previous steps
Each step we use the same loss, and we use dropout to avoid overfit.
| Networks | Recall@50 | Recall@100 |
|---|---|---|
| drnet_8units_softmax | 75.22 | 77.55 |
| drnet_8units_linear_shareweight | 78.57 | 79.94 |
| drnet_8units_relu_shareweight | 80.86 | 81.83 |
- lib/: python layers, as well as auxiliary files for evaluation
- prototxts/: training and testing prototxts
- tools/: python codes for preparing data and evaluation
- snapshots/: pretrain models
- Download the dataset VRD
- Preprocess the dataset using tools/preprare_data.py
- Download one pretrain model in snapshots/
- Finetune or Evaluate using corresponding prototxts in prototxts/
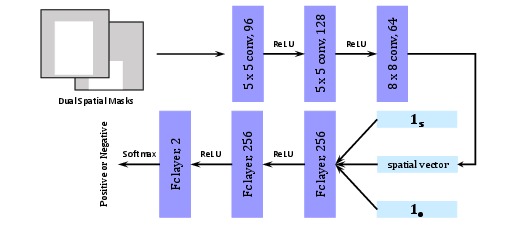
To train this network, we randomly sample pairs of bounding boxes (with labels) from each training image, treating those with 0.5 IoU (or above) with any ground-truth pairs (with same labels) as positive samples, and the rest as negative samples.
If you use this code, please cite the following paper(s):
@article{dai2017detecting,
title={Detecting Visual Relationships with Deep Relational Networks},
author={Dai, Bo and Zhang, Yuqi and Lin, Dahua},
booktitle={Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition},
year={2017}
}
This code is used for research only. See LICENSE for details.