20NewsGroup
The goal of the project is to implement the GBDT classifier in 20newsgroup dataset. We want to check the performance of GBDT on 20newsgroup dataset, the evaluation indicators include precision, recall and F1 score.
Dataset
The 20 Newsgroups data set is a collection of approximately 20,000 newsgroup documents, partitioned (nearly) evenly across 20 different newsgroups. To the best of my knowledge, it was originally collected by Ken Lang, probably for his Newsweeder: Learning to filter netnews paper, though he does not explicitly mention this collection. The 20 newsgroups collection has become a popular data set for experiments in text applications of machine learning techniques, such as text classification and text clustering.
The dataset is found here https://archive.ics.uci.edu/ml/machine-learning-databases/20newsgroups-mld/20_newsgroups.tar.gz.
Results
There are 11314 documents in the training set and 7532 documents in the testing set.
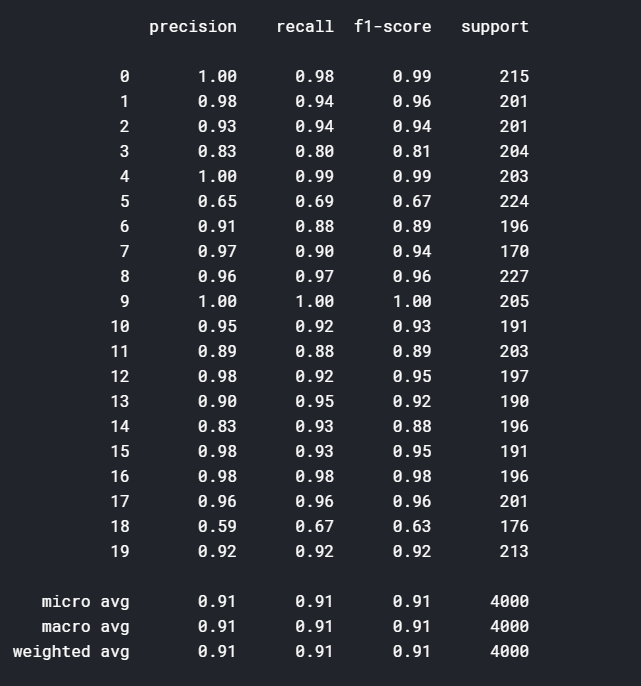
First, I download the raw 20newsgroups dataset, then preprocess the dataset, split the train set and test set. Finally, I construct the GBDT model using LightGBM framework, set the train set, validation set and test set. Through turning lgb parameters, the final test results are shown as below:
Discussion
In fact, in the absence of semantic prior information, it's hard to get both above 95 percent precision and 95 percent recall using traditional machine learning methods.
According to my personal data access, it could happen when there is an external semantic input (mainly refers to trained word vector, such as word2vec, glove embedding) and using the MLP or CNN network. However, as I am more familiar with the CV direction and lack of knowledge in the field of NLP, the above NN model has not been completed