In this lesson, you'll be introduced to the multiple linear regression model. We'll start with an introductory example using linear regression, which you've seen before, to act as a segue into multiple linear regression.
You will be able to:
- Compare and contrast simple linear regression with multiple linear regression
- Interpret the parameters of a multiple regression
You have previously learned about simple linear regression models. In these models, what you try to do is fit a linear relationship between two variables. Let's refresh our memory with the example below. Here, we are trying to find a relationship between seniority and monthly income. The monthly income is shown in units of $1000 USD.
import numpy as np
import matplotlib.pyplot as plt
%matplotlib inline
# generate synthetic seniority and income data
np.random.seed(1234)
sen = np.random.uniform(low=18, high=65, size=100)
income = np.random.normal(loc=(sen/10), scale=0.5)
sen = sen.reshape(-1, 1)
# plot data and y = 0.1x regression line
fig, ax = plt.subplots(figsize=(7, 5))
fig.suptitle('seniority vs. income', fontsize=16)
ax.scatter(sen, income)
ax.plot(sen, sen/10, c='black')
ax.set_xlabel('seniority', fontsize=14)
ax.set_ylabel('monthly income', fontsize=14);
If you are able to set up an experiment with a randomized control group and intervention group, that is the "gold standard" method for statistical controls. If you see a spurious result from that kind of analysis, it is most likely due to bad luck rather than anything wrong with your setup. An experiment doesn't necessarily explain the underlying mechanism for why a given independent variable impacts a given dependent variable, but you can be more confident that the causal relationship exists.
However if you are analyzing a "naturally-occurring" dataset of non-experimental observations, more sophisticated domain knowledge and models are needed to help you interpret the data. You have a much higher risk of spurious correlations -- seemingly causal relationships between variables that are not legitimately related:

There are two kinds of spurious correlations:
- Variables that seem to be related due to random (bad) luck
- Variables that are not directly related, but are both impacted by confounding variables
The statistical significance tests we use are intended to flag the first type of spurious correlation. There is no way to prevent them completely, but you can use a smaller alpha value (set a lower tolerance for false positives) if you want to reduce the risk of them.
For the second type of spurious correlation, we can work around this issue by identifying the confounding variable and including it in our model.
A classic confounding variable example is:
-
$y$ : number of shark attacks -
$x$ : ice cream sales
We might perform a regression analysis and find that there is a statistically significant relationship between ice cream sales and shark attacks! But how would ice cream sales be causing shark attacks? Well, the ice cream probably isn't actually causing them. Instead, a higher temperature is probably causing people to buy more ice cream, as well as causing people to go to the beach and have run-ins with sharks.
If we collect temperature data and create a new model:
-
$y$ : number of shark attacks -
$x_1$ : ice cream sales -
$x_2$ : daily high temperature
Then we would probably find that daily high temperature actually explains this target variable, and ice cream sales are no longer statistically significant.
Let's return to our monthly income example.
Our original model was essentially:
Then if we added in years of education as a predictor, it would look something like this:
Instead of having one slope and one intercept, we now have two slopes and an intercept. But where do those slope values come from?
Essentially, each variable you add is adding a dimension to the matrix of X values. So instead of finding the best-fit for a line like in simple linear regression, now we're finding the best-fit for a plane:
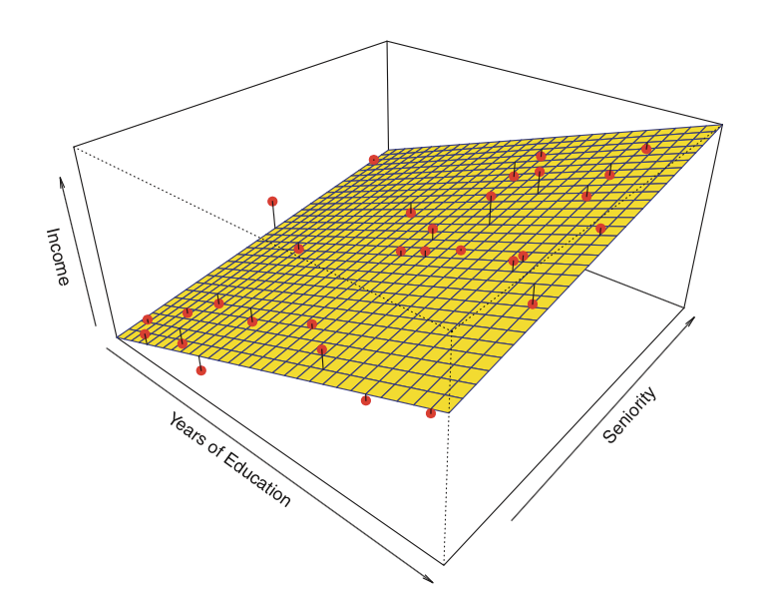
$\mathrm{slope}\mathrm{seniority}$ represents the slope in the direction of the axis associated with seniority, and $\mathrm{slope}\mathrm{education}$ represents the slope in the direction of the axis associated with years of education.
To write this with more standard variable names, we have:
| Variable | Meaning in This Context |
|---|---|
| predicted monthly income | |
| predicted value of monthly income if both seniority and years of education are 0* | |
| seniority | |
| predicted change in monthly income associated with an increase of 1 in seniority | |
| years of education | |
| predicted change in monthly income associated with an increase of 1 in years of education |
*As more variables are added, the intercept can get increasingly nonsensical/hard to interpret.
Note that we would not expect
an increase of 1 in
independent variableis associated with a change ofslopeindependent variable,
you may want to add the phrase "all else being equal", or "controlling for education", to indicate that these are not the only two variables involved in your analysis.
Multiple linear regression models are not restricted to two independent variables. You can theoretically add an indefinite number of variables. Once we move beyond two predictors, multiple linear regression generates a best-fit hyperplane.
When thinking of lines and slopes statistically, slope parameters associated with a particular predictor
where
Each of these additional predictors is adding another dimension to the analysis, so creating visualizations of models with more than two predictors becomes very difficult. So instead we will typically use partial regression plots that represent one predictor at a time. This page from StatsModels shows some examples.
Congratulations! You have gained an initial understanding of a multiple linear regression model. Multiple regression models add additional dimensions of independent variables, each with their own slopes. This can be helpful for identifying confounding variables and avoiding spurious associations, although randomized controlled experiments are still the "gold standard". Parameter interpretation for multiple regression models is similar to interpretation for simple regression, except that there are more slopes to interpret and the intercept is when all predictors are zero, not just when a single predictor is zero.