Big Data Project: Real-Time Twitter Sentiment Analysis Using Kafka, Spark (MLLib & Streaming), MongoDB and Django.
This repository contains a Big Data project focused on real-time sentiment analysis of Twitter data (classification of tweets). The project leverages various technologies to collect, process, analyze, and visualize sentiment data from tweets in real-time.
The project is built using the following components:
-
Apache Kafka: Used for real-time data ingestion from Twitter DataSet.
-
Spark Streaming: Processes the streaming data from Kafka to perform sentiment analysis.
-
MongoDB: Stores the processed sentiment data.
-
Django: Serves as the web framework for building a real-time dashboard to visualize the sentiment analysis results.
-
chart.js & matplotlib : for plotting.
-
This is the project plan :
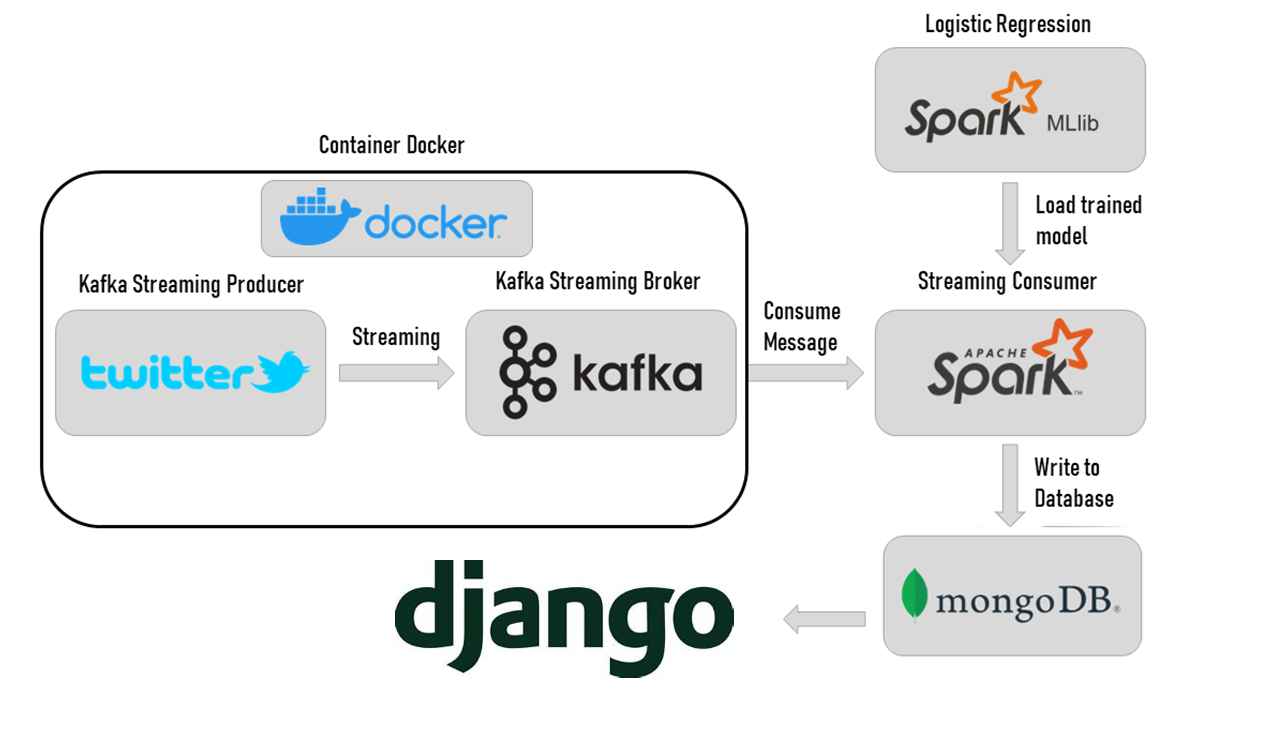

- Real-time Data Ingestion: Collects live tweets using Kafka from the Twitter DataSet.
- Stream Processing: Utilizes Spark Streaming to process and analyze the data in real-time.
- Sentiment Analysis: Classifies tweets into different sentiment categories (positive, negative, neutral) using natural language processing (NLP) techniques.
- Data Storage: Stores the sentiment analysis results in MongoDB for persistence.
- Visualization: Provides a real-time dashboard built with Django to visualize the sentiment trends and insights.
In This Project I'm using a Dataset (twitter_training.csv and twitter_validation.csv) to create pyspark Model and for create live tweets using Kafka. Each line of the "twitter_training.csv" learning database represents a Tweet, it contains over 74682 lines;
The data types of Features are:
- Tweet ID: int
- Entity: string
- Sentiment: string (Target)
- Tweet content: string
The validation database “twitter_validation.csv” contains 998 lines (Tweets) with the same features of “twitter_training.csv”.
This is the Data Source: https://www.kaggle.com/datasets/jp797498e/twitter-entity-sentiment-analysis
- Django-Dashboard : this folder contains Dashboard Django Application
- Kafka-PySpark : this folder contains kafka provider and pyspark streaming (kafka consumer).
- ML PySpark Model : this folder contains the trained model with jupyter notebook and datasets.
- zk-single-kafka-single.yml : Download and install Apache Kafka in docker.
- bigdataproject rapport : a brief report about the project (in french).
To run this project, you will need the following installed on your system:
- Docker (for runing Kafka)
- Python 3.x
- Apache Kafka
- Apache Spark (PySpark for python)
- MongoDB
- Django
-
Clone the repository:
git clone https://github.com/drisskhattabi6/Real-Time-Twitter-Sentiment-Analysis.git cd Real-Time-Twitter-Sentiment-Analysis -
Installing Docker Desktop
-
Set up Kafka:
- Download and install Apache Kafka in docker using :
docker-compose -f zk-single-kafka-single.yml up -d
-
Set up MongoDB:
- Download and install MongoDB.
- It is recommended to install also MongoDBCompass to visualize data and makes working with mongodb easier.
- Download and install MongoDB.
-
Install Python dependencies:
- To install pySpark - PyMongo - Django ...
pip install -r requirements.txt
Note : you will need MongoDB for Running the Kafka and Spark Streaming application and for Running Django Dashboard application.
- Start MongoDB:
- using command line :
sudo systemctl start mongod
- then use MongoDBCompass (Recommended).
-
Change the directory to the application:
cd Kafka-PySpark -
Start Kafka in docker:
- using command line :
docker exec -it <kafka-container-id> /bin/bash
-
or using docker desktop :
-
Run kafka Zookeeper and a Broker:
kafka-topics --create --topic twitter --bootstrap-server localhost:9092 kafka-topics --describe --topic twitter --bootstrap-server localhost:9092
-
Run kafka provider app:
py producer-validation-tweets.py
-
Run pyspark streaming (kafka consumer) app:
py consumer-pyspark.py


this is an img of the MongoDBCompass after Running the Kafka and Spark Streaming application :

-
Change the directory to the application:
cd Django-Dashboard -
Creating static folder:
python manage.py collectstatic
-
Run the Django server:
python manage.py runserver
-
Access the Dashboard: Open your web browser and go to
http://127.0.0.1:8000to view the real-time sentiment analysis dashboard.


- Django Dashboard get the data from MongoDb DataBase.
- the User can classify his owne text in
http://127.0.0.1:8000/classifylink. - in the Dashboard, There is a table contains tweets with labels.
- in the Dashboard, There is 3 statistics or plots : labels rates - pie plot - bar plot.
- Prof. Yasyn El Yusufi
Abdelmalek Essaadi University - Faculty of Sciences and Technology of Tangier
- Master: Artificial Intelligence and Data Science
- Module: Big Data
-
By following the above instructions, you should be able to set up and run the real-time Twitter sentiment analysis project on your local machine. Happy coding!
-
Feel free to explore the project and customize it according to your requirements. If you encounter any issues or have any questions, don't hesitate to reach out!